
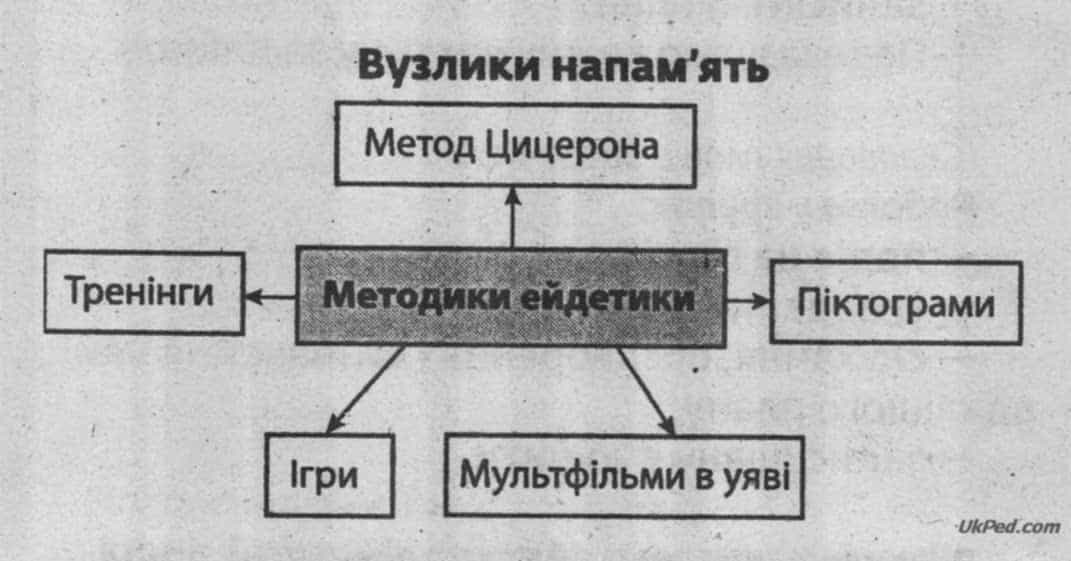
суть техники «Римская комната» для запоминания. Метод мнемотехники на основе пространственного воображения. Упражнения для запоминания текста и тренировки памяти
Для того чтобы много знать, надо много читать и запоминать. Но не каждый человек может похвастаться хорошей памятью. Существует много способов для ее развития. Одним из них является метод Цицерона или «римская комната».
История возникновения метода
Один из самых знаменитых государственных деятелей Римской империи Марк Туллий Цицерон, живший в 106-43 годах до нашей эры, прославился своим непревзойденным ораторским талантом. При этом он обладал поразительной памятью, воспроизводя в своих речах множество дат, имен, фактов, исторических событий, не пользуясь при этом никакими записями.
Способ запоминания текста «римская комната» (метод Цицерона) назван в его честь, но придуман был не им, а гораздо раньше.
Корни данной мнемотехники уходят в Древнюю Грецию, где так же, как и Цицерон, ею успешно пользовался поэт Симонид. Согласно легенде, однажды произошло обрушение здания, где проходил большой пир. Симониду, который там присутствовал, удалось выбраться из-под обломков живым и почти невредимым. Он по памяти рассказал людям, разбирающим завалы, где находился каждый из гостей в момент обрушения. Это помогло родственникам найти все тела погибших и похоронить их согласно обычаям.
В настоящее время можно услышать и другие названия такой техники запоминания. Например, метод мест или система комнаты.
Смысл
Тренировка памяти по методу Цицерона происходит на основе пространственного воображения. Что это значит? Представьте себе все те предметы домашней обстановки и уличные объекты, которые вы постоянно видите. Все это зрительные образы, формирующие ваши естественные ассоциации на уровне подсознания. Связи между этими образами формируются в нашей голове автоматически и не требуют работы над их запоминанием.
Этот факт как раз и определяет метод Цицерона, суть которого основана на принципе запоминания последовательности и многократном повторении уже давно знакомых нам образов.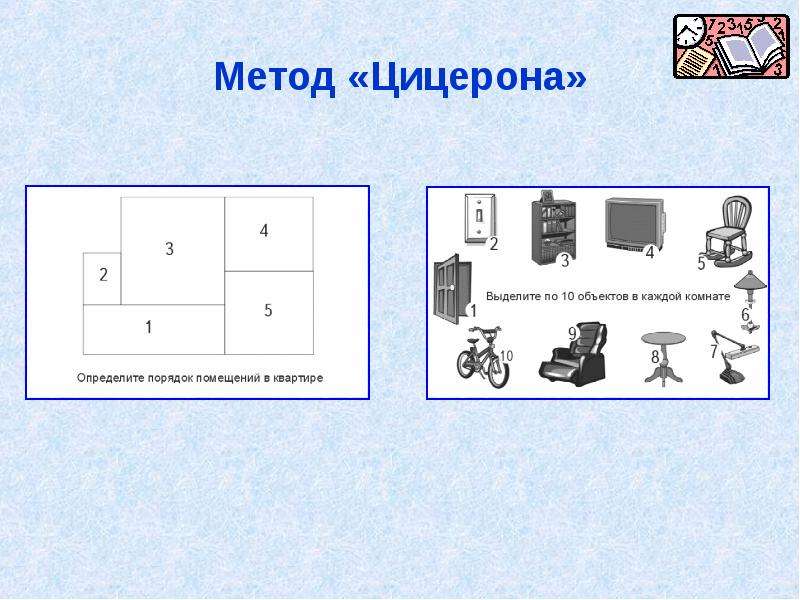 То есть ту информацию, которую нам надо хорошо запомнить и потом воспроизвести, надо мысленно распределить по хорошо знакомым нам объектам (например, по предметам мебели в офисном кабинете, в спальне или гостиной) в четко заданном порядке. Когда вы вспомните это помещение, перед вами без труда возникнет необходимая информационная картина, и вам останется лишь воспроизвести ее.
То есть ту информацию, которую нам надо хорошо запомнить и потом воспроизвести, надо мысленно распределить по хорошо знакомым нам объектам (например, по предметам мебели в офисном кабинете, в спальне или гостиной) в четко заданном порядке. Когда вы вспомните это помещение, перед вами без труда возникнет необходимая информационная картина, и вам останется лишь воспроизвести ее.
Одно и то же помещение можно использовать для запоминания неограниченное количество раз. Такой способ дает возможность запомнить не просто отдельные слова и фразы, а объемные информативные тексты. Использовать данную мнемотехнику можно в любых условиях, важно сконцентрироваться и не отвлекаться на внешние раздражители. Когда же придет время для озвучивания нужной информации, представьте себе то помещение, в котором вы работали над запоминанием, и процесс пойдет как по маслу.
Такой метод очень полезен не только для совершенствования памяти, но и для общего развития мышления, а также умения сосредотачиваться на необходимой информации и проводить анализ окружающей обстановки.

Как применить на практике?
Метод Цицерона включает в себя разные упражнения. Для начала необходимо мысленным взором рассмотреть изнутри свое жилище или кабинет. Если вы выбрали для тренировки памяти свое жилье, то мысленно распределите последовательность всех его помещений по периметру в зависимости от планировки.
- прихожая;
- уборная;
- ванная;
- кладовая;
- гостиная;
- столовая;
- кухня;
- спальня;
- детская;
- лоджия (или балкон).
Затем сконцентрируйтесь на первом помещении и осмотрите мысленно все объекты, находящиеся в нем. Делать это желательно всегда в одном направлении, лучше по часовой стрелке.
Потом переходите к следующему в очереди помещению и обследуйте его таким же образом. И так далее.
И так далее.
- Если вы впервые пробуете работать по методу Цицерона, то для начала сконцентрируйте свое внимание только на одной комнате. На остальные будете переходить потом, когда уже хорошо натренируетесь. А пока выберите, например, прихожую и выделите в ней несколько стационарно расположенных предметов.
- Необязательно использовать только знакомые помещения зданий. Можно обратить свое внимание на уличные объекты, которые вы часто встречаете. Например, магазины, остановки, кафе, школы, детские сады и другие подобные места.
- После подготовки «римской комнаты» в своем сознании переходите к размещению в ней той информации, которую вам требуется запомнить. Например, вы хотите запомнить перечень товаров, которые надо купить в магазине, и вы выбрали для этого прихожую. При входе в нее слева вы видите шкаф. Положите на полки хлеб и молоко, а на перекладину с плечиками повесьте картошку и стиральный порошок.
 На тумбочке разложите чай, сахар и печенье. И тому подобное.
На тумбочке разложите чай, сахар и печенье. И тому подобное.
 На тумбочке разложите чай, сахар и печенье. И тому подобное.
На тумбочке разложите чай, сахар и печенье. И тому подобное.Когда вы войдете в магазин, мысленно представьте прихожую с ее мебелью, и необходимая информация четко прорисуется в вашей голове. Если вам требуется запомнить большой объем информации, который вряд ли поместится на объектах одной комнаты, то смело переходите в соседние помещения.
Для того чтобы запомнить какой-либо конкретный текст, подготовиться к публичному выступлению, работать с методом Цицерона надо следующим образом:
- прочитать текст и понять, о чем он;
- разбить его на несколько смысловых частей;
- каждую из этих частей запомнить в отдельном помещении своего жилья;
- далее вслух произнести всю речь, последовательно воспроизводя в памяти образы тех помещений, в которых были запомнены части текста.
Рекомендации
Подобные тренировки рекомендуется проводить регулярно, так как это позволит усовершенствовать такой важный инструмент сознания, как память.
Перед тем как вы приступите к работе с запоминанием информации, лучше реально обойти те помещения, которые будут выполнять для вас роль «римской комнаты». Представляемые объекты (например, предметы мебели) не должны повторяться, одинаковыми могут быть только названия этих объектов (шкаф, стол, тумбочка, комод и прочее). А сами объекты должны быть разными (например, шкаф в прихожей и шкаф в спальне, стол в кухне и стол в кабинете, тумбочка в детской и тумбочка в спальне). А также можно разделить один объект на несколько зон (частей). Скажем, комод можно не считать одним объектом, на который мы будем «помещать» единицы запоминаемой информации, а разделить его по количеству ящиков, находящихся в нем.
Немалую роль в улучшении процесса запоминания играют органы чувств. Для большей эффективности применения метода Цицерона нужно прикреплять единицы запоминаемой информации к объектам ярко освещенных комнат. А также можно изменять размеры запоминаемых предметов или образов (например, мышь представлять размером со слона и наоборот), придумывать интересные и подвижные переходы от образа к образу, от объекта к объекту. Например, представить диван более яркого цвета, чем он есть на самом деле, а соседнее кресло ритмично пританцовывающим.
Для большей эффективности применения метода Цицерона нужно прикреплять единицы запоминаемой информации к объектам ярко освещенных комнат. А также можно изменять размеры запоминаемых предметов или образов (например, мышь представлять размером со слона и наоборот), придумывать интересные и подвижные переходы от образа к образу, от объекта к объекту. Например, представить диван более яркого цвета, чем он есть на самом деле, а соседнее кресло ритмично пританцовывающим.
Главным преимуществом методики «римская комната» является ее быстрое освоение, которое происходит буквально за несколько тренировок.
Метод цицерона запоминание. «Мнемотехника» и «изучение иностранного языка» несовместимые понятия?! Давайте разберемся. Запоминание методом «цицерона»
В современном мире ежедневно человек сталкивается с различными объемами информации, планами, задачами. Множество людей выступают перед другими людьми, в ходе которого должны красиво и правильно излагать мысли, направлять или вести людей, заниматься обучением и при этом вызывать интерес. Увы, не каждому из нас под силу моментально и качественно вносить в память необходимые данные. Но к счастью, существуют техники для запоминания любого объема и сложности информации. Данные методы называются мнемоника, что в переводе с древнегреческого означает искусство запоминать.
Множество людей выступают перед другими людьми, в ходе которого должны красиво и правильно излагать мысли, направлять или вести людей, заниматься обучением и при этом вызывать интерес. Увы, не каждому из нас под силу моментально и качественно вносить в память необходимые данные. Но к счастью, существуют техники для запоминания любого объема и сложности информации. Данные методы называются мнемоника, что в переводе с древнегреческого означает искусство запоминать.Так, в результате развития памяти мы имеем возможность не только плавно и обстоятельно излагать информацию, т.е. обладать навыками ораторства, но также обладать искусством профессионально ее запоминать, при этом объем и сложность данных может быть любая.
Возможно, в это трудно поверить. Но мы знаем один главный секрет для успешного – это изменение каких-либо данных в картинки (образы), а потом воспроизведение ее в памяти.
Существует множество техник, но в этой статье мы рассмотрим методику запоминания от Цицерона, а также приведем несколько простых, но действенных методов запоминания из мнемотехники.
Причины плохой памяти
Прежде, чем переходить к практической стороне, необходимо понять, что лежит в первопричине плохо развитой памяти.
Отметим, что память у каждого человека разная, и она является избирательной, т.е. для кого-то легко будет запомнить таблицу умножения, прочтя ее один раз, но при этом имя знакомого тот же человек забывает практически сразу. Другие люди эффективно применяют зрительный вид памяти, но простые правила русского языка вспоминают со скрипом. Отчего так происходит?
Существует 5 причин нарушения памяти:
- Сниженный или отсутствующий интерес. Это наиболее популярная причина. Сложно вспомнить то, что не интересно и не вызывает желание развиваться в этой области. Для того чтобы запомнить какую-то информацию, необходимо затратить силы и время. Если человек не любит поэзию, то упражнения по заучиванию стихов, будет равносильно подвигу.
- Низкая концентрация, невнимание, отсутствие навыков управления вниманием. Сегодня огромный поток информации льется каждый день на человека. Ввиду этого мы вникаем в данные поверхностно, не понимая сути и, порой, не стремясь реализовать полученную информацию на практике. И это становится привычкой. Кстати, одновременное исполнение нескольких задач также влияет на нашу продуктивность.
- Отсутствие навыков запоминания. Хорошая память не дается нам от рождения, это навык, который нужно развивать. Ниже будут представлены методики, которые позволят развивать эту способность.
- Низкий уровень кислорода, авитаминоз, неправильное питание. Вывод напрашивается сам – принимать только здоровую еду, систематически заниматься физическими нагрузками и прогулки на свежем воздухе.
- Депрессивное состояние. Это стало бичом современного человека. И при таком самочувствии вряд ли получится не то что запомнить новую информацию, но и воспроизвести старую. Поэтому рекомендуем приобщиться к активной жизненной позиции и уметь переживать такие состояния.
 Сегодня огромный поток информации льется каждый день на человека. Ввиду этого мы вникаем в данные поверхностно, не понимая сути и, порой, не стремясь реализовать полученную информацию на практике. И это становится привычкой. Кстати, одновременное исполнение нескольких задач также влияет на нашу продуктивность.
Сегодня огромный поток информации льется каждый день на человека. Ввиду этого мы вникаем в данные поверхностно, не понимая сути и, порой, не стремясь реализовать полученную информацию на практике. И это становится привычкой. Кстати, одновременное исполнение нескольких задач также влияет на нашу продуктивность.
Теперь можно переходить непосредственно к упражнениям для лучшего запоминания информации. Безусловно, мы представим лишь некоторые методики, которые заработали популярность за счет их эффективности. Однако еще раз подчеркнем, что каждый человек индивидуален, поэтому нужно осознанно и внимательно отвечать на вопросы тестов и подбирать комплекс упражнений. Только при таком подходе результат будет эффективным.
Прогулка по «Римской комнате», или методика Цицерона
Известность Цицерона распространялось по древнему Риму и миру со скоростью света. Его талант ораторского искусство до сих пор ставят в пример современникам. Он обладал уникальным талантом – выступал перед огромнейшей аудиторией, не используя полсказки, записи и иные материалы. Однако был ли это дар или же кропотливый труд над развитием навыков запоминания?
Именно его методику мы рассмотрим в следующих разделах, т.к. он является самым древним методом запомнить любую информацию. Если вы овладеете им, то сможете легко удерживать даты, цифры, слова, фразы и иную информацию. Однако стоит помнить, что главным условием достижения результата – систематический труд, т.е. заниматься нужно каждый день.
Однако стоит помнить, что главным условием достижения результата – систематический труд, т.е. заниматься нужно каждый день.
Смысл методики
Методы запоминания от Цицерона обладают конкретным смыслом, заключающийся в создании матрицы образов, которые помогают запомнить большие объемы данных, а не только один фрагмент. Первое, что нужно сделать, это сформировать систему, в которой будут строиться образы.
Презентация на тему: «Основы метода ассоциаций»
Этой системой может быть что угодно:
- помещение;
- участок;
- тропинка;
- знакомая обстановка и т.п.
Если работа происходит с комнатой, то следует мысленно вспомнить все предметы, которые находятся в ней. Желательно в упорядоченном характере. К примеру, по движению часовой стрелки или от одной стены до другой. Не стоит усложнять задание при создании системы для ассоциаций, выбирайте то помещение, что вами хорошо изучено, тогда следующие уровни не вызовут затруднений.
Некоторые авторы предлагают создание кардинально нового помещения, т.е. человек мысленно создает новое жилище, делает планировку и расставляет мебель. Это будет являться плодом вашей фантазии, а значит справится с задачей вам будет легче.
Работая с системой образов «тропинка» можно формировать множество образов, т.к. у такого пути нет конца. В этом случае, Вам нужно по мере движения по системе, перебирать предметы, которые будут встречаться: хижины, камни, люди, цветы, лавки, животные и др.
В качестве системы можно выбрать абсолютное любое удобное место, важное условие – корректно выполнить разбивку на отдельные образы.
Перед началом практики, необходимо четко определиться со схемой, по которой вы будет обходить выбранную систему. Движения не должны быть хаотичными – вы должны упорядочить обход комнат, чтобы не испортить все, что так долго «собиралось».
Важный момент: выберите определённую последовательность движения и задайте тем предметам, что есть в системе ключевые фрагменты речи выступления или презентации.
После того, как Вы создали систему, наполнили ее предметами и задали ключи, следует несколько раз обойти систему (комнату, дорогу…) и воспроизвести заданные критерии. Это же необходимо сделать непосредственно перед презентацией. Цицерон перед каждым выступлением также обходил комнаты и воспроизводил образы.
По истечению определенного времени, каждый кто использовал данную технику, сможет активизировать свою память в нужный момент, прибегая к удобной матрице образов.
Пример использования
Давайте рассмотрим на наглядном примере, как использовать методику Цицерона по запоминанию информации.
- Возьмем десять слов, необходимые для запоминания (цифры, события, тезисы выступления, иностранные слова). К примеру, это будут следующие слова: штора, открытка, птица, сметана, упаковка, рот, фен, бубен, книга, динамик. Нужно задать их на конкретные предметы выбранной системы (например, комната). Далее, приступаем к следующему уровню задания.
- Возьмите лист, карандаш и запишите все объекты, находящиеся в комнате. Не важно сколько их будет. Главное, что они создают «ниши» для нашей матрицы. Помимо этого, следует запомнить их местонахождение и в каком порядке они находятся. Приблизительный список предметов в комнате: окно, диван, шкаф, телевизор, пуф, торшер, кресло, этажерка, полка, рояль, печь, палас и другое.
- Третьем этом является соединение слов из п.2 с местами со списком тезисов для запоминания.
 Не важно сколько их будет. Главное, что они создают «ниши» для нашей матрицы. Помимо этого, следует запомнить их местонахождение и в каком порядке они находятся. Приблизительный список предметов в комнате: окно, диван, шкаф, телевизор, пуф, торшер, кресло, этажерка, полка, рояль, печь, палас и другое.
Не важно сколько их будет. Главное, что они создают «ниши» для нашей матрицы. Помимо этого, следует запомнить их местонахождение и в каком порядке они находятся. Приблизительный список предметов в комнате: окно, диван, шкаф, телевизор, пуф, торшер, кресло, этажерка, полка, рояль, печь, палас и другое.Мнемотехники для быстрого запоминания
Методы запоминания по Цицерону хороши, но существуют и другие приемы мнемотехники:
- Рифмуйте данные. Создание стихотворной формы позволяет легче воспринимать информацию и, соответственно, воспроизводить её.
- Создавайте фразы из начальных букв информации.
- Связка. Данная техника предполагает установление связи полученных данных с эффектным образом. К примеру, нужно запомнить имена присутствующих на собрании –представьте, что каждый из них герой какой-то сказки. Для более детальной связки, наделите персонажей каким-то прилагательным. Например, «кот в сапогах» — огромный кот в кедах.
- Зацепки. Суть метода в замене цифровых значений на предметы. Допустим, 0 – ручка, 2 – кот, 3 – баран и т.д.
 Например, «кот в сапогах» — огромный кот в кедах.
Например, «кот в сапогах» — огромный кот в кедах.Какой именно метод подойдет именно Вам, вы не сможете узнать, пока не попробуете. Выберите оптимальный вариант и тренируйтесь каждый день.
Невзирая на технику, которую вы выберете, важно вникнуть в суть метода и применять его так часто, как можно. Профессионала сферы мнемоники поделились секретами работы по методу Цицерона:
- Нужно применять только интересные связи, насыщенные эмоциями. Помните, что обыденное и неинтересное быстро забывается. Используйте парадоксы, сатиру и юмор при создании собственной матрицы.
- Применяйте эротические образы. Не секрет, что именно такие образы особенно ярко поступают в наш мозг в виде сигналов. Кстати, маркетологи уверяют, что рекламные плакаты с красивой сексуальной девушкой воспринимаются и запоминаются лучше.
- Изменяйте характеристики объектов на тропе/помещении/местности. К примеру, окно пусть будет воздушным, а стул – колючим.
- Парадоксируйте характеристики объектов. Не кладите пижаму в шкаф, а засовывайте шкаф в пижаму.
- Все ориентиры на себя: тетрадь несите в кармане, привяжите телевизор к руке.
- Изменяйте форму и размер предметов. Как в примере со шкафом и пижамой.
 К примеру, окно пусть будет воздушным, а стул – колючим.
К примеру, окно пусть будет воздушным, а стул – колючим.В результате у вас должен получится следующий мысленный путь (повесть), как пример:
Открыв окно, я обратила внимание на ШТОРУ, застрявшую в створке окна. Далее, я заметила раскиданные ОТКРЫТКИ на диване, они были влажные. На шкафу стояла абрикосовая СМЕТАНА, в ней сидела ПТИЦА. На телевизоре лежала УПАКОВКА, а в ней сидел щенок, который разевал РОТ. К лапе его был привязан ФЕН, стоящий на БУБНЕ. На пуфе стояла маленькая КНИГА с изображением полуобнаженной эротической брюнеткой, в ногах которой стоял ДИНАМИК.
Для успешного воспроизведения по методу Цицерона, следует еще раз сделать обход выбранной системы и убрать вышеупомянутые объекты. Просто? Конечно. Однако здесь требуется вдумчивое изучение тех слов, что вы уже запомнили. Затем, проделайте самостоятельно, не используя подсказки. Мы верим, что у Вас всё получится!
Однако здесь требуется вдумчивое изучение тех слов, что вы уже запомнили. Затем, проделайте самостоятельно, не используя подсказки. Мы верим, что у Вас всё получится!
Преимущества работы с памятью
Главными достоинствами вышеперечисленных методов является простота и оперативность усвоенной информации.
Спусти несколько практик, человек сможет полноценно использовать выбранную схему и совершенствовать свою память. Помимо прочего, эти методики позволяют запоминать информацию любого типа при подготовке к презентации, лекции, тренингу, семинару и даже при международном выступлении.
Если вы уже знаете ту аудиторию, перед которой нужно выступить, то она может стать отличной матрицей для создания образов. При этом легкость обусловлена тем, что нет необходимости запоминать большой объем ассоциаций, который может рухнуть по причине отсутствия какой-то детали. К примеру, при необходимости вспомнить конкретную фразу, человек может легко её воспроизвести, вспомнив, к чему он привязал фен, а, следовательно, закончить мысль.
Конечно, есть и другие методы запоминания стихом, цифр и дат, но о них мы будем вести речь в других разделах нашего познавательного и развивающего портала.
Список слов
Рассмотрим возможность использования метода Цицерона или как его еще называют метода дорог для запоминания последовательности слов. Если вы заранее подготовили «дорогу» или «матрицу образов» то можете начинать упражнение.
Как запоминить?
Запоминание списка слов с помощью метода Цицерона заключается в расставлении слов по ключевым местам вашей дороги. Вы берете первое слово и создаете ассоциацию с первым образом вашей матрицы. Затем создаете ассоциацию второго запоминаемого слова с вторым образом вашей матрицы. Этот процесс нужно продолжить до конца, пока не закончится список слов, который нужно запомнить. Если образы в вашей матрице закончились быстрее, то к этой матрице нужно присоединить другую матрицу и продолжить запоминание.
Как вспомнить?
Воспроизведение запомненной информации очень похоже на то, как это делалось в упражнении «Пары слов»: вам известно одно из слов, нужно мысленно воспроизвести образ соответствующий паре слов, чтобы вспомнить второе слово. Затем перейти к следующему слову.
Затем перейти к следующему слову.
Тройки слов
Зачем это нужно?
В данном упражнении вам нужно будет запоминать по методу Цицерона уже не последовательность слов, а последовательность троек слов. Зачем нужно запоминать тройки слов? Дело в том, что очень часто приходится запоминать информацию, в которой каждый запоминаемый элемент требует для запоминания несколько параметров, т.е. является не отдельным образом, а блоком, состоящим из нескольких образов или ключевых слов. Этот блок и ассоциируется с соответствующим образом вашей матрицы.
Например, если нужно запомнить римских императоров, то неплохо бы кроме их имен запомить еще и годы рождения, смерти и правления. При запоминании таблицы Менделеева нужно запомнить не только название элемента, но и его обозначение, атомную массу и некоторые другие характеристики. Также необходимость запоминать групповые образы требуется при запоминании текстов, когда часто не удается выделить основную мысль участка текста в виде одного образа и приходится его группировать из нескольких.
Запоминание троек
Цель упражнения запомнить не просто слова, а набор слов. Наборы, которые вам предоставляются содержат ровно по три слова. В реальной жизни такое редко случается, но главное понять принцип и потом уже несложно будет создавать сложные образы. Обычно приходится иметь дело со списком от двух до пяти слов. Из этого набора вам нужно составить единый образ и затем создать ассоциацию с очередным местом в вашей матрице.
Пример создания образов из трех различных объектов.
Абажур — Кулак — Бабочка — на первое место вашей матрицы можно поместить стеклянный абажур, в форме кулака, внутри абажура вместо лампочки светится бабочка.
Кино — Кроссворд — Писарь — на втором месте писарь, сидящий в полутемном зале кинотеатра, гусиным пером (чтоб не забыть что это именно писарь) разгадывает кроссворд.
Тексты
Запоминание текстов метода Цицерона можно использовать для запоминания достаточно объемной информации: например тексты, речи и т. д. Ниже описан процесс запоминания.
д. Ниже описан процесс запоминания.
Запоминание текста осуществляется в три шага
- Разбейте текст на отдельные смысловые участки.
- На каждом участке выберите несколько ключевых слов.
- Из выбранных ключевых слов создайте общий образ и поместите его на соответствующее место в матрице
Воспроизведение текста осуществляется в обратном порядке:
- Вызовите в памяти первую ячейку вашей матрицы и воспроизведите в памяти сохраненный в ней образ
- На основе образа вспомните ключевые слова, которые кодирует этот образ
- По ключевым словам восстановите участок текста, закодированный данным образом
Таким способом можно запоминать содержание достаточно длинных участков текста. Следует учитывать, что в тексте запоминается содержание, смысл, а не каждое слово дословно.
Носит имя одного из великих римский политиков, который прославился тем, что в процессе своих ярких выступлений никогда не пользовался записями. При этом оратор оперировал множеством цифр, имен, фактов, а также довольно часто использовал цитаты.
В соответствии с некоторыми источниками, метод Цицерона весьма успешно применялся задолго до официального его автора. В частности, известный древнегреческий поэт Симонид активно и успешно его практиковал.
Этот метод прост и одновременно эффективен. Другое его название – система римской комнаты. Он основывается на том, что ключевые единицы, которые надо запомнить, необходимо расставлять в мыслях в определенном порядке, представляя в голове привычное помещение. После такой процедуры достаточно лишь восстановить в памяти эту комнату, дабы восстановить все, что вы фиксировали в памяти. Цицерон, когда был занят подготовкой к публичному выступлению, прохаживался по дому и размещал в голове основные ключевые моменты своей речи в различных местах.
Перед тем, как начать практиковать запоминание по методу Цицерона, определитесь, каким образом вы планируете обходить комнату. Выберите последовательность мест, в которых вы планируете мысленно размещать ключевые единицы. Для некоторых представления комнаты в голове будет достаточно. Однако в первый раз не будет лишним пройтись по дому, как это делал великий оратор. При этом стоит выбирать привычную комнату, например – свой личный кабинет. Можете отдать предпочтение способу передвижения по часовой стрелке.
Однако в первый раз не будет лишним пройтись по дому, как это делал великий оратор. При этом стоит выбирать привычную комнату, например – свой личный кабинет. Можете отдать предпочтение способу передвижения по часовой стрелке.
С опытом вы будете в состоянии задействовать все большее число предметов и мест, тем самым расширяя свои возможности для фиксации информации. Вы можете использовать абсолютно любые предметы. Пусть это будет диван, телевизор, полка, рабочий стол, компьютер и так далее. Мысленно перемещаться можно и слева направо, и вверх-вниз. Вам не обязательно ограничиваться только своей комнатой. Для более эффективной фиксации в памяти можно использовать знакомые маршруты и т.п.
Вам необходимо связывать ключевые моменты информации, которую вы пытаетесь запомнить, с определенными предметами посредством ассоциаций. Начиная практиковать данный метод, не будет лишним иметь в голове набор элементов комнаты. Таким образом, у вас всегда будет «подручный» набор так называемых ментальных крючков, за которые вы сможете зацепить нужные ключевые моменты.
В качестве примера рассмотрим, как можно легко запомнить список следующих элементов: велосипед, рюкзак, бутылка, пластилин. Эти элементы будут размещены последовательно в соответствии со схемой дома. Начнем мы с коридора. Необходимо использовать нестандартные связи, чтобы его воспроизведение не составило труда даже спустя долгое время.
Велосипед размещаем на вешалке возле двери, причем находится он в перевернутом положении. Такая ассоциация легко отложится в нашей голове. Далее идет рюкзак, который весит на двери, а из него выглядывает кот. В бутылку мы ставим цветок подсолнуха и размещаем его на тумбочке. Зеркало, расположенное в прихожей, полностью заклеиваем пластилином, тем самым создавая нестандартную ассоциацию и фиксируя последний ключевой элемент в нашем списке. Таким образом, у нас получился довольно необычный ассоциативный ряд, который мы легко сможем восстановить в голове.
Очень важно предварительно определить те предметы, что будут встречаться нам на пути. В противном случае есть риск того, что вы будете сами искать детали, которые будет легче связать с определенным ключевым словом. В итоге, запоминание будет неэффективным.
В противном случае есть риск того, что вы будете сами искать детали, которые будет легче связать с определенным ключевым словом. В итоге, запоминание будет неэффективным.
Разумеется, метод Цицерона стоит применять для задач значительно сложнее. Вышеописанный пример лишь помогает понять, как происходит запоминание информации . Данный метод продуктивен в процессе фиксации в памяти текста, плана на день, порядка необходимых телефонных звонков и прочего. Более того, когда информация представляет собой логически связанные данные, а не просто набор слов, вы сможете неоднократно использовать одну комнату. При этом ряды ключевых элементов не перемешаются, а вы будете в состоянии легко восстанавливать данные по конкретной теме.
Чтобы научиться использовать данный метод, достаточно нескольких тренировок. Это и является его главным плюсом, если сравнивать данную методику с другими. Более того, эту технику можно использовать в любом месте. А то помещение, где вы находитесь, может стать отличной отправной точкой для запоминания информации. Вам нет необходимости использовать метод связанных ассоциаций или долго восстанавливать цепочку, как это нужно при применении метода последовательных ассоциаций. Вам лишь нужно восстановить в памяти знакомое помещение или использовать то, где вы находитесь в конкретный момент. Вполне достаточно рассматривать комнату, при этом расставляя ключевые слова и привязывая их к каким-то предметам. Восстановить информацию также просто. Достаточно вспомнить обстановку. Применяя этот метод, вы поразитесь, насколько легко и быстро можно усвоить даже весьма сложный материал.
Вам нет необходимости использовать метод связанных ассоциаций или долго восстанавливать цепочку, как это нужно при применении метода последовательных ассоциаций. Вам лишь нужно восстановить в памяти знакомое помещение или использовать то, где вы находитесь в конкретный момент. Вполне достаточно рассматривать комнату, при этом расставляя ключевые слова и привязывая их к каким-то предметам. Восстановить информацию также просто. Достаточно вспомнить обстановку. Применяя этот метод, вы поразитесь, насколько легко и быстро можно усвоить даже весьма сложный материал.
Метод Цицерона – это уникальный мнемонический прием , которому может научиться каждый. Даже если вы не относите себя к личностям с хорошей памятью, используя данную технику, вы легко превзойдете каждого из них.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter .
Бывает, что придя в
магазин, вы понимаете, что оставили
дома список с продуктами, который вам
надо было купить. Освоив метод Доминика
О’Брайена, вы сможете без труда держать
в голове список всего необходимого.
Освоив метод Доминика
О’Брайена, вы сможете без труда держать
в голове список всего необходимого.
Возьмем 10 произвольных товаров для рассматриваемого примера:
Яблоки — молоко — сыр — масло — батарейка — шахматная доска — баскетбольный мяч — теннисная ракета — кружка — вешалка
Многие из вас смогут без особых усилий запомнить 4-5 предметов, малая часть – 7-8.
На помощь придут специальное упражнение, разработанные Домиником О’Брайеном для совершенствования памяти.
Попробуйте вспомнить, как прошел сегодняшний день, чем она запомнился, что было вчера, на прошлой неделе. Что оставило самые яркие воспоминания?
Возьмите ручку и бумагу и запишите все, что помните за прошедший день, некоторые вещи, которые вы вспомните, удивят вас своим присутствием в этом, вроде бы, самом обычном дне.
Здесь важную роль играют именно ассоциации, с каким, тем или иным событием, связаны у вас определенные воспоминания, насколько оно было яркое.
Итак, вы отправились
в магазин за покупками. Поставьте
мысленно каждый предмет на определенные
места в пути следования. Для лучшего
запоминания, придавайте образу предметов
некую гипертрофированность и яркость.
Поставьте
мысленно каждый предмет на определенные
места в пути следования. Для лучшего
запоминания, придавайте образу предметов
некую гипертрофированность и яркость.
По прошествии времени, вы сможете вспоминать то, что необходимо купить еще по дороге в супермаркет, ведь тебе каждый предмет четко связан с конкретными ассоциациями.
Запоминание методом «цицерона»
Метод “Цицерона” – это метод запоминания, связанный с памятью на места.
Этот метод еще называют методом “мест”. Его создателем считают греческого поэта Симонида (ум. в 469 г. до Р.Х.) и рассказывают следующую историю.
“Симонида пригласили
к одному богатому человеку на пир. Когда
гости уже сидели за столом, поэта вызвали
по важному делу, и он тотчас же вышел
из комнаты. Как только Симонид вышел,
комната провалилась, и все находившиеся
в ней люди погибли. Чтобы похоронить
погибших, их родственники и друзья
попросили поэта опознать тела. И Симонид
вспомнил всех, сидящих за столом по
месту, которое они занимали. «Это подало
ему повод к открытию того закона, что
по месту можно вспомнить образ известного
лица, а это привело к открытию способа
запоминания”. (Г.И.Челпанов, 1900 г.)
«Это подало
ему повод к открытию того закона, что
по месту можно вспомнить образ известного
лица, а это привело к открытию способа
запоминания”. (Г.И.Челпанов, 1900 г.)
Так было сделано открытие, что наша память тесно связана с местом. И действительно, когда мы встречаем знакомого человека, то его имя можем вспомнить только после того, как вспомним, где мы его видели. То же самое происходит и в ситуации, когда мы были чем-то заняты, а нас вдруг отвлекли. Мы сможем вспомнить, что делали или о чем думали только тогда, когда вернемся на то место.
Метод назван именем великого оратора Цицерона потому, что он первым описал и применил его для запоминания своих речей. Этот метод до сих пор используют для запоминания длинных выступлений и большого числа точной информации.
Суть метода Цицерона сводится к тому, чтобы
выбрать какое-то хорошо знакомое место или помещение;
выделить по порядку предметы (или места), причем важно сразу определиться с последовательностью и принять раз и навсегда один вариант обхода помещения или места, например, по часовой стрелке;
выбирать
лучше яркие и хорошо запоминающиеся
предметы, которые постоянно находятся
в этом месте, например, шкаф. Если же
предмет регулярно меняет свое
месторасположение, то возможна путаница.
Например, если вазу переставить на
другое место, то, “считывая” информацию
вы можете назвать ее не в том порядке;
Если же
предмет регулярно меняет свое
месторасположение, то возможна путаница.
Например, если вазу переставить на
другое место, то, “считывая” информацию
вы можете назвать ее не в том порядке;
нельзя использовать повторяющиеся предметы, т.к. может быть нарушена последовательность, когда будете вспоминать. Например, если у вас два одинаковых кресла в комнате, то выбрать лучше первое из них;
соединять предметы, выбранные вами в комнате, с запоминаемой информацией попарно (о том, как их соединять, мы расскажем позже).
Полезные замечания
Перед запоминанием желательно прогуляться по тому месту, на которое будете запоминать информацию.
Подготовьте свои места и запомните последовательности предметов. Это вам понадобится для запоминания большого объема информации. Желательно иметь систему из 10 комнат, в каждой из которых выделено по 10 предметов. Тогда вы сможете на эту матрицу запомнить 1000 единиц информации! А это целый учебник!
Один
список, запомненный методом “Цицерона”,
хранится в памяти до трех суток без
повторения. Если вы хотите сохранить
информацию надолго, то никогда не
используйте этот список для запоминания
другой информации. Каждый предыдущий
список “стирается” под воздействием
следующего. Если же вам нужно запоминать
информацию только на несколько дней,
то можно сегодня запоминать на один
список, завтра — на другой, послезавтра
– на третий, а через два дня вернуться
к первому.
Если вы хотите сохранить
информацию надолго, то никогда не
используйте этот список для запоминания
другой информации. Каждый предыдущий
список “стирается” под воздействием
следующего. Если же вам нужно запоминать
информацию только на несколько дней,
то можно сегодня запоминать на один
список, завтра — на другой, послезавтра
– на третий, а через два дня вернуться
к первому.
Обязательным условием является контрольное припоминание
Итак, обойдем хорошо знакомое помещение по часовой стрелке. Теперь выделим последовательность предметов, т.е. 1 – дверь, 2 – кровать, 3 – занавеска, 4 – окно, 5 — книжная полка.
Обратите внимание, что в комнате есть второе окно, которое не подходит для запоминания!
6 – письменный стол, 7 – кресло
Итак, мы подготовили список предметов, отвечающий всем вышеперечисленным требованиям.
Васильева Е.Е. Васильев В.Ю. “СУПЕРПАМЯТЬ ДЛЯ ВСЕХ”
Главным отличием современной жизни является тот огромный поток информации, с которым человеку приходится сталкиваться практически ежедневно. Многим из нас нужно знакомиться с поставленными задачами и с намеченными планами, выступать перед большим количеством людей, правильно и красиво излагая им свои мысли, заниматься обучением, вызывая интерес у своих подопечных, и т.д. Однако далеко не каждому человеку под силу быстро и в полном объеме вносить в память полученные данные. И очень часто для того, чтобы запомнить необходимую информацию, люди пользуются методом ассоциации. Однако он не всегда достаточно эффективен. Его недостаток кроется в том, что подходит подобный способ лишь для небольшого числа объектов. А ведь порой возникает необходимость в усвоении произвольного текста среднего объема. В этом случае ассоциативная техника нужного результата не принесет. И тогда на помощь придет способ, который основан на работе с образами — мнемотехника. Метод Цицерона является как раз таким из них. Он и позволяет запоминать большое количество информации.
Многим из нас нужно знакомиться с поставленными задачами и с намеченными планами, выступать перед большим количеством людей, правильно и красиво излагая им свои мысли, заниматься обучением, вызывая интерес у своих подопечных, и т.д. Однако далеко не каждому человеку под силу быстро и в полном объеме вносить в память полученные данные. И очень часто для того, чтобы запомнить необходимую информацию, люди пользуются методом ассоциации. Однако он не всегда достаточно эффективен. Его недостаток кроется в том, что подходит подобный способ лишь для небольшого числа объектов. А ведь порой возникает необходимость в усвоении произвольного текста среднего объема. В этом случае ассоциативная техника нужного результата не принесет. И тогда на помощь придет способ, который основан на работе с образами — мнемотехника. Метод Цицерона является как раз таким из них. Он и позволяет запоминать большое количество информации.
В переводе с древнегреческого слово «мнемотехника» означает «искусство запоминать».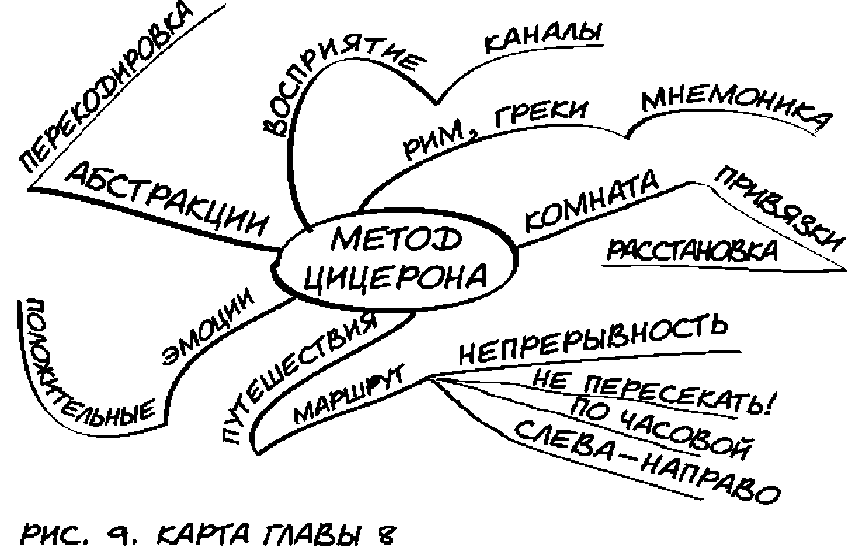 В результате его освоения человек не только развивает свою память, но и получает возможность обстоятельно и плавно излагать необходимую информацию, то есть приобрести ораторские навыки.
В результате его освоения человек не только развивает свою память, но и получает возможность обстоятельно и плавно излагать необходимую информацию, то есть приобрести ораторские навыки.
История появления
Метод Цицерона назван в честь государственного деятеля Римской Республики. Марк Туллий Цицерон вошел в историю и как знаменитый оратор, который прославился своей способностью воспроизведения по памяти большого количества исторических фактов, цитат и дат без использования, заготовленного на бумаге текста своих выступлений.
Однако подобный прием был использован еще до Цицерона. Его применял древнегреческий поэт Симонид. Однажды он участвовал в пышной и обильной трапезе, которую покинул раньше всех гостей. После ухода поэта в комнате обрушился потолок. Гости и хозяин дома погибли. Симонид пришел на опознание погибших и смог воспроизвести в памяти нахождение каждого человека в процессе празднования.
Но кто бы ни стоял у истоков возникновения данного способа, метод Цицерона на сегодняшний день считается одной из самых древних техник запоминаний.
Причины плохой памяти
Почему же далеко не все люди способны быстро запомнить большой объем информации? Дело в том, что память каждого человека обладает индивидуальными особенностями. Так, кто-то с легкостью, прочтя лишь один раз, сможет наизусть заучить таблицу умножения, но при этом практически сразу забудет имя того, с кем только что познакомился. Другим же людям, напротив, дана от природы хорошая зрительная память, однако выучить самые элементарные правила русского языка у них получается «со скрипом». В чем кроются причины нарушения памяти? Их всего пять. Рассмотрим их подробнее.
Отсутствие интереса
Существует самая популярная причина плохой памяти человека. Она кроется в отсутствующем или сниженном интересе. Ведь, согласитесь, довольно сложно запомнить ту информацию, которая не вызывает никакого желания для развития в данной области. И если человека, который не любит поэзию, попросить заучить стихотворение, то выполненное задание для него будет равносильно подвигу.
Невнимание
Еще одной причиной плохой памяти становится низкая концентрация на получаемых данных. На сегодняшний день на современного человека ежедневно выливается огромный поток информации. Это просто не дает ему возможности вникнуть в полученные данные. Порой люди, даже не понимая сути, не стремятся реализовать на практике ту информацию, которую они получили. И это, к сожалению, становится привычкой. Также на продуктивность деятельности человека негативно влияет и одновременное исполнение нескольких задач.
Прочие причины
Стоит отметить, что хорошая память природой нам не дается. Она является навыком, который требует своего развития. Влияет на ее уровень неправильное питание, авитаминоз и кислородное голодание организма. Также негативно сказывается на памяти и настоящий бич современного человека — депрессивное состояние. При таком самочувствии вряд ли можно не только запомнить вновь поступившую информацию, но и воспроизвести уже знакомую.
Именно поэтому каждый из нас должен включать в свой рацион здоровую пищу, постоянно совершать прогулки на свежем воздухе, заниматься физкультурой, приобщаться к активной жизненной позиции и не давать волю депрессиям.
Упорный труд
Известность государственного деятеля и оратора Цицерона распространялась по стране и по всему миру буквально со скоростью света. Его талант произношения речей до сих пор ставится в пример и нашим современникам. Так все же способность выступать перед огромной аудиторией без записей и подсказок была его даром или кропотливым трудом над развитием навыка запоминания? Без всякого сомнения, усердной работой, выполнение которой доступно каждому.
Овладев методом Цицерона, любой человек сможет легко удерживать в памяти фразы, слова, цифры, даты и прочую информацию. Однако для того, чтобы придти к такому результату, потребуется приложение огромного ежедневного труда. Другими словами, тренировка по методу Цицерона на запоминание должна проводиться каждый день.
Суть метода
В чем заключен основной смысл данного способа? Запоминание по методу Цицерона предусматривает создание матрицы образов. Они впоследствии позволяют фиксировать в памяти большие объемы данных, а не только один из фрагментов текста.
Запоминание по методу Цицерона заключается в выделении ключевых единиц информации, которые затем мысленно расставляются в определенном порядке в хорошо знакомом помещении, например, в комнате собственного дома. Во время выступления достаточно вспомнить во всех деталях созданный в воображении интерьер и воспроизвести его слушателям.
Это же делал и сам Цицерон. Перед каждым выступлением он прогуливался по многочисленным комнатам своего дома, «расставляя» важные идеи своей будущей речи в различных местах хорошо знакомых ему помещений. Это и позволяло оратору блестяще запомнить текст.
Начальный этап работы
Метод Цицерона при запоминании заключается в использовании мнемотехники. Для того чтобы воспроизвести свою речь в строгой последовательности, оратор разбивал текст выступления на части, готовя каждую из них в одном из своих покоев. Перед тем как выйти на публику, Цицерон совершал мысленную прогулку по комнатам, придерживаясь определенного маршрута. Все это помогало ему вспомнить именно ту часть речи, которую он готовил в том или ином помещении.
Перед тем как приступить к работе с текстом, понадобится прочесть его и выяснить о чем он. Далее вся информация должна быть разбита на несколько частей, несущих свое смысловое значение.
Обход помещений
Далее по методу Цицерона необходимо запомнить каждый из выделенных разделов информации. Причем сделать это необходимо в различных комнатах своего дома или квартиры. Порядок следования по ним должен быть строго определен. Например, из прихожей нужно переходить в ванную, из нее — направляться в туалет, далее следовать на кухню, пройти через гостиную, посетить детскую и завершить свой маршрут в спальне. Текст в таком случае должен быть воспроизведен с учетом последовательной подачи всех его частей. А для лучшего запоминания конкретной информации потребуется мысленно обходить каждую из комнат. При этом в ее определенных местах должны быть размещены конкретные данные, которые впоследствии можно будет с легкостью воспроизвести. Для начала так же, как это делал и сам автор методики, рекомендуется походить по комнате и мысленно расставить в ней все необходимые элементы. Таких тренировок понадобится лишь несколько. После этого образ комнаты человек легко начинает воспроизводить в своей памяти, мысленно вспоминая все те предметы, которые находятся в ней.
Таких тренировок понадобится лишь несколько. После этого образ комнаты человек легко начинает воспроизводить в своей памяти, мысленно вспоминая все те предметы, которые находятся в ней.
Метод Цицерона основан на принципе пространственного воображения, и для его максимально эффективного применения важно сохранять последовательность движений по помещению. Маршрут, например, может быть проложен по часовой стрелке или же в направлении от одной стены к другой. Усложнять себе задание при использовании метода Цицерона не стоит. Для запоминания информации необходимо выбрать для себя то помещение, которое уже достаточно хорошо изучено.
Вместо дома или квартиры может быть выбран, например, офис. Использовать можно и дорогу в ближайший магазин или на работу. Систему образов можно создавать и на воображаемой тропинке. Это позволит запоминать любое количество информации, так как у такого пути конца просто нет. Еще одним вариантом является создание воображаемого помещения. Его интерьер может быть выбран в соответствии с собственными пожеланиями и вкусом. Ограничивать фантазию при этом не стоит. Ведь помещение существует только в воображении и в мыслях.
Ограничивать фантазию при этом не стоит. Ведь помещение существует только в воображении и в мыслях.
Демонстрация метода
Применяя метод Цицерона на запоминание для детей, можно использовать с ними сюжеты сказок. Например, работа со всеми нам хорошо знакомым «Колобком» заключается в следующем:
1. В разбивке текста на шесть смысловых частей, каждая из которых должна быть представлена в виде образа: мука — колобок, катящийся по дороге — зайчик — волк — мохнатый медведь — лисичка-сестричка, которая ест колобка. В методе Цицерона на пространственное воображение подобные образы являются вспомогательными. Они нужны для кодировки той информации, которую необходимо запомнить. А вот образ самого места, уже существующего в нашей памяти и хорошо нам знакомого, в мнемотехнике носит название «опорный».
2. В мысленном соединении созданных в воображении вспомогательных образов — муки и колобка на дороге, зайца и т.д. с опорными, которыми будут служить кухня и гостиная, ванная и прочие комнаты. Так, мука стоит на кухне. По дороге в гостиную катится колобок. Заяц сидит в ванной, а волк — в туалете. Медведя можно найти в детской, а вот на балконе лиса ест колобка.
Так, мука стоит на кухне. По дороге в гостиную катится колобок. Заяц сидит в ванной, а волк — в туалете. Медведя можно найти в детской, а вот на балконе лиса ест колобка.
3. В повторении сказки с использованием мысленных образов, что позволит вспомнить сюжет, опорные образы и последовательность событий.
Преимущества способа
Приведенные выше примеры метода Цицерона дают представление о его использовании. Однако стоит иметь в виду, что такой способ позволяет решать и более сложные задачи. Это может быть, например, запоминание текста выступления, учебного материала, очередности выполнения звонков по телефону, плана на день и т. д.
Положительной стороной метода Цицерона на основе пространственного воображения является то, что воспроизведенный материал будет представлять собой логический связанный текст, а не просто набор случайных слов. При этом имеется возможность многократного использования в воображении одной и той же комнаты. Основные моменты не станут смешиваться между собой. Восстановить в памяти данные по определенной теме не составит труда для человека.
Восстановить в памяти данные по определенной теме не составит труда для человека.
Еще одним достоинством метода Цицерона является легкость его освоения. Достаточно проведения всего нескольких тренировок и пользоваться подобным способом можно будет в любом месте. При этом не придется придумывать ассоциации и долго восстанавливать их цепочку. Достаточно лишь вспомнить знакомую комнату или же внимательно осмотреть помещение, в котором человек находится в данный момент.
Основные правила для запоминания
Для максимально эффективного применения метода Цицерона необходимо:
Прикреплять выбранные образы в комнате с ярким освещением;
Изменять габариты воображаемых объектов на противоположные, делая мелкие большими, а крупные уменьшать до мизерных;
Делать динамичной и интересной связку между образами, существующими в помещении, и новыми.
можно запомнить всё / Хабр
habrahabr.ru/post/179397Вторая часть уже здесь!
Что такое мнемоника?
Я не люблю писать определения из википедии, поэтому объясню своими словами, что такое мнемоника. Мнемоника — это способы запомнить информацию путем смены типа информации. Вместо запоминания цифр запоминаете слова. Вместо слов можно запоминать места. Вместо ходов в шахматах — стихотворение.
Мнемоника — это способы запомнить информацию путем смены типа информации. Вместо запоминания цифр запоминаете слова. Вместо слов можно запоминать места. Вместо ходов в шахматах — стихотворение.
Самым простым примером мнемоники можно привести пример стишка, благодаря которому можно легко запомнить первые цифры после запятой в числе Пи:
Чтобы нам не ошибаться,
Надо правильно прочесть:
Три, четырнадцать, пятнадцать,
Девяносто два и шесть.
Ну и дальше надо знать,
Если мы вас спросим —
Это будет пять, три, пять,
Восемь, девять, семь.
пишите в комментариях другие примеры стишков для числа Пи. Я знаю, что их очень много
Скажу откровенно, я специально не искал на хабре информацию по мнемонике. Я хочу изложить взгляд со своей стороны: то, что знаю я. У меня не было желания “разбавлять” информацию другими источниками. Под катом много полезной информации, которую я очень долго собирал по крупицам.
Мнемоника очень обширна: в ней есть десятки способов запоминать все, что вам нужно. Некоторые способы я посчитал плохими, некоторые слишком сложными. Поэтому я выделил несколько лучших, на мой взгляд, приемов мнемоники. Я специально не буду вставлять описания с посторонних сайтов, объясняя все своими словами.
Дворец памяти (дорога Цицерона)
Описание
Древний философ и оратор Цицерон ежедневно ходил на “работу” пешком. Обладая блестящим вниманием, он изо дня в день замечал различные особенности в дороге, по которой он шествовал. Спустя долгое время, Цицерон запомнил дорогу настолько хорошо, что мог безукоризненно вспомнить любой ее промежуток со всеми деталями.
После этого Цицерон научился “привязывать” к дороге какие-нибудь предметы в своей памяти. И когда он вспоминал место на дороге, он моментально вспоминал о предмете, который был “привязан” к месту. Это называется
ассоциативная связь.
Метод дворца памяти (здесь и далее я имею в виду и дорогу Цицерона) заключается в сильных ассоциативных связях, благодаря которым можно запомнить любое количество информации в правильном порядке.
Как запомнить?
Чтобы воспользоваться дворцом памяти, нужно обладать хорошей фантазией. На самом деле любой человек может воспользоваться этим методом, но хорошая фантазия в этом очень поможет.
Возьмем абстрактный случайный набор продуктов, которые нужно купить в супермаркете:
- Пачку сахара
- Сухариков
- Банку горошка
- Крабовых палочек
- Клубничного джема
- Моркови
- Десяток яиц
- Кусок мяса
- Связку бананов
- Пакет молока
как видите, у меня с фантазией не так все хорошо
Теперь нам нужно найти “дорогу”, к которой мы будем привязывать этот список покупок. Люди с богатой фантазией могут придумывать сотни различных мест и хорошо их помнить (космическая станция, футбольная площадка в подводном лагере, что угодно), но для небольшого списка из десяти предметов можно воспользоваться настоящей дорогой.
Я приведу в пример свою “дорогу” и покажу, как привязывать к ней предметы. Вот мой путь, который я проделываю утром каждый день:
Вот мой путь, который я проделываю утром каждый день:
- Кровать (я на ней просыпаюсь)
- Туалет (стоит ли писать?)
- Кухня (завтрак)
- Коридор (одеваюсь, обуваюсь)
- Подъезд (спускаюсь по лестнице)
- Щит с рекламами напротив подъезда.
- Светофор, который я прохожу ежедневно.
- Магазин с мороженым.
- Шлагбаум перед школой.
- Крыльцо школы.
Чем больше информации нужно запомнить, тем подробнее стоит делать дорогу. Или длиннее — что вам проще. Главное — безукоризненно помнить в голове всю дорогу. С моей дорогой проблем не возникает, я хожу в школу каждый день.
Теперь займемся привязкой списка покупок. Самое важное в ассоциативной связи: сделать уникальные, необычные, смешные или ужасающие, любые неординарные ассоциации. Простые ассоциации “на кровати лежит пачка сахара” не подходят. Старайтесь добавить чувства к вашим ассоциациям: звук (хруст сухариков), осязание (противный сахар).
- Всю ночь я спал не на кровати, а на пачке сахара. Пачка была дырявая и у меня повсюду крошки сахара, они неприятно трескают, фу!
- Я захожу в туалет и наступаю на сухарики (мерзкий звук), от испуга поскальзываюсь и падаю лицом в унитаз. (чего не сделаешь для мнемоники)
- Выбравшись из этого ада, я захожу на кухню, открываю шкафчик, а на меня вываливается огромная гора горошка, скользкого и мерзкого (я не люблю горошек)
- В коридоре вместо ложки использую крабовые палочки для того, чтобы надеть обувь. Естественно, она ломается и я надеваю обувь с палочкой внутри.
- Я выхожу в подъезд, начинаю спускаться по лестнице и поскальзываюсь на джеме (что-то зачастил с падениями, ай-яй-яй)
- На щите красуется объявление о покупке планеты Морковий.
- На светофоре, когда я перехожу дорогу, меня закидывают яйцами из машин.
- Решаюсь купить мороженного, а на месте списка мороженного разные куски мяса (мерзость, никогда этого не забуду)
- Шлагбаум открывает макака за связку бананов. Квест!
- Только наступаю на крыльцо, весь пол превращается в молочный бассейн! А я не умею плавать! Ух…
 Квест!
Квест!Скорее всего мои ассоциации покажутся вам глупыми или неудачными. Но это первое, что пришло мне в голову. А это самое важное. Вам не нужно долго думать над ассоциацией, выбирайте первое, что придет в голову, иначе потом будете вспоминать так же долго, как придумывали. Попробуете всего несколько раз и будете делать это очень быстро, поверьте.
Благодаря этому способу я легко запоминаю 50-60 объектов, а потенциально — их может быть неограниченно — насколько хватит вашей дороги или дорог (никто не запрещает использовать несколько!).
Привязка к цифрам
Еще один способ, как запомнить какой-нибудь список или другую информацию. Способ несколько сложнее, требует подготовки, но в нем нет необходимости придумывать или запоминать дорогу.
Каждому числу от 1 до [сколько вам нужно] вы придумываете рифму, которая первой придет на ум. Вместо рифмы можно использовать сильную ассоциацию, которая у вас связана с цифрой. Главное — быть изобретательным. У меня выходит так:
Главное — быть изобретательным. У меня выходит так:
- Один — Алладин
- Два — Литва
- Три — потри (лампу)
- Четыре — дырки в сыре
- Пять — опят
- Шесть — Шест. (схоже по написанию)
- Семь — Джеймс Бонд (007)
- Восемь — Снеговик. (8 похоже на снеговика)
- Девять — лебедь
- Ноль — Колобок
Теперь, чтобы запомнить (привязать какой-то предмет) нужно лишь составить ассоциативную связь с этим предметом. Преимущество этого способа в отсутствии дороги, мы легко можем идти по числам. Недостатком метода является подготовка.
Интересный факт
Японец Хидеаки Томойори может воспроизвести число ПИ до 40 000 знаков. На запоминание такого количество цифр у него ушло около 10 лет.
mnemotexnika.narod.ru/sport_01.htm
P.S
О других способах я расскажу в следующий раз. О том, как запоминать цифры, слова, существует множество разных методов. А сейчас несколько истин относительно мнемоники, которые я заметил в момент занятий:
- Нужно минимум практики. Уже через две-три попытки вы будете хорошо составлять ассоциативные связи.
- В жизни это нужно достаточно редко.
- Зато это развивает обычную память!
- Большинство ваших друзей не смогут запомнить 20 предметов в правильном порядке, можно будет красоваться 😉
 Уже через две-три попытки вы будете хорошо составлять ассоциативные связи.
Уже через две-три попытки вы будете хорошо составлять ассоциативные связи.Откуда черпал?
- Corinda — 13 steps to mentalism
- Доминик О’Брайн — Как развить совершенную память
- Степанов — Мнемоника. Правда и вымыслы (так себе книжка)
Если найдете ошибки в тексте — пишите в личные сообщения, оперативно исправлю. Спасибо 🙂
общие принципы, задания, образное мышление, метод мест, запоминание цифр
Источник: «Практикум по повышению квалификации педагогов в работе с детьми (на материале использования игровых и психолингвистических средств)»
Эмануэль Т.С., Эмануэль Ю.В. \ под редакцией И.А.Добренко, А.А.Потапчук
Картинки: из сети Интернет
Сегодня поговорим о методах и принципах запоминания информации. То есть об основных принципах и приемах мнемоники. Коротко и наглядно (с просторов сети Интернет):
То есть об основных принципах и приемах мнемоники. Коротко и наглядно (с просторов сети Интернет):
Во-первых, существует несколько направлений проявления нашего словарного запаса:
- есть слова, которые мы распознаем (их огромное множество).
- есть слова, которые мы склонны использовать сугубо в рамках письменно речи (как правило, их несколько меньше)
- а есть слова, которые интегрированы в нашу устную и повседневную речь. Они составляют активный словарный запас.
Конечно, нам важно постараться включить новые выражения в свой активный словарный запас, чтобы быть в состоянии употреблять их регулярно и непринужденно, а не только понимать, услышав из уст собеседника, или размещать в тексте, предварительно сверившись со словарем. Для того чтобы слова и выражения действительно прижились и стали частью повседневной речи, лучше не просто несколько раз прочитать/произнести их, а проработать и обыграть: составить с ними предложения, оживить, проассоциировать и т. д.
д.
Ведь если мы хотим запомнить имя того, с кем только что свела нас судьба, лучше всего побыстрее обратиться к этому человеку, произнести имя вслух (активизировать еще и запоминание «на слух»), встроить в предложение (обращение) и т.д. Тогда это имя уже не будет для нас пустым звуком 🙂 То есть при запоминании информации важно пользоваться какими-то приемами.
Существует огромное множество различных уловок запоминания. Важно познакомиться со всеми, после чего варьировать их применение исходя из собственный предпочтений / тематики / настроения и т.д. То есть вам может понравиться какойц-то один способ запоминания, и именно он будет эффективен, но иногда, столкнувшись с другой информацией, вы вдруг решите применить иной прием. Поэтому давайте разберем различные приемы, чтобы вам было, из чего выбирать 🙂
Во-первых, нам никуда не деться от эффекта края, который гласит, что лучше всего запоминается информация, которая содержится в начале и в конце. То есть пока слушатель ЕЩЕ не уснул, и когда УЖЕ проснулся.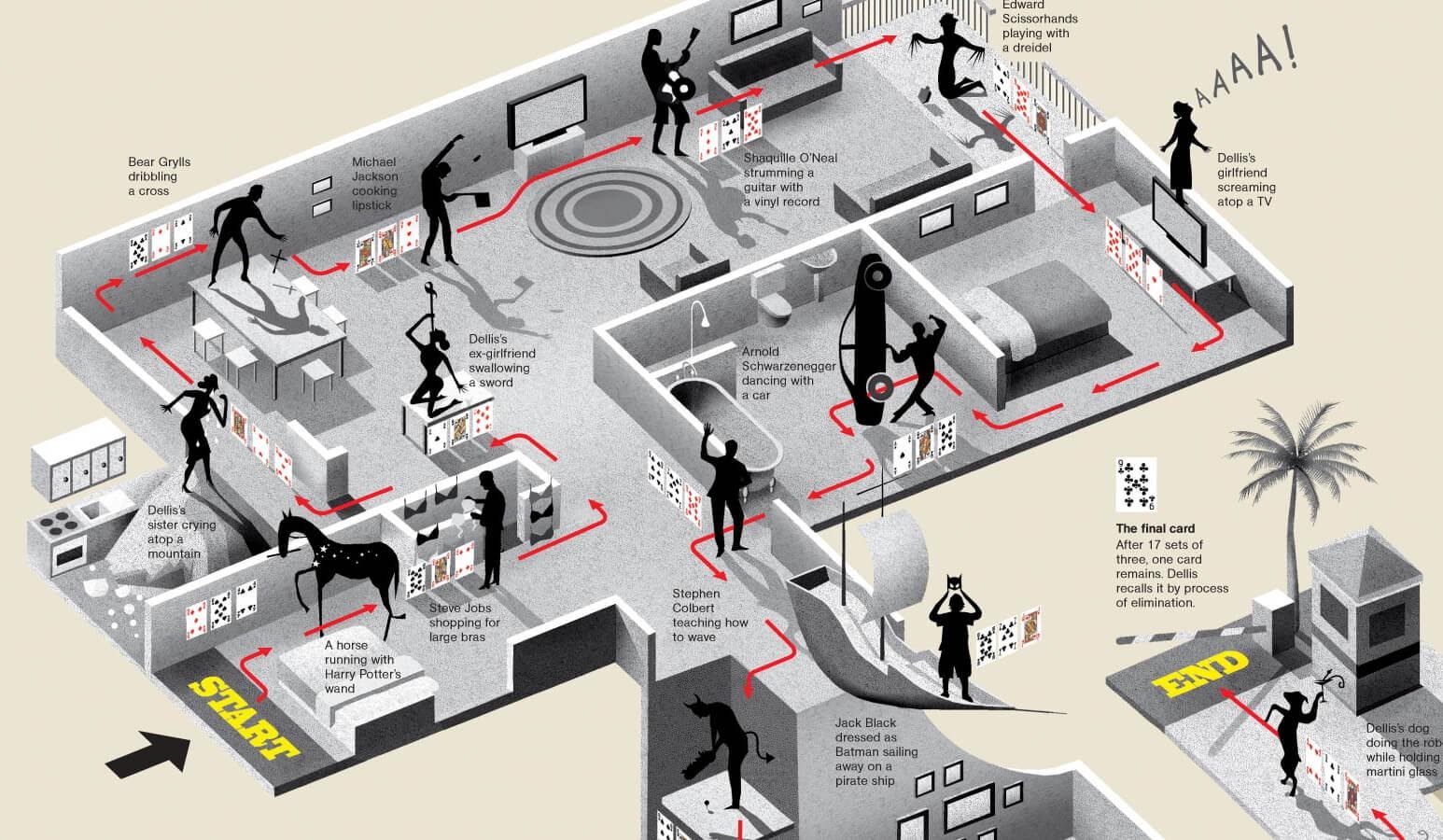 Важно также понимать, что обыгранная, приятная, эмоционально окрашенная информация запоминается намного лучше. Так устроен наш мозг.
Важно также понимать, что обыгранная, приятная, эмоционально окрашенная информация запоминается намного лучше. Так устроен наш мозг.
Конечно, важно оперировать образами 🙂
А тут смотрите, мы сразу фокусируемся на одиноком кружке. Потому что он больше и он выделен посредством обособления. Так и с информацией. Важно ее выделить, проассоциировать, оживить и т.д.
Причем со временем этот процесс станет АВТОМАТИЧЕСКИМ!! Важно потренироваться, и тогда навык кодирования информации станет вам родным!! ТО есть важно сделать так: познакомиться со всевозможными приемами, начать их применять, выбрать наиболее эффективные для себе и продолжить тренировку!! Тогда этот процесс точно станет частью Вас!! Просто начните!! Очень интересно, какие именно приемы окажутся вашими-вашими!! Пример творческих людей (из сети):
Начнем с самых простых. Что поможет нам сделать информацию более запоминающейся. Первый простой прием — цвет!! Раскрасьте в свое воображении тот объект, который надо запомнить!!!
Кстати!! Сам объект вы можете проассоциировать на основе игры слов!! Ведь аист — не только разносчик детей, а еще — привет из детства:
Следующий прием первого уровня — размер! Как и в ситуации с приемами творчества, тут тоже можно поиграть масштабом в своем воображении. Значительно приуменьшенный или искусственно увеличенный объект будет выделен и запомнится с большей
Значительно приуменьшенный или искусственно увеличенный объект будет выделен и запомнится с большей вероятностью эффективностью.
Детали. Если вам срочно надо что-то запомнить, углубитесь в детали, проработайте их.
И, конечно, динамика!!! Добавьте движения!!
Очевидно, данные приемы направлены на формирование в нашем воображении некого ОБРАЗА, который будет ВЫДЕЛЯТЬСЯ. Кроме того, пока мы будем его продумывать, уже немного сроднимся, в связи с чем данная информация станет для нас хоть чуть-чуть, но эмоционально окрашенной. Вот памятка:
А вот иллюстрация. Смотрите! Благородный Пигвин Пингвинович! Спешит к кому-то в гости!! В ярко-красном вязаном шарфе немыслимой длины и чудной шляпке на лысой макушке:
Конечно, чтобы запомнить информацию, нам важно структурировать ее при помощи взаимосвязей (логических, ассоциативных и т.д.), а иногда даже встроить в рассказ.
Мы познакомились с некоторыми простыми приемами, которые позволят приукрасить информацию. А теперь давайте поговорим о более серьезных вещах 🙂 Взаимосвязи, ассоциации и женская логика (а есть ли она).
А теперь давайте поговорим о более серьезных вещах 🙂 Взаимосвязи, ассоциации и женская логика (а есть ли она).
Для разминки и начала можно потренироваться на таких заданиях: объяснить, почему каждый объект — это И хорошо, И плохо. То есть установить противоречащие друг другу взаимосвязи, но остановиться, конечно, на подходе «хорошо». Почему сладкое — это плохо? А почему — хорошо? Стеклянная посуда? и т.д.
А теперь установите взаимосвязь между несколькими событиями. Придумайте середину. Причем в некоторых случаях «серединой» может быть одно предложение, а в некоторых — целая история. Решать — Вам!! Однако помните о психологической инерции и постарайтесь предложить какие-нибудь нестандартные варианты!!!!
Мастер взаимосвязей — Эдвард де Боно!!! У него есть огромное количество материала для развития памяти и мозга в целом!!! В том числе, следующее упражнение (потренируйтесь):
Установите связи между досками!!!! Попробуйте с одними и теми же словами обыграть различные варианты последовательностей! Для этого придумайте один вариант, после чего поменяйте все доски и думайте дальше (наш вечный принцип 2Д). Вот так это выглядит:
Вот так это выглядит:
Сейчас потренируйтесь, пожалуйста, самостоятельно, а ниже будут рассмотрены авторские примеры. Обыграйте ряд слов следующим образом:
- сначала придумайте «Логическое» объяснение того, почему КАЖДОЕ слово может быть лишним! Почему салнце в данном списке — лишнее слово? А теперь почеку понятие «выкуп»? и т.д.
- а потом этот же список слов НЕСКОЛЬКО РАЗ поделите на 2 группы, придумав совершенно разные «Поводы» — то есть критерии классификации.
Мы продолжаем генерировать взаимосвязи «на пустом месте». Чем лучше мы научимся этому сейчас, тем быстрее это станет получаться автоматически. Представьте, вам необходимо срочно запомнить какое-то понятия. А вы уже натренировались!!Да вы в считанные секунды сформируете несколько вариантов ассоциаций, взаимосвязей и «логических» объяснений!! И не только потренируете мозг, но и запомните необходимое!!!
И еще одно задание, уже посложнее. Выберите какую-ниубдь проьлему-задачу.![]() А потом определите любое (случайное) слово. И попробуйте, оттолкнувшись от него, придумать решения для исходной трудности. Здесь важно понимать, что случайное слово просто дает толчок, от которого можно оттолкнуться при генерировании идей. Примерно то же мы делали, когда разбирали метод фокальных объектов. Так что это снова позволит нам потренироваться думать, придумывать, устанавливать взаимосвязи!!!
А потом определите любое (случайное) слово. И попробуйте, оттолкнувшись от него, придумать решения для исходной трудности. Здесь важно понимать, что случайное слово просто дает толчок, от которого можно оттолкнуться при генерировании идей. Примерно то же мы делали, когда разбирали метод фокальных объектов. Так что это снова позволит нам потренироваться думать, придумывать, устанавливать взаимосвязи!!!
Кстати!! Эта установка на установление взаимосвязей очень полезна не только для запоминания, но и в обычной жизни!! При общении с людьми гораздо лучше — искать взаимосвязи и нечто общее!! Ведь различия и сами найдутся! Так что давайте будем применять этот навык и при общении с людьми: искать общее, схожее и т.д. Вспомните про АНАЛОГИИ!!!!
Мы немного размялись, поэтому давайте возьмем ряд слов и проработаем его на примерах. Вот наш исходный ряд слов: танцы, страус, облака. Давайте будем называть его не полностью, а просто «И. р.». Случайной слово (оно же — «С.с.» — ландыш).
р.». Случайной слово (оно же — «С.с.» — ландыш).
Теперь для каждого понятия из исходного ряда придумайте взаимосвязь со случайным словом. У вас получатся такие пары, которые необходимо будет объяснить: «танцы и ландыш», «страус и ландыш», «облака и ландыш». Постарайтесь придумать НЕочевидные варианты!
Вот некоторые авторские примеры возможных взаимосвязей. У вас получится намного лучше!!!!!
А вот пример того, как этот метод поможет нам с сочинительством, так как в здравом уме едва ли мы придумали такой бред мини-рассказ «с нуля».
То есть между случайным словом и каждым исходным объектом были установлены различные варианты взаимосвязей. При этом важно постараться, чтобы приведенные смысловые связки каждый раз основывались на различных положениях и были интересными и необычными. Например, лучше избегать тривиальных и очевидных взаимосвязей, таких как: «букетик ландышей, преподнесенный после танцевального выступления», «страус, нюхающий ландыш» и т. д. Кроме того, важно постараться не повторять взаимосвязей, даже более удачных: «страус по имени Ландыш», «облако по имени Ландыш», танец — и тот «Маленьких ландышей» — королевство тезок какое-то!
д. Кроме того, важно постараться не повторять взаимосвязей, даже более удачных: «страус по имени Ландыш», «облако по имени Ландыш», танец — и тот «Маленьких ландышей» — королевство тезок какое-то!
Такую «игру взаимосвязей» можно проводить и с использованием понятий из различных областей, как сделано в следующих примерах. То есть теперь в качестве случайных и/или исходных объектов лучше приводить понятия из специфических областей. Причем в данном случае слова-участники упражнения могут быть подобраны различным способом:
- тематический способ, при котором объекты подбираются исходя из определенной тематики,
- «хаотичный» способ, в рамках которого приводятся изначально не связанные между собой слова, посмотрев вокруг / открыв наугад книгу и другими способами случайного поиска
Важно понимать, что хаотичный подбор объектов направлен на активизацию работы мозга и творческого мышления в процессе установления взаимосвязи между случайными, на первый взгляд, объектами.
В свою очередь, тематический способ формирования исходного ряда характеризуется повышенной эффективностью проработки конкретной тематики, а также творческим усложнением задания. То есть теперь мы работаем с совершенно однотипными понятиями, но по-прежнему вынуждены придумать максимально различные идеи взаимосвязи. Например, нам предлагается связать со случайным понятием «стол» следующие виды птиц: зяблик, снегирь, тетерев и рябчик. В таком случае важно, чтобы для каждого существительного была придумана новая идея взаимосвязи, несмотря на схожесть исходных объектов. Конечно, все типы птиц могли бы быть связаны со случайным словом одним и тем же образом, однако предложение «зяблик, снегирь (а потом и тетерев с рябчиком) приземлились на стол» не может считаться творческим решением.
Ниже приведены примеры. Пожалуйста, сотворите свои варианты!!! Важно: не проматывайте, думая, что эти термины не относятся к вам. Они выбраны специально — чтобы мы попробовали их разобрать и запомнить на основе данного упражнения.
Взаимосвязи со случайным словом: комбинация № 1.
Какие РАЗЛИЧНЫЕ ВЗАИМОСВЯЗИ можно провести между устьем реки и ракетой, рукавов реки и снова ракетой, протоком и .. тадааам.. снова ракетой? Например, такие:
Взаимосвязи со случайным словом: комбинация № 2.
Давайте рассмотрим еще несколько примеров, параллельно с которыми придумайте, пожалуйста, свои варианты взаимосвязей!!!
Свяжем каждое слово из исходного ряда (И.Р.) со случайным словом (С.С.). Начнем с установление взаимосвязей в паре «ткани + камень»:
Вторая наша пара — «эпителиальные ткани + камень»:
Третья пара:
Взаимосвязи со случайным словом: комбинация № 3.
Взаимосвязи со случайным словом: комбинация № 4.
Очень полезно преобразовывать информацию в образы. Потренировать можно, например, на стихотворениях. То есть каждое слово изображается в виде схематичной картинки, и получаются иллюстрированные строчки) Вот пример стихотворений, закодированный в рисунки:
Зачем это надо? Помимо развития мозга как такового, это позволит нам намного лучше запомнить эти самый стихотворения! На основе образного мышления, логических взаимосвязей, оживления, эмоциональной окраске и т. д. А еще если внедрить рассмотренные простые приемы, то получится совсем незабываемо!!)) ВОт пример из сети Интернет: школьник закодировал Слово о полку Игореве:
д. А еще если внедрить рассмотренные простые приемы, то получится совсем незабываемо!!)) ВОт пример из сети Интернет: школьник закодировал Слово о полку Игореве:
Кстати!!! кодировать в образы можно и отдельные слова! Наша задача — написать слово так, чтобы иностранец, который не знает языка, догадался, о чем идет речь:
А вот смотрите, как интересно! Даже если мы не знаем значения иероглифов, мы можем догадываться и подозревать))) Рот, двери, замОк, дерево и т.д. Кстати!! Иероглифы с женщинами: первый — это просто дама, второй означает «ссора»)) Неспроста)))
А еще это может помочь нам при работе над ошибками при правописании, как уже обсуждали:
Мы уже поняли, что для того чтобы лучше запоминать информацию, лучше развивать у себя образное мышление. Причем это можно использовать не только «вообще», но и в профессиональной деятельности! Ведь едва ли мы с успехом запомним сплошное полотно текста, которое иногда размещают прямо в презентации:
Будет намного более эффективным преобразовать этот же тест в образы:
А еще лучше — внедрить игру слов. Например, понятие «следить» можно трактовать не только как подглядывание и учет, но и как процесс формирование следов.
Например, понятие «следить» можно трактовать не только как подглядывание и учет, но и как процесс формирование следов.
Еще очень помогает оживление безликих фраз. Например, морозоустойчивое покрытие не покоряется морозу:
И снова пример игры слов: «группа продленного дня» — это не только сборище детей, чьи родители еще работают, но и вокально-инструментальный ансамбль:
«Самостоятельный» въезд. С улицы.
Как запомнить эти однообразные комбинации цветов? Первым делом давайте обобщим:
А потом можем совместить образное мышление с установлением взаимосвязей. Смотрите:
У нас получились флаги, цвета которых сделаны из продуктов, наиболее популярных в этой стране!!!!! В таком прочтении, когда мы совмещаем мысли и эмоции, намного успешнее запомним тот же самый материал!
А вот — подборка примеров преобразования информации в образы! Как все наглядно, «читаемо-воспринимаемо» и «запоминаемо»!!!!!
А еще можно преобразовать какой-то факт в диаграмму!!! Это тоже очень интересно!!! Ниже представлены примеры из сети интернет, в рамках которых известные факты нашли себя в ярких и образных диаграммах!!! Смотрите:
И еще один пример того, как можно «Разложить» информацию Ведь то же самое можно сделать по любой тематике, которую надо запомнить!! Тематическая азбука:
Конечно, важно помнить, что одну и ту же информацию каждый закодирует совершенно по-своему!!!! Это и прекрасно!!!
А вот примеры того, как можно обыграть, оживить и иллюстрировать факты, чтобы лучше их запомнить!!! А еще эти рисунки можно превратить в загадки, если закрыть сами имя!! И попросить кого-то освежить в памяти дела великих!!!
А иногда нам достаточно одного обобщающего слова:
Существуют разные техники запоминания цифр. Например, номер телефона мы можем запомнить на основе взаимосвязей и ассоциаций. Для этого нужно просто разбить цифровой ряд на связки цифр и связать каждую комбинацию с чем-то знакомым. Например, 18 — совершеннолетие, 65 — номер дома, 95 — бензин, 743 — это 7=4+3 и т.д. Главное — чтобы взаимосвязь именно для нас представлялась очевидной! То есть первый метод основывается на установлении ВЗАИМОСВЯЗЕЙ, которые мы уже немного разобрали!
Например, номер телефона мы можем запомнить на основе взаимосвязей и ассоциаций. Для этого нужно просто разбить цифровой ряд на связки цифр и связать каждую комбинацию с чем-то знакомым. Например, 18 — совершеннолетие, 65 — номер дома, 95 — бензин, 743 — это 7=4+3 и т.д. Главное — чтобы взаимосвязь именно для нас представлялась очевидной! То есть первый метод основывается на установлении ВЗАИМОСВЯЗЕЙ, которые мы уже немного разобрали!
Есть другой метод запоминания цифр. На основе ОБРАЗНОГО МЫШЛЕНИЯ, тоже нами уже слегка разобранного. Так, для каждой цифры предлагается разработать визуальный образ, отождествляющий ее. Рекомендуется сделать эти образы цветными, яркими, необычными (вспомните про простые приемы, которые мы рассмотрели в самом начале).
Важно, чтобы со временем у вас возникла тесная взаимосвязь между цифрами и созданным для них ассоциативными образами, которые могут подбираться на основе РАЗЛИЧНЫХ критериев аналогий, а именно:
- соответствие цифры и объекта по форме (лебедь в форме двойки; бант, похожий на восьмерку и т. д.),
- соответствие значения числа и стандартного количества объектов (2 глаза, 4 колеса, 7 козлят и т.д.),
- личная ассоциация (например, в детстве вам подарили определенный подарок на пятилетие, поэтому теперь цифра 5 ассоциируется у вас исключительно с медведем) и др.
 д.),
д.),Важно, чтобы визуальные образы были близки лично Вам и со временем возникали в голове как отклик на цифру почти автоматически.
Для развития речи (помните принцип одной буквы?) после того как образы подобраны, давайте придумаем серию названий:
- характеристика и наименование цифры, подобранные на одну и ту же букву (верхняя строчка),
- характеристика и наименование визуального образа, подобранные на одну и ту же букву (нижняя строчка).
Вот пример. Сотворите, пожалуйста, свой 🙂
То есть подбор характеристик позволит развить образность мышления и обогатить речь. Кроме того, оживление объектов позволит повысить успешность их запоминания, так как память во многом зависит от визуальных образов и эмоциональных откликов, которые возникают у нас в ответ на некую информацию.
Регулярные тренировки приведут к значительному повышению скорости мышления и возникновения ассоциативных образов, увеличению степени их взаимосвязи с исходным понятием, уровня индивидуальной значимости и т.д.
Для того чтобы запомнить последовательность цифр мы можем связать ряд образов в небольшую историю. Предположим, нам нужно запомнить номер дома и квартиры. Для этого нам просто надо совершить несколько действий.
Действие 1. Выявление цифр, которые содержатся в адресе. Пример: дом № 78, квартира № 63. Цифры: 7,8,6,3.
Действие 2. Сопоставление каждой цифры с созданным лично ВАМИ образом. Пример: на основе примера из разминки мы можем получить следующее соответствие: 7 – вышка, 8 – бант; 6 – улитка, 3– птица.
Действие 3. Составление предложения или небольшой истории, в сюжет которого последовательно встроены ассоциативные образы. Пример: «Все готово к празднику, даже вышка (7) в бассейне уже украшена безупречным бантом (8), и увлеченная улитка (6) Уристина торопится, чтобы успеть на день рождения к печальной птице (3) Парамону».
Действие 4. Изображение придуманной истории. Для более успешного запоминания важно постараться иллюстрировать ИЛИ ПРЕДСТАВИТЬ в воображении свою историю. Это позволит активизировать зрительную (а если будем рисовать, то и моторную) память, а также образное мышление. Так, вспоминая свой рисунок улитки, мы будет понимать, что речь шла о цифре 6 и т.д. По такому же принципу можно запоминать номера телефонов и другие «числовые» объекты.
Важно, чтобы вы использовали те «циферные образы», которые придумали самостоятельно. В данном случае вам не придется запоминать еще и навязанный «визуальный код» цифр, а все внимание будет уделено непосредственно образу и истории. Так, вам только нужно будет запомнить вышку, которая украшена бантом, в то время как раскодирование вышки в цифру семь, а банта – в цифру восемь будет происходить автоматически. В результате регулярных тренировок процесс кодирования и раскодирования значительно ускоряется, и время, затраченное на установление ассоциативной связи, заметно минимизируется.
ВАЖНО: даже если запоминать вы так не будете, это все равно полезно — развить мозг, воображение и т.д.!!!!
Важно: этот метод полезно узнать для развития мозга!! Даже если пользоваться им для вас будет не так удобно, это полезно именно с точки зрения развития мышления и творческих способностей!!!!!!
Можно выделить несколько способов запоминания последовательности слов. Во-первых, можно применить метод, отработанный при запоминании последовательности цифр, — создание историй. Таким образом, чтобы запомнить и воспроизвести ряд слов, нам снова предлагается создать историю, в сюжет которой последовательно включить необходимые понятия.
Пример: исходный ряд: книга, ложка, лампа, обед, машина. Возможная история: «Жила-была Книга, огромная и оранжевая. Однажды она осталась на кухне и встретила там самую длинную в мире Ложку…».
Во-вторых, запомнить слова в определенной последовательности можно посредством применения визуальных образов цифр, созданных в рамках разминки.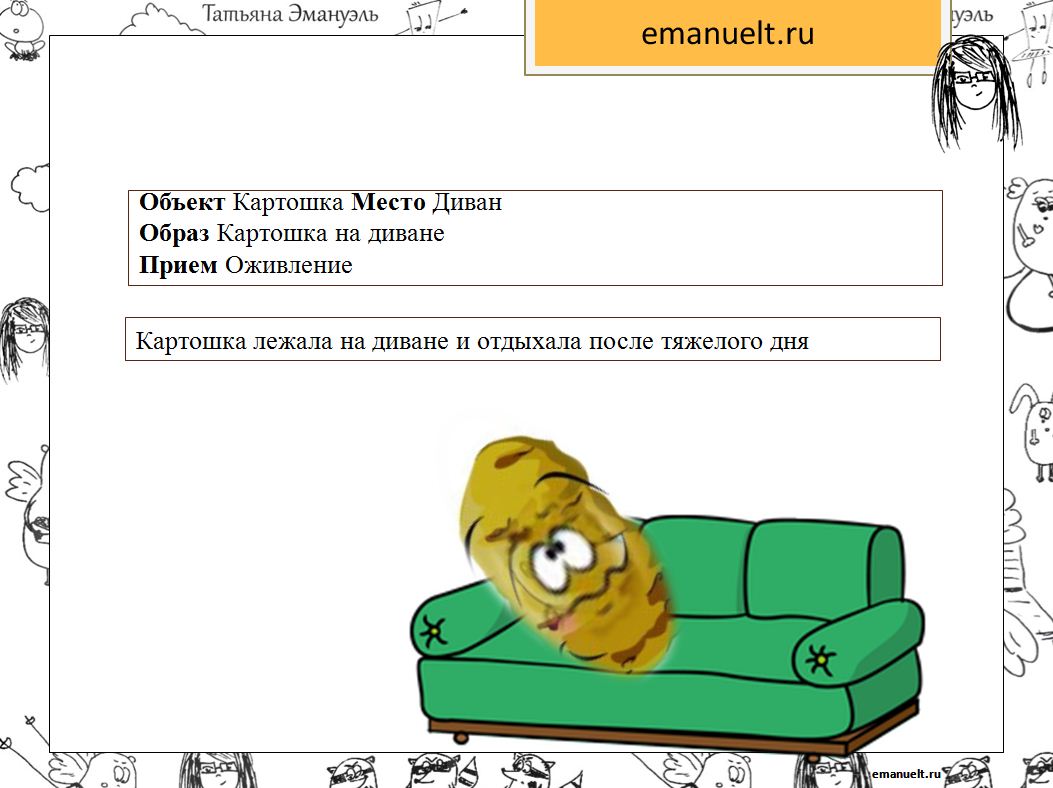 Так, для того чтобы запомнить определенный порядок слов, необходимо связать каждое понятие с образом той цифры, под номером которой оно идет в перечислении. Рассмотрим реализацию данного метода на примере, в рамках которого необходимо запомнить по порядку следующие слова: тарелка, такси, портфель, дерево. Для этого нам нужно придумать смысловую связь между образом цифры, и каждым словом, соответствующим данному номеру.
Так, для того чтобы запомнить определенный порядок слов, необходимо связать каждое понятие с образом той цифры, под номером которой оно идет в перечислении. Рассмотрим реализацию данного метода на примере, в рамках которого необходимо запомнить по порядку следующие слова: тарелка, такси, портфель, дерево. Для этого нам нужно придумать смысловую связь между образом цифры, и каждым словом, соответствующим данному номеру.
Из таблицы видно, что мы связываем образ, отождествляющий цифру, и слово, которое идет под этим номером, продумывая взаимосвязь в виде небольшого сюжета и/или изображением. Сам процесс раскодирования образов, как правило, строится по следующей схеме.
- Первым делом воспроизводим в памяти совокупный образ: например, деревянная тарелка Буратино, сделанная из полена.
- После этого происходит выделение закодированного образа цифры и запоминаемого слова. Так, если для нас «полено» означает единицу, значит, «тарелка» идет под номером один. В свою очередь, наличие лебедя в рекламе такси говорит о том, что «такси» идет под цифрой два и т.д.
 В свою очередь, наличие лебедя в рекламе такси говорит о том, что «такси» идет под цифрой два и т.д.
В свою очередь, наличие лебедя в рекламе такси говорит о том, что «такси» идет под цифрой два и т.д.Предположим, вы увидели какие-то чудесные бусы! И решили сотворить их самостоятельно!! Но именно такие!! Для этого вам важно запомнить последовательность бусин!! Вам либо нужно срочно найти себе листок для записей, либо использовать воображение и мнемотехнику! На основе применения метода Образ цифры + объект» может получиться следующее
То есть вы совместили бусину с образом той цифры, в порядке которой следует сама бусина. Опять же: если вы считаете, что пользоваться этим методом долго и неудобно, просто потренируйтесь в его применении ради практики установления взаимосвязей и кодирования информации!!! Чем больше попыток будет предпринято, тем привычней и естественней станет сам процесс!!!!
Например, вы решили повторить хронологию правителей. Объединение образа цифры и правителя (на основе смысловых и ассоциативных связей) можно представить в следующей таблице.
А потом вы вспоминаете ассоциативный образ: «Олег кормит лебедей». Поскольку лебедь отождествляет цифру «2», как и в предыдущем примере, вам становится ясно, что князь Олег идет под номером 2. И вы сможете блеснуть своими знаниями перед изумленной публикой 🙂
Давайте еще успеем разобрать Метод МЕСТ!! Или, как его еще называют, метод Цицерона! Нам необходимо разместить каждое слово на определенных местах в помещении / по дороге и т.д. То есть мы представляем образ определенного слова, помещенный в конкретное место. Например, зайца, сидящего на полке в шкафу. Получается, что каждый образ представлен и закреплен в определенном месте. Для того чтобы вспомнить и воспроизвести все исходные объекты, нам просто нужно мысленно представить выбранный маршрут и «встретить» на нем все предварительно размещенные слова.
Предположим, нам приспичило запомнить следующий ряд слов: книга, ложка, лампа, обед, машина. Поэтому мы можем оглядеться вокруг и разместить образы в комнате, в которой находимся.
Поэтому мы можем оглядеться вокруг и разместить образы в комнате, в которой находимся.
То есть мы установили логическую или ассоциативную связь между оживленным объектом и местом его воображаемого расположения. Тут важно именно представить эти объекты на этих местах. Нарисовать их в своем воображении!!! С учетом тех простых приемов, о которых мы говорили в самом начале! Чем ярче и нелепее будут ваши образы, тем больше вероятности, что они запомнятся!! Давайте разберем, как этот метод поможет нам не только потренировать мозг и творческое мышление, но и запомнить список покупок, которые необходимо купить.
Предположим, нам нужно запомнить следующий список покупок: картошка, хлеб, сыр, зеленый горошек, яблоки, салфетки, корм для кота. НО!!! С целью повышения эффективности запоминания, давайте совместим метод мест с придумыванием истории, а также постараемся применить следующие приемы: оживление, преувеличение, эмоциональность, цвет, действие, нестандартность ситуации.
То есть у нас получается следующая связка: объект + МЕСТО, на котором мы его расположим в рамках метода Цицерона + ПРИЕМ, который достанется именно этому объекту. Вот такая табличка:
Всё!! План у нас есть!! Теперь просто придумываем!!!!!! И встраиваем в историю (какую-никакую):
Пока мы будем все это выдумывать, что-то уж точно запомним)
Важно: устанавливать взаимосвязи! Кодировать информацию! Переводить ее в образы! Пробовать различные методы и техники — как минимум, для развития мозга!!! Радоваться жизни 🙂
Видео
Как улучшить память ребенка — stavsad12.ru
27.10.2011Как улучшить память ребёнка? Этот вопрос интересует многих родителей.
Приведенные ниже упражнения часто используются воспитателями детских садов и начальных классов школы для развития всех видов памяти у детей. Потренируйтесь и Вы со своим ребенком.
Потренируйтесь и Вы со своим ребенком.
«10 слов»
Зачитайте ребенку список, например: утро, корова, летчик, лыжи, трамвай, река, картина, кольцо, садовник, карандаш. А затем попросите его повторить. Если дошкольник 6-7 лет в состоянии воспроизвести 5-6 слов — это замечательный показатель кратковременной памяти. Напомните ему те слова, которые он забыл. А примерно через час вернитесь к упражнению. Теперь пусть ребенок без подсказки вспомнит все, что он называл. Долговременная память считается очень хорошей, если малыш вспомнил хотя бы 7-8 слов.
«Повтори звуки»
Предложите ему закрыть глаза и не открывать их в течение минуты. Ваша задача — издать ряд звуков: пошуршать газетой, постучать ложечкой о стенку чашки, пощелкать пальцами, позвенеть в колокольчик… Попросите ребенка повторить изданные вами звуки в той последовательности, в которой он их услышал.
Метод Цицерона, или всему своё место
Заключается он в том, чтобы мысленно расположить образы, которые необходимо запомнить, в хорошо знакомом пространстве — например, в собственной комнате.
Предложите ребенку запомнить 10 слов, к примеру: зонт, стрекоза, море, слон, конфета, сад, ворона, кастрюля, апельсин, ложка. И объясните, как все вышеперечисленное нужно «размещать» в помещении, чтобы потом без труда извлечь из памяти: «Большой зеленый зонт мы «повесим» на ручку двери, стрекозу увеличим до гигантских размеров и «посадим» на ковер, висящий на стене. Море пусть бушует в телевизоре, слон (его мы уменьшим до размеров спичечного коробка) будет прогуливаться под сенью фикуса, растущего на подоконнике. Огромную конфету в ярком фантике мы «разместим» на балконе — она так велика, что едва там помещается. Цветущий сад «разобьем» на полу. Ворону «посадим» на люстру».
В итоге для того, чтобы воспроизвести потом цепочку слов, придется всего лишь восстановить в памяти интерьер родного жилища. Пользуясь этим методом, нужно соблюдать правило: маленькие предметы лучше увеличивать до больших размеров, а большие уменьшать (что мы и проделали со слоном и стрекозой)
«10 картинок»
Возьмите 10 изображений различных предметов. Пусть ребенок рассмотрит их, а спустя 30 секунд назовет то, что удалось запомнить. 6-7 картинок из 10 -прекрасный результат для 6-7-летнего возраста. Затем покажите те картинки, о которых он забыл. А через час попросите вспомнить все изображения. Об отличных показателях долговременной памяти можно говорить, если названо 7 и более картинок.
Пусть ребенок рассмотрит их, а спустя 30 секунд назовет то, что удалось запомнить. 6-7 картинок из 10 -прекрасный результат для 6-7-летнего возраста. Затем покажите те картинки, о которых он забыл. А через час попросите вспомнить все изображения. Об отличных показателях долговременной памяти можно говорить, если названо 7 и более картинок.
«Найди 10 отличий»
Хорошие результаты могут принести регулярно выполняемые задания из серии «Что изменилось на картинке?», «Найди два одинаковых предмета» и пр. Их без труда можно отыскать в развивающих книжках и детских журналах.
Она особенно развита у потерявших зрение. Но ее можно и нужно тренировать всем. Мы запоминаем ощущения, которые испытываем, прикасаясь к чему-либо. Возьмите несколько предметов с различной поверхностью – деревянные и металлические, теплые и холодные, гладкие и шершавые. Предложите малышу закрыть глаза, потрогать их, а затем пусть он попытается угадать, что у него в руках
Сочиняем рассказ
Еще один способ запомнить как можно больше слов, картинок или предметов — придумать историю с их участием, связный рассказ, где каждому из элементов отведена роль. Предположим, перед ребенком разложен ряд карточек, на которых изображены кошка, книга, апельсин, месяц, кровать, мышь, шляпа и т. д. Рассказ малыша может быть таким: «Кошка читала книгу, на одной из страниц которой был нарисован апельсин. Наступил вечер, на небе появился месяц. Кошке захотелось спать, она отправилась в свою кроватку и заснула. Во сне она увидела мышь в шляпе».
Предположим, перед ребенком разложен ряд карточек, на которых изображены кошка, книга, апельсин, месяц, кровать, мышь, шляпа и т. д. Рассказ малыша может быть таким: «Кошка читала книгу, на одной из страниц которой был нарисован апельсин. Наступил вечер, на небе появился месяц. Кошке захотелось спать, она отправилась в свою кроватку и заснула. Во сне она увидела мышь в шляпе».
Выполняя это упражнение, необходимо учитывать, что слова между собой нужно связывать по порядку. И еще: чем невероятнее и забавнее получилась история, тем больше шансов, что ребенок воспроизведет все заданные слова.
Чудесные превращения
Помните мультфильм про пластилиновую ворону, которая превращалась в корову, собаку, дворника и двух страусов — доброго и злого? Мнемотехнический прием, о котором пойдет речь, основан на том же принципе. Назовите первое слово и попросите ребенка во что-то мысленно его «превратить». У предмета или существа могут отрастать уши, лапы, хвост… В своем воображении малышу разрешено всячески изменять его форму, размер, цвет, совсем как если бы из большого комка пластилина он поочередно создавал разные фигурки.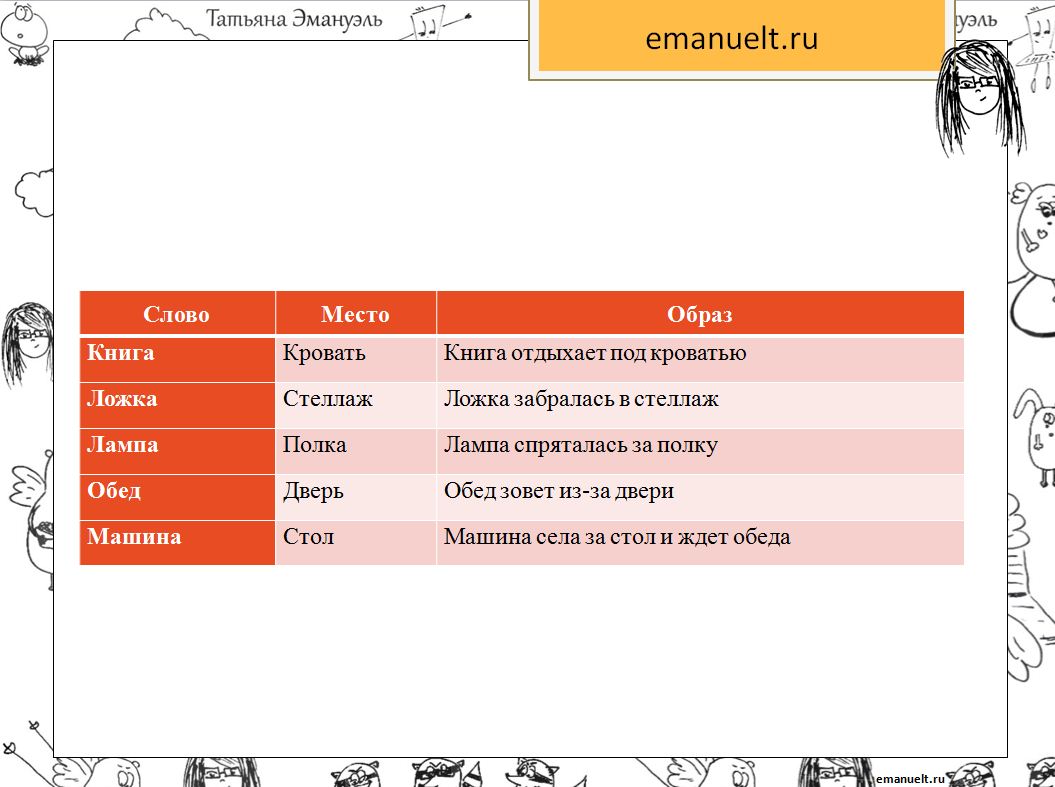
Например, первое слово «карандаш». Вдруг он начинает растягиваться, делается мягким, гибким, очень тонким. Затем скручивается, сворачивается — и вот уже перед нами клубок ниток, из которого начинают расти иголки. Клубочек оживает и превращается в ежика. В зависимости от возраста можно совершать от 10 до 20 чудесных превращений, после чего юному волшебнику предстоит вспомнить весь ряд слов: карандаш, клубок, ежик и т. д. Если с легкостью названы все, надо усложнить задачу — следующую цепочку сделать длиннее на 3-4 элемента.
Доклад «Техника эффективного запоминания»
Техника эффективного запоминания
Когда информация трудна для запоминания, когда выпускники ограничены во времени, на помощь приходят специальные приемы быстрого запоминания. Освоив эти принципы, обучающиеся смогут запоминать любую необходимую им информацию самым эффективным для них способом. Существует множество техник для развития и укрепления памяти, но наиболее эффективной, по мнению большинства, считается мнемоника или мнемоническая техника. Мнемотехника (в переводе с греч. – искусство запоминания) представляет собой совокупность приемов и способов, которые значительно облегчают запоминание информации, а также увеличивают объем памяти с помощью ассоциативных связей.
Мнемотехника (в переводе с греч. – искусство запоминания) представляет собой совокупность приемов и способов, которые значительно облегчают запоминание информации, а также увеличивают объем памяти с помощью ассоциативных связей.
Основные приёмы:
Образование смысловых фраз из начальных букв запоминаемой информации
Рифмизация
Запоминание длинных терминов или иностранных слов с помощью созвучных
Нахождение ярких необычных ассоциаций (картинки, фразы), которые соединяются с запоминаемой информацией
Метод Цицерона на пространственное воображение
Метод Айвазовского основан на тренировке зрительной памяти
Методы запоминания цифр:
закономерности
знакомые числа
При подготовке учащихся к ЕГЭ, ОГЭ часто использую прием «Формируйте фразы из первых букв информации » Ярким примером такого приема служит последовательность цветов в спектре: «Каждый Охотник Желает Знать, Где Сидит Фазан». Первая буква каждого слова означает определенный цвет: К – красный, О –оранжевый, Ж – желтый и т. д.
д.
Классификация. Царство Животные.
Все | Вид |
Рэп | Род |
Считают | Семейство |
Очень | Отряд |
Классной | Класс |
Темой | Тип |
Царь | Царство |
|
|
Классификация Царства Растений
Все | Вид |
Растения | Род |
Симпатичны | Семейство |
Посмотри | Порядок |
Они | Отдел |
Кругом | Класс |
Царствуют | Царство |
Палеозой |
|
Ранний
Кембрий Ордовик Силур
Девон Карбон Пермь
|
Каждый Отличный Студент
Должен Красиво Петь |
Мезозой
Триас Юрский Мел |
Ты Юра Мал |
Кайнозой Палеогеновый Неогеновый Четвертичный (Антропогеновый) |
Подлей Нам Чайку
|
Катархей Архей Протерозой Палеозой Мезозой Кайнозой
| Вариант А Потом Появился Мир Кайнозойский
2)вариант Ароматный Пряник Положила Мама Коле |
ПАПА, МАМА, АНЯ, ТАНЯ ( фазы митоза)
Делюсь своим опытом.
Даны следующие предметы: гематоген, бусы, яйцо куриное, а также называются слова: фибриноген, Rh+.
Вставьте пропущенное слово в цитате Ф.Энгельса : «Жизнь есть способ существования ______ тел» Вопрос : « Что объединяет эти понятия?» назовите слово ( Белок) Прочитайте высказывание Ф Энгельса.
БЕЛКИ -высокомолекулярные соединения играют огромную роль в жизни любого организма. Биосинтез белка одна из сложных тем при изучении общей биологии. Задание №27 (КИМ по биологии) на биосинтез белка оценивается в 3 балла. (Решение задания №27 вариант№1 2018г)
При решении данного задания используем фразу: « Дима и Толя братья» моя фраза Д-ДНК ТТТ АГЦ ТГЦ И-(и-РНК) ААА УЦГ АЦГ ( транскрипция) Т-(т-РНК) УУУ АГЦ УГЦ (антикодоны) Б-(белок) ЛИЗ СЕР ТРЕ
Транскрипцию и нахождение антикодонов лучше сделать по таблице
ДНК | И-РНК (транскрипция) | Т-РНК (антикодоны) |
А | У | А |
Т | А | У |
Ц | Г | Ц |
Г | Ц | Г |
Запомни! Аминокислоты в Т-РНК читаются по И-РНК
Аминокислоты находятся по таблице « Генетический код»
Бусы яркий пример запоминания того, что биосинтез протекает на рибосомах: Нить-и-РНК, бусинки-рибосомы.
Используя «ступеньки» (Дима и Толя братья ) можно легко найти : антикодоны, белок ,ДНК и т.д
В заключение следует сказать, что использование мнемотехники ни в коем случае не призвано заменить самый известный и широко популярный метод в развитии и укреплении памяти — традиционное заучивание текстов наизусть. Однако с задачей помочь сделать процесс запоминания более простым, интересным мнемоника справляется просто великолепно. Попробуйте применить основные мнемонические приемы на себе — и вы скоро ощутите ее полезность и незаменимость. Вопросы педагогам: Какие мнемонические приемы используют ваши воспитанники на занятиях и в играх? Вводите ли вы новые приемы, или же используете только традиционные фразы?
| Приемы улучшения памяти детей
Что делать для улучшения памяти детей? Приведенные ниже упражнения часто используются воспитателями детских садов и начальных классов школы для развития всех видов памяти у детей. Вожатые в летних лагерях также часто включают gриемы для улучшения памяти детей в комплекс развивающих мероприятий. Потренируйтесь и Вы со своим ребенком. «10 СЛОВ» Зачитайте ребенку список, например: утро, корова, летчик, лыжи, трамвай, река, картина, кольцо, садовник, карандаш. А затем попросите его повторить. Если дошкольник 6-7 лет в состоянии воспроизвести 5-6 слов — это замечательный показатель кратковременной памяти. Напомните ему те слова, которые он забыл. А примерно через час вернитесь к упражнению. Теперь пусть ребенок без подсказки вспомнит все, что он называл. Долговременная память считается очень хорошей, если малыш вспомнил хотя бы 7-8 слов. «ПОВТОРИ ЗВУКИ» Предложите ему закрыть глаза и не открывать их в течение минуты. МЕТОД ЦИЦЕРОНА, ИЛИ ВСЕМУ СВОЕ МЕСТО Заключается он в том, чтобы мысленно расположить образы, которые необходимо запомнить, в хорошо знакомом пространстве — например, в собственной комнате. Предложите ребенку запомнить 10 слов, к примеру: зонт, стрекоза, море, слон, конфета, сад, ворона, кастрюля, апельсин, ложка. И объясните, как все вышеперечисленное нужно «размещать» в помещении, чтобы потом без труда извлечь из памяти: «Большой зеленый зонт мы «повесим» на ручку двери, стрекозу увеличим до гигантских размеров и «посадим» на ковер, висящий на стене. Море пусть бушует в телевизоре, слон (его мы уменьшим до размеров спичечного коробка) будет прогуливаться под сенью фикуса, растущего на подоконнике. Огромную конфету в ярком фантике мы «разместим» на балконе — она так велика, что едва там помещается. Цветущий сад «разобьем» на полу. Ворону «посадим» на люстру». В итоге для того, чтобы воспроизвести потом цепочку слов, придется всего лишь восстановить в памяти интерьер родного жилища. Пользуясь этим методом, нужно соблюдать правило: маленькие предметы лучше увеличивать до больших размеров, а большие уменьшать (что мы и проделали со слоном и стрекозой) «10 КАРТИНОК» Возьмите 10 изображений различных предметов. Пусть ребенок рассмотрит их, а спустя 30 секунд назовет то, что удалось запомнить. 6-7 картинок из 10 -прекрасный результат для 6-7-летнего возраста. Затем покажите те картинки, о которых он забыл. А через час попросите вспомнить все изображения. Об отличных показателях долговременной памяти можно говорить, если названо 7 и более картинок. «НАЙДИ 10 ОТЛИЧИЙ» Хорошие результаты для улучшения памяти детей могут принести регулярно выполняемые задания из серии «Что изменилось на картинке?», «Найди два одинаковых предмета» и пр. Их без труда можно отыскать в развивающих книжках и детских журналах. Она особенно развита у потерявших зрение. Но ее можно и нужно тренировать всем. Мы запоминаем ощущения, которые испытываем, прикасаясь к чему-либо. Возьмите несколько предметов с различной поверхностью – деревянные и металлические, теплые и холодные, гладкие и шершавые. Предложите малышу закрыть глаза, потрогать их, а затем пусть он попытается угадать, что у него в руках СОЧИНЯЕМ РАССКАЗ Еще один способ запомнить как можно больше слов, картинок или предметов — придумать историю с их участием, связный рассказ, где каждому из элементов отведена роль. Предположим, перед ребенком разложен ряд карточек, на которых изображены кошка, книга, апельсин, месяц, кровать, мышь, шляпа и т. д. Рассказ малыша может быть таким: «Кошка читала книгу, на одной из страниц которой был нарисован апельсин. Наступил вечер, на небе появился месяц. Кошке захотелось спать, она отправилась в свою кроватку и заснула. Во сне она увидела мышь в шляпе». Выполняя это упражнение, необходимо учитывать, что слова между собой нужно связывать по порядку. И еще: чем невероятнее и забавнее получилась история, тем больше шансов, что ребенок воспроизведет все заданные слова. ЧУДЕСНЫЕ ПРЕВРАЩЕНИЯ Помните мультфильм про пластилиновую ворону, которая превращалась в корову, собаку, дворника и двух страусов — доброго и злого? Мнемотехнический прием, о котором пойдет речь, основан на том же принципе. Назовите первое слово и попросите ребенка во что-то мысленно его «превратить». У предмета или существа могут отрастать уши, лапы, хвост… В своем воображении малышу разрешено всячески изменять его форму, размер, цвет, совсем как если бы из большого комка пластилина он поочередно создавал разные фигурки. Например, первое слово «карандаш». Вдруг он начинает растягиваться, делается мягким, гибким, очень тонким. Затем скручивается, сворачивается — и вот уже перед нами клубок ниток, из которого начинают расти иголки. Клубочек оживает и превращается в ежика. В зависимости от возраста можно совершать от 10 до 20 чудесных превращений, после чего юному волшебнику предстоит вспомнить весь ряд слов: карандаш, клубок, ежик и т. д. Если с легкостью названы все, надо усложнить задачу — следующую цепочку сделать длиннее на 3-4 элемента. КСТАТИ Феноменальной слуховой памятью обладал Вольфганг Амадей Моцарт. 14-летним подростком он как-то оказался в соборе Святого Петра в Риме, где звучала прекрасная органная музыка, ноты которой держались в тайне. Придя домой, юный музыкант записал услышанное им произведение по памяти. И как позже выяснилось, не сделал ни единой ошибки! А зрительная память французского художника Гюстава Доре была тоже удивительна — живописец мог без труда написать точную копию картины, виденной им всего раз. Этот вид памяти напрямую зависит от нашей наблюдательности и способности к концентрации внимания. Развить столь ценные качества также помогут специальные упражнения |
 Особенно остро он встает с поступлением малыша в школу, где требуется запоминать большие объемы информации.
Особенно остро он встает с поступлением малыша в школу, где требуется запоминать большие объемы информации. Ваша задача — издать ряд звуков: пошуршать газетой, постучать ложечкой о стенку чашки, пощелкать пальцами, позвенеть в колокольчик… Попросите ребенка повторить изданные вами звуки в той последовательности, в которой он их услышал.
Ваша задача — издать ряд звуков: пошуршать газетой, постучать ложечкой о стенку чашки, пощелкать пальцами, позвенеть в колокольчик… Попросите ребенка повторить изданные вами звуки в той последовательности, в которой он их услышал.Несекретная формула Цицерона для убедительных разговоров | by SpeakerHub
«От оратора требуется острота логики, мудрость философов, почти поэтический язык, память юристов, голос трагиков, жест чуть ли не лучших актеров. Поэтому среди людей нет ничего более редкого, чем непревзойденный оратор ». -Cicero
Есть наука в убедительной речи, и это не секрет.
Вы можете подумать, что это невыполнимая формула, которую придумали только такие люди, как Джон Кеннеди, Стив Джобс и Тони Роббинс, и хотя нет никаких сомнений в их мастерстве, техника создания и выступления убедительных речей не является загадкой.
На самом деле, этой структуре около 2000 лет, как обрисовал римский философ Цицерон.
В диалоге «De Oratore» («Об ораторе»), написанном в 55 г. до н.э., Цицерон ясно описывает, как ораторы могут овладеть искусством сильного убеждения.
Эта техника включает 5 ключевых элементов и объединяет их в 6-этапный процесс, разработанный, чтобы помочь вам максимизировать вашу способность убеждать.
Прежде чем вы сможете начать свое выступление, вам нужно собрать нужные элементы.
Это 5 вещей, которые вам нужно сделать правильно , если вы хотите, чтобы ваш доклад был убедительным.
Invent [Inventio]
Сузьте свое ключевое сообщение, сформулируйте основные моменты и свяжите доказательства или ссылки с вашими точками.
Расположите [Dispositio]
Искусно расположите свои очки для максимального воздействия.
Здесь вы структурируете свою презентацию для максимальной убедительности.
Продолжайте читать, чтобы увидеть 6-частную формулу Цицерона для структурирования вашей презентации.
Стилизация [Elocutio]
Решите, как вы будете представлять каждую точку.
Будете ли вы использовать рассказы, цитаты, мультимедиа или статистику?
Выберите риторические приемы, которые вы будете использовать, и как ваши слова и предложения будут работать вместе.
Четко определите, какие переходы, шутки и истории вы будете использовать, и как они соотносятся с вашими мыслями и посланием.
Запоминание [Memoria]
Выучите и запомните свою речь, чтобы вы могли произносить ее без заметок.
Знайте свой доклад от и до, и исследуйте ответы на вопросы, которые могут вам задать во время вопросов и ответов или члены аудитории во время перерыва на кофе.
Убедитесь, что все цитаты, факты и статистика на 100% верны и запомнились.
Доставить [Действия]
Практика ведет к совершенству. Продумайте, как вы будете проводить презентацию, сосредоточив внимание на том, какие моменты вы подчеркнете жестами, тоном и темпом.
Убедитесь, что вы используете правильное произношение, и исключите ненужный жаргон или заполнители, чтобы каждое предложение было четким и плавным.
Теперь, когда у вас есть правильные строительные блоки, мы можем перейти к структурной формуле убедительной речи.
Вот 3 термина и их отношение к основным компонентам:
- Ethos (подумайте: этика): апеллирует к этике или морали аудитории.
- Логотипы (подумайте: логика) : обращается к эмоциям аудитории.
- Пафос (думает: эмоции): апеллирует к логике или интеллекту аудитории
Убедительная речь уравновешивает и подчеркивает этику, логотипы и пафос специально для аудитории.
В каждом выступлении есть 3 основных компонента: говорящий, речь и аудитория.
Цицерон говорит о том, как каждый из этих трех компонентов либо повлияет, либо отговорит вашу аудиторию от убеждения вас и вашего сообщения.
Аудитории нужны 3 вещи, чтобы ее убедить:
- Есть ли доверие к выступающему
- Эффективны ли аргументы, подтверждающие аргументы
- Насколько эмоционально вовлечена аудитория в тему и разговор.
Убедительная речь уравновешивает и подчеркивает этику, логотипы и пафос специально для аудитории.
Вот план Цицерона из 6 частей 2000-летней давности
1. Введение
Завоюйте доверие и убедите аудиторию идентифицировать себя с вами и вашим посланием.
Фокус: Ваш авторитет (этос).
2. Повествование
Четко и сразу изложите факты вашего аргумента.
В центре внимания: изложите свои аргументы (логотипы).
3. Подразделение
Объясните, что нужно доказать с обеих сторон аргумента.
Фокус: что вы пытаетесь доказать (логотипы).
4. Доказательство
Излагайте свои доводы по пунктам.
В центре внимания: объяснение доводов (логотипов).
5. Опровержение
Разбери аргумент оппонента.
Направление: устранение оппозиций (логотипов).
6. Заключение
Подведите итог своим сильным сторонам и вызовите эмоции.
Фокус: обращение к эмоциям вашей аудитории (пафос).
Хотите протестировать эти элементы? См. Широко распространенную речь здесь и попытайтесь разбить каждый компонент, используя вышеприведенный пошаговый подход.
Дополнительная литература:
Изначально это было размещено в блоге SpeakerHub.
Цицерон
Если вы используете Monocle 3, см. Документацию здесьАбстрактные
Cicero — это пакет R, который предоставляет инструменты для анализа доступности одноклеточного хроматина. эксперименты.Основная функция Цицерона — использовать данные о доступности одноклеточного хроматина для прогнозирования цис -регуляторные взаимодействия (например, между энхансерами и промоторами) в геноме посредством изучение совместной доступности. Кроме того, Cicero расширяет Monocle, чтобы обеспечить кластеризацию, упорядочивание и дифференциальный анализ доступности отдельных клеток с использованием доступности хроматина. Для получения дополнительной информации о Cicero , ознакомьтесь с нашими публикациями.
Введение
Основная цель Цицерона — использовать данные о доступности одноклеточного хроматина для прогнозирования областей геном, который с большей вероятностью находится в физической близости в ядре. Это может быть использовано для выявления предполагаемых пары энхансер-промотор, и чтобы получить представление об общей структуре cis -архитектуры геномного область.
Из-за разреженности данных по одной ячейке, ячейка должна быть агрегирована по сходству, чтобы обеспечить надежную коррекцию. для различных технических факторов в данных.
В конечном счете, Цицерон выставляет оценку «совместная доступность Цицерона» от -1 до 1 между каждой парой пики доступности в пределах определенного пользователем расстояния, где большее число указывает на более высокую совместную доступность.
Кроме того, пакет Cicero предоставляет расширенный инструментарий для анализа экспериментов ATAC-seq с одной ячейкой. используя фреймворк, предоставляемый Monocle. Эта виньетка представляет собой обзор рабочего процесса анализа ATAC-Seq одной ячейки с помощью Cicero.Для дальнейшего информацию и другие параметры см. на страницах руководства для пакета Cicero R, а также наши публикации.
Цицерон может помочь вам выполнить два основных типа анализа:
- Построение и анализ cis -регулирующих сетей. Цицерон анализирует совместную доступность для выявления предполагаемых регулятивных взаимодействий цис и использует различные методы для визуализации и анализа их.
- Общий анализ доступности одноклеточного хроматина. Cicero также расширяет программный пакет Monocle, позволяющий идентификация дифференциальной доступности, кластеризация, визуализация и реконструкция траектории с использованием данных о доступности одноклеточного хроматина.
Прежде чем мы рассмотрим функции Cicero для каждой из этих аналитических задач, давайте посмотрим, как установить Cicero.
Установка Cicero
Цицерон работает в среде статистических вычислений R.Вы будете требуется R версии 3.4 или выше и Cicero 1.0.0 или выше, чтобы иметь доступ к последние функции.
Установить из Bioconductor
Цицерон был недавно добавлен в Bioconductor. Он был выпущен как часть Bioconductor 3.8 и можно установить с помощью следующего кода:
если (! RequireNamespace ("BiocManager", quietly = TRUE))
install.packages ("BiocManager")
BiocManager :: install ("cicero") Установить с Github
Для получения самых последних обновлений пакета Cicero вы можете установить Cicero прямо из репозитория github. используя эти инструкции:
Цицерон основывается на пакете под названием Monocle.Перед установкой Цицерона сначала выполните эти инструкции установить Монокль.
Помимо Monocle, Cicero требует от Bioconductor следующих пакетов:
если (! RequireNamespace ("BiocManager", quietly = TRUE))
install.packages ("BiocManager")
BiocManager :: install (c ("Gviz", "GenomicRanges", "rtracklayer")) Теперь вы готовы к установке Cicero:
установить.пакеты ("инструменты разработчика")
devtools :: install_github ("cole-trapnell-lab / cicero-release") Загрузить Cicero
После установки проверьте правильность установки Cicero, открыв новый сеанс R и набрав:
библиотека (cicero) Получение помощи
Вопросы о Цицероне следует размещать на нашем сайте. Группа Google. Пожалуйста, не пишите технические вопросы непосредственно участникам Цицерона.
Рекомендуемый протокол анализа
Рабочий процесс Цицерона разбит на широкие этапы. Когда есть несколько способов сделать определенный шаг, мы обозначил варианты следующим образом:
| Обязательно | Вам нужно это сделать. |
| Рекомендовано | Из возможных способов сделать это мы рекомендуем сначала попробовать этот. |
| Альтернатива | Из всех возможных способов, этот способ может работать лучше, чем тот, который мы обычно рекомендуем. |
Загрузка данных
Класс CellDataSet
Цицерон хранит данные в объектах CellDataSet (CDS) класс. Класс является производным от Bioconductor ExpressionSet .
класс, который предоставляет общий интерфейс, знакомый тем, кто анализировал эксперименты с микрочипами с
Биопроводник. Monocle предоставляет подробную документацию о том, как создать входной CDS.
здесь.
Чтобы изменить объект CDS, чтобы он содержал доступность хроматина, а не данные выражения, Цицерон использует пики как
его особенности data fData , а не гены или транскрипты. В частности, многие функции Цицерона
требуется информация о пиках в форме chr1_103_103. Например, входная таблица fData может выглядеть
нравится:
| имя_сайта | хромосома | бп1 | бп2 | |
|---|---|---|---|---|
| chr10_100002625_100002940 | chr10_100002625_100002940 | 10 | 100002625 | 100002940 |
| chr10_100006458_100007593 | chr10_100006458_100007593 | 10 | 100006458 | 100007593 |
| chr10_100011280_100011780 | chr10_100011280_100011780 | 10 | 100011280 | 100011780 |
| chr10_100013372_100013596 | chr10_100013372_100013596 | 10 | 100013372 | 100013596 |
| chr10_100015079_100015428 | chr10_100015079_100015428 | 10 | 100015079 | 100015428 |
Загрузка данных из формата простой разреженной матрицы
Пакет Cicero включает в себя небольшой набор данных под названием cicero_data в качестве примера.
данные (cicero_data) Для удобства Цицерон включает функцию под названием make_atac_cds . Эта функция принимает в качестве входных данных data.frame или путь к файлу в формате разреженной матрицы. В частности, этот файл должен быть
текстовый файл с разделителями табуляции и тремя столбцами. Первый столбец — координаты пика в виде
«chr10_100013372_100013596», второй столбец — это имя ячейки, а третий столбец — целое число,
представляет количество считываний из этой ячейки, перекрывающих этот пик.В файле не должно быть строки заголовка.
Например:
| chr10_100002625_100002940 | ячейка1 | 1 |
|---|---|---|
| chr10_100006458_100007593 | ячейка2 | 2 |
| chr10_100006458_100007593 | ячейка3 | 1 |
| chr10_100013372_100013596 | ячейка2 | 1 |
| chr10_100015079_100015428 | ячейка4 | 3 |
Результатом make_atac_cds является действительный объект CDS, готовый для ввода в нижестоящий Цицерон.
функции.
input_cds <- make_atac_cds (cicero_data, binarize = TRUE) make_atac_cds
| Опция | По умолчанию | Банкноты |
|---|---|---|
преобразовать в двоичную форму | ЛОЖЬ | Логический, следует ли преобразовать матрицу подсчета в двоичную? Из-за редкости одноклеточных данных, мы обычно не ожидаем более 1 чтения на ячейку за пик.Мы обнаружили, что преобразование Матрица подсчета в двоичном формате «открыт ли этот сайт в этой ячейке» может в конечном итоге дать более четкие результаты. |
Загрузка данных 10X scATAC-seq
Если ваши данные scATAC-seq поступают с платформы 10x Genomics, вот пример создания ваших входных CDS. из вывода Cell Ranger ATAC. Интересующий результат будет в папке с именем filter_peak_bc_matrix .
# чтение данных матрицы с помощью пакета Matrix
indata <- Matrix :: readMM ("filter_peak_bc_matrix / matrix.mtx")
# преобразовать матрицу в двоичную форму
indata @ x [indata @ x> 0] <- 1
# форматировать информацию о ячейке
cellinfo <- read.table ("filter_peak_bc_matrix / barcodes.tsv")
row.names (cellinfo) <- cellinfo $ V1
имена (cellinfo) <- "ячейки"
# форматировать информацию о пике
пиковая информация <- таблица чтения ("фильтрованная_пик_bc_matrix / peaks.bed")
имена (пиковая информация) <- c ("chr", "bp1", "bp2")
peakinfo $ site_name <- paste (peakinfo $ chr, peakinfo $ bp1, peakinfo $ bp2, sep = "_")
ряд.имена (пиковая информация) <- пиковая информация $ имя_сайта
row.names (indata) <- row.names (пиковая информация)
colnames (indata) <- row.names (cellinfo)
# сделать компакт-диски
fd <- methods :: new ("AnnotatedDataFrame", data = peakinfo)
pd <- methods :: new ("AnnotatedDataFrame", data = cellinfo)
input_cds <- suppressWarnings (newCellDataSet (indata,
фенодата = pd,
featureData = fd,
выражениеFamily = VGAM :: binomialff (),
lowerDetectionLimit = 0))
input_cds @ expressionFamily @ vfamily <- "binomialff"
input_cds <- монокль :: detectGenes (input_cds)
# Убедитесь, что нет пиков с нулевыми показаниями
input_cds <- input_cds [Matrix :: rowSums (exprs (input_cds))! = 0,] Построение
сетей cis - регулирующих сетейЗапуск Цицерона
Создание компакт-дисков Цицерона Требуется
Поскольку данные о доступности одноклеточного хроматина крайне редки, точная оценка совместной доступности Scores требует, чтобы мы агрегировали похожие ячейки для создания более плотных данных подсчета.Цицерон делает это, используя Подход k-ближайших соседей, который создает перекрывающиеся наборы ячеек. Цицерон строит эти множества на основе уменьшенная размерная координатная карта подобия ячеек, например, из карты tSNE или DDRTree.
Вы можете использовать любой метод уменьшения размерности, чтобы основать агрегированный CDS. Мы покажем вам, как создайте две версии: tSNE и DDRTree (см. ниже). Доступны оба этих метода уменьшения размерности. из Монокля (загруженного Цицероном).
Когда у вас есть карта координат уменьшенного размера, вы можете использовать функцию make_cicero_cds , чтобы
создайте свой агрегированный объект CDS. Входными данными для make_cicero_cds является ваш входной объект CDS, и
ваша карта координат уменьшенного размера. Уменьшенная карта размеров Red_coordinates должна быть
в виде data.frame или матрицы , где имена строк соответствуют идентификаторам ячеек из
таблица pData вашего CDS.Столбцы уменьшенные_координаты должны быть
координаты объекта уменьшенного размера, например:
| ddrtree_coord1 | ddrtree_coord2 | |
|---|---|---|
| ячейка1 | -0,7084047 | -0,7232994 |
| ячейка2 | -4,4767964 | 0,8237284 |
| ячейка 3 | 1.4870098 | -0,4723493 |
Вот пример уменьшения размерности и создания CDS Цицерона. Используя монокль в качестве ориентира, Сначала мы находим координаты tSNE для нашего input_cds:
набор. Семян (2017)
input_cds <- detectGenes (input_cds)
input_cds <- EstimationSizeFactors (input_cds)
# *** если вы используете Monocle 3 alpha, вам также необходимо запустить следующую строку!
# ПРИМЕЧАНИЕ: Cicero еще не поддерживает бета-версию Monocle 3 (пакет monocle3).Мы надеемся
# скоро будет обновлено!
#input_cds <- preprocessCDS (input_cds, norm_method = "none")
input_cds <- reduceDimension (input_cds, max_components = 2, num_dim = 6,
сокращение_method = 'tSNE', norm_method = "none") Дополнительные сведения о приведенном выше коде см. На веб-сайте Monocle по адресу
кластеризация ячеек Затем мы получаем доступ к координатам tSNE из входного объекта CDS, где они хранятся в Monocle, и запускаем make_cicero_cds :
tsne_coords <- t (уменьшенныйDimA (input_cds))
ряд.имена (tsne_coords) <- row.names (pData (input_cds))
cicero_cds <- make_cicero_cds (input_cds, Reduced_coordinates = tsne_coords) Требуется запустить Цицерон
Основная функция пакета Cicero заключается в оценке совместной доступности сайтов в геноме для того, чтобы предсказывать цис- -регуляторных взаимодействий. Получить эту информацию можно двумя способами:
-
run_cicero: получить выходные данные Cicero со всеми значениями по умолчанию Функцияrun_ciceroвызовет каждую из соответствующих частей кода Цицерона, используя значения по умолчанию, и расчет параметров наилучшей оценки по ходу дела.Для большинства пользователей это будет лучшим местом для начала. - Функции вызова по отдельности для большей гибкости Для пользователей, которым нужна большая гибкость в вызываемые параметры и те, которые хотят получить доступ к промежуточной информации, Цицерон позволяет вам для вызова каждой из составных частей по отдельности.
Учитывать нестандартные параметры
Параметры по умолчанию предназначены для данных из клеток человека и мыши.Есть определенные нестандартные параметры, которые должен учитывать каждый пользователь, особенно пользователи, не использующие данные от людей. Прочтите раздел Важные соображения для данных, не относящихся к человеку, для получения дополнительной информации. run_cicero Рекомендуется Самый простой способ получить оценки совместной доступности Цицерона - запустить run_cicero . Бежать run_cicero , вам понадобится объект cicero CDS (созданный выше) и файл координат генома, который
содержит длину каждой хромосомы в вашем организме.Включены человеческие координаты hg19
с пакетом, и к нему можно получить доступ с помощью данных ("human.hg19.genome") . Вот пример вызова,
продолжая наш пример данных:
данные ("human.hg19.genome")
sample_genome <- subset (human.hg19.genome, V1 == "chr18")
conns <- run_cicero (cicero_cds, sample_genome) # Запуск занимает несколько минут
голова (conns) | Пик1 | Пик2 | доступ |
|---|---|---|
| chr18_10025_10225 | chr18_104385_104585 | 0.037 |
| chr18_10025_10225 | chr18_10603_11103 | 0,86971957 |
| chr18_10025_10225 | chr18_111867_112367 | 0,00000000 |
Вызов функций Цицерона индивидуально Альтернатива
Альтернативой вызову run_cicero является запуск каждой части конвейера Cicero по частям.В
Тремя функциями, составляющими конвейер Цицерона, являются:
-
параметр оценки_дистанции. Эта функция вычисляет расстояние Параметр штрафа, основанный на небольших случайных окнах генома. -
generate_cicero_models. Эта функция использует параметр расстояния определено выше и использует графический LASSO для расчета оценок совместной доступности перекрывающихся окон генома с использованием штрафа на основе расстояния. -
build_connections. Эта функция принимает в качестве входных данных выводgenerate_cicero_modelsи согласовывает перекрывающиеся модели для создания окончательного списка оценки совместной доступности.
Используйте справочные страницы в R (пример: ? Пример_дистанции_параметр ), чтобы увидеть все параметры. Ключ
параметры подробно описаны ниже:
параметр оценки_дистанции
| Опция | По умолчанию | Банкноты |
|---|---|---|
окно | 500000 | Параметр окна определяет, насколько большое окно (в парах оснований) в геноме используется для
расчет каждой отдельной модели.Этот параметр будет контролировать максимальное расстояние между сайтами.
которые сравниваются. Этот параметр должен быть таким же, как параметр окна для generate_cicero_models . |
sample_num | 100 | Это количество областей выборки, для которых требуется вычислить параметр расстояния. |
Distance_constraint | 250000 | Distance_constraint контролирует расстояние, на котором Цицерон ожидает мало значимых cis - контакты регулирующих органов. Estimation_distance_parameter использует это значение для оценки
параметр расстояния путем увеличения регуляризации до тех пор, пока не останется несколько контактов на расстоянии за пределами Distance_constraint . Distance_constraint должно быть достаточно ниже, чем параметр окна - как правило, установите размер окна не ниже
На 1/3 больше, чем ваш Distance_constraint . |
с | 0,75 | s - константа, отражающая степенное распределение контактных частот.
между разными участками генома в зависимости от их линейного расстояния. Для полного
обсуждение различных полимерных моделей ДНК, упакованных в ядро, и обоснованных ценностей.
для s мы отсылаем читателей к (Dekker et al., 2013). Мы используем значение 0,75 по умолчанию в
Цицерона, что соответствует полимерной модели ДНК «натяжной глобулы» (Sanborn et al., 2015). Для
данные не от людей, мы рекомендуем вам прочитать дальнейшее обсуждение этого параметра здесь:
Важный
Соображения относительно данных, не относящихся к человеку. Этот параметр должен быть таким же, как s Параметр для generate_cicero_models . |
generate_cicero_models
| Опция | По умолчанию | Банкноты |
|---|---|---|
окно | 500000 | Параметр окна определяет, насколько большое окно (в парах оснований) в геноме используется для
расчет каждой отдельной модели.Этот параметр будет контролировать максимальное расстояние между сайтами.
которые сравниваются. Этот параметр должен быть таким же, как параметр окна для параметр оценки_дистанции . |
параметр_расстоя | 100 | Distance_parameter управляет масштабированием регуляризации на основе расстояния
параметр в графическом LASSO.Этот параметр обычно является средним из рассчитанных значений выборки.
с использованием параметра Estimation_distance_parameter |
с | 0,75 | См. Выше в документации для параметра Estimation_distance_parameter . Этот параметр должен быть таким же, как параметр s для параметр оценки_дистанции . |
build_connections
| Опция | По умолчанию | Банкноты |
|---|---|---|
бесшумный | ЛОЖЬ | Логично, печатать ли сводную информацию. |
Визуализация связей Цицерона
Пакет Cicero включает общую функцию построения графиков для визуализации совместной доступности, называемую сюжетные связи .Эта функция использует
Фреймворк Gviz для черчения
графики в стиле браузера генома. Мы адаптировали функцию из
Пакет Sushi R для
отображение соединений. plot_connections имеет много опций, некоторые подробно описаны в
Раздел Advanced Visualization, но чтобы получить
основной сюжет из вашей таблицы совместной доступности довольно прост:
данные (gene_annotation_sample)
plot_connections (conns, "chr18", 8575097, 8839855,
gene_model = образец_гена_аннотации,
coaccess_cutoff =.25,
connection_width = .5,
collapseTranscripts = "самый длинный") Сравнение подключений Цицерона с другими наборами данных
Часто бывает полезно сравнить соединения Cicero с другими наборами данных с подобными типами соединений. Для
Например, вы можете сравнить результат Cicero с лигированием ChIA-PET. Для этого Цицерон включает
функция называется compare_connections . Эта функция принимает в качестве входных данных два фрейма данных соединения.
пар, conns1 и conns2 , и возвращает логический вектор соединений из conns1 найдено в conns2 .Сравнение в этой функции проводится с использованием
Геномные диапазоны
пакет, и использует аргумент max_gap из этого пакета, чтобы разрешить неаккуратные сравнения.
Например, если мы хотим сравнить наши прогнозы Цицерона с набором (выдуманных) соединений ChIA-PET, мы мог запустить:
chia_conns <- data.frame (Peak1 = c ("chr18_10000_10200", "chr18_10000_10200",
«chr18_49500_49600»),
Peak2 = c ("chr18_10600_10700", "chr18_111700_111800",
"chr18_10600_10700"))
голова (chia_conns)
# Peak1 Peak2
# 1 chr18_10000_10200 chr18_10600_10700
# 2 chr18_10000_10200 chr18_111700_111800
# 3 chr18_49500_49600 chr18_10600_10700
conns $ in_chia <- compare_connections (conns, chia_conns)
голова (conns)
# Peak1 Peak2 coaccess in_chia
# 2 chr18_10025_10225 chr18_10603_11103 0.85209126 ИСТИНА
# 3 chr18_10025_10225 chr18_11604_13986 -0.55433268 FALSE
# 4 chr18_10025_10225 chr18_49557_50057 -0.43594546 ЛОЖНО
# 5 chr18_10025_10225 chr18_50240_50740 -0,43662436 FALSE
# 6 chr18_10025_10225 chr18_104385_104585 0.00000000 FALSE
# 7 chr18_10025_10225 chr18_111867_112367 0,01405174 ЛОЖНО Вы можете обнаружить, что это перекрытие слишком строго при сравнении полностью различных наборов данных. Внимательно глядя,
2-я строка данных ChIA-PET довольно точно совпадает с последней показанной строкой conns.Разница в том
всего ~ 67 пар оснований, что может вызвать пик. Здесь max_gap Параметр может быть полезен:
conns $ in_chia_100 <- compare_connections (conns, chia_conns, maxgap = 100)
голова (conns)
# Peak1 Peak2 coaccess in_chia in_chia_100
# 2 chr18_10025_10225 chr18_10603_11103 0,85209126 ИСТИНА ИСТИНА
# 3 chr18_10025_10225 chr18_11604_13986 -0,55433268 FALSE FALSE
# 4 chr18_10025_10225 chr18_49557_50057 -0.43594546 FALSE FALSE
# 5 chr18_10025_10225 chr18_50240_50740 -0,43662436 FALSE FALSE
# 6 chr18_10025_10225 chr18_104385_104585 0.00000000 FALSE FALSE
# 7 chr18_10025_10225 chr18_111867_112367 0,01405174 ЛОЖНО ИСТИНА Кроме того, функция построения графиков Цицерона позволяет визуально сравнивать наборы данных. Для этого используйте сопоставление_трека аргумент. Фрейм данных сравнения должен включать третий
столбцы за первыми двумя столбцами пиков, называемые «coaccess».Вот как функция построения графика определяет
высота нанесенных соединений. Это может быть количественный показатель, например количество перевязок в
ЧИА-ПЭТ, или просто столбик единиц. Дополнительная информация о параметрах построения на страницах руководства ? Plot_connections и в Advanced
Раздел визуализации.
# Добавить столбец единиц под названием "coaccess"
chia_conns <- data.frame (Peak1 = c ("chr18_10000_10200", "chr18_10000_10200",
«chr18_49500_49600»),
Peak2 = c ("chr18_10600_10700", "chr18_111700_111800",
«chr18_10600_10700»),
coaccess = c (1, 1, 1))
plot_connections (conns, "chr18", 10000, 112367,
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0,
connection_width =.5,
сравнение_track = chia_conns,
include_axis_track = F,
collapseTranscripts = "самый длинный") Поиск
cis -Co-Accessibility Networks (CCANS) Помимо оценок попарной совместной доступности, у Цицерона есть функция поиска Cis -Co-accessibility
Сети (CCAN), которые представляют собой модули сайтов, которые очень доступны друг другу. Мы используем
Алгоритм обнаружения сообщества Лувена (Blondel et al., 2008), чтобы найти кластеры сайтов, которые, как правило,
совместный доступ. Функция generate_ccans принимает в качестве входных данных фрейм данных соединения и выводит
фрейм данных с назначениями CCAN для каждого входного пика. Сайты, не включенные в кадр выходных данных, не были
назначен CCAN.
Функция generate_ccans имеет один дополнительный вход, называемый coaccess_cutoff_override .
Когда coaccess_cutoff_override равен NULL, функция определит и сообщит соответствующий
пороговое значение показателя совместной доступности для генерации CCAN на основе общего количества CCAN при различных
отсечки.Вы также можете установить coaccess_cutoff_override как число от 0 до 1, чтобы переопределить
часть функции, определяющая обрезание. Эта опция полезна, если вы чувствуете, что отсечка найдена.
автоматически был слишком строгим или свободным, или для скорости, если вы повторно запускаете код и знаете, что отключение
будет, поскольку процедура нахождения отсечки может быть медленной.
CCAN_assigns <- generate_ccans (conns)
# [1] "Использовано ограничение совместной доступности: 0.24 "
голова (CCAN_assigns)
# Пик CCAN
# chr18_10025_10225 chr18_10025_10225 1
# chr18_10603_11103 chr18_10603_11103 1
# chr18_11604_13986 chr18_11604_13986 1
# chr18_49557_50057 chr18_49557_50057 1
# chr18_50240_50740 chr18_50240_50740 1
# chr18_157883_158536 chr18_157883_158536 1 Показатели активности гена Цицерона
Мы обнаружили, что часто доступность промоторов является плохим предиктором экспрессии генов.Однако, используя Цицерон, мы можем лучше понять общую доступность промоутера, и это ассоциированные дистальные участки. Эта комбинированная оценка региональной доступности лучше согласуется с генетической выражение. Мы называем эту оценку оценкой активности гена Цицерона, и она рассчитывается с использованием двух функций.
Начальная функция называется build_gene_activity_matrix . Эта функция принимает входные CDS и
список соединений Цицерона и выводит ненормализованную таблицу оценок активности генов. ВАЖНО : входной CDS должен иметь столбец в таблице fData под названием «ген», который указывает
ген, если этот пик является промотором, и NA, , если пик является дистальным. Один из способов добавить этот столбец:
показано ниже.
Результатом build_gene_activity_matrix является ненормализованный . Это должно быть нормализовано
используя вторую функцию под названием normalize_gene_activities .Если вы собираетесь сравнить ген
активности в разных наборах данных подмножеств данных, тогда все подмножества активности генов должны быть нормализованы
вместе, передав список ненормализованных матриц. Если вы хотите нормализовать только одну матрицу, просто
передать его функции самостоятельно. normalize_gene_activities также требует именованного вектора
от общего количества доступных сайтов на ячейку. Это легко найти в таблице pData вашего CDS, которая называется
"num_genes_expressed".См. Пример ниже. Нормализованные оценки активности генов варьируются от 0 до 1.
#### Добавьте столбец для таблицы fData, указывающий ген, если пик является промотором ####
# Создайте набор аннотаций генов, который помечает только сайты начала транскрипции
# гены. Мы используем это как прокси для промоутеров.
# Для этого нам нужен первый экзон каждого транскрипта
pos <- подмножество (gene_annotation_sample, strand == "+")
pos <- pos [порядок (pos $ start),]
pos <- pos [! duplicated (pos $ transcript),] # удалить все экзоны, кроме первых, в расшифровке
pos $ end <- pos $ start + 1 # сделать маркер 1 пары оснований TSS
neg <- subset (gene_annotation_sample, strand == "-")
neg <- neg [порядок (neg $ начало, уменьшение = ИСТИНА),]
neg <- neg [! duplicated (neg $ transcript),] # удалить все экзоны, кроме первых, в расшифровке
neg $ start <- neg $ end - 1
gene_annotation_sub <- rbind (pos, neg)
# Создайте подмножество столбцов аннотации TSS, содержащее только координаты
# и имя гена
gene_annotation_sub <- gene_annotation_sub [, c (1: 3, 8)]
# Переименуйте столбец символа гена в "ген"
имена (gene_annotation_sub) [4] <- "ген"
input_cds <- annotate_cds_by_site (input_cds, gene_annotation_sub)
голова (fData (input_cds))
# site_name chr bp1 bp2 num_cells_expressed ген перекрытия
# chr18_10025_10225 chr18_10025_10225 18 10025 10225 5 NA
# chr18_10603_11103 chr18_10603_11103 18 10603 11103 1 1 AP005530.1
# chr18_11604_13986 chr18_11604_13986 18 11604 13986 9 203 AP005530.1
# chr18_49557_50057 chr18_49557_50057 18 49557 50057 2331 RP11-683L23.1
# chr18_50240_50740 chr18_50240_50740 18 50240 50740 219 RP11-683L23.1
# chr18_104385_104585 chr18_104385_104585 18 104385 104585 1 NA
#### Создание оценок активности генов ####
# генерировать ненормализованную матрицу активности генов
unnorm_ga <- build_gene_activity_matrix (input_cds, conns)
# удалить все строки / столбцы со всеми нулями
unnorm_ga <- unnorm_ga [! Matrix :: rowSums (unnorm_ga) == 0,! Matrix :: colSums (unnorm_ga) == 0]
# составить список num_genes_expressed
num_genes <- pData (input_cds) $ num_genes_expressed
имена (num_genes) <- row.имена (pData (input_cds))
# нормализовать
cicero_gene_activities <- normalize_gene_activities (unnorm_ga, num_genes)
# если бы у вас было два набора данных для нормализации, вы бы передали оба:
Затем # num_genes должен включать все ячейки из обоих наборов
unnorm_ga2 <- unnorm_ga
cicero_gene_activities <- normalize_gene_activities (список (unnorm_ga, unnorm_ga2), num_genes)
Расширенная визуализация
Некоторые полезные параметры
Здесь мы покажем несколько примеров параметров построения графиков, которые вы, возможно, захотите использовать для дальнейшего изучения ваших данных.
визуально.Найдите документацию по всем параметрам на страницах руководства R, используя ? Сюжетные_соединения .
Точки обзора: Параметр точка обзора позволяет просматривать только соединения
происходящие из определенного места в геноме. Это может быть полезно при сравнении данных с данными 4C-seq.
plot_connections (conns, "chr18", 10000, 112367,
viewpoint = "chr18_48000_53000",
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0,
connection_width =.5,
сравнение_track = chia_conns,
include_axis_track = F,
collapseTranscripts = "самый длинный")
alpha_by_coaccess : параметр alpha_by_coaccess позволяет вам
полезно, когда вас беспокоит чрезмерное количество графиков. Этот параметр определяет альфа (прозрачность)
кривые соединений, масштабируемые в зависимости от степени совместной доступности.Сравните следующие два
сюжеты.
plot_connections (conns,
alpha_by_coaccess = ЛОЖЬ,
«chr18», 8575097, 8839855,
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0,1,
connection_width = .5,
collapseTranscripts = "самый длинный")
plot_connections (conns,
alpha_by_coaccess = ИСТИНА,
«chr18», 8575097, 8839855,
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0.1,
connection_width = .5,
collapseTranscripts = "самый длинный")
Цвета: Цвета имеют несколько параметров:
-
peak_color -
цвет_ сравнения -
цвет_соединения -
цвет_сравнения -
gene_model_color -
цвет_положения -
viewpoint_fill
peak_color и compare_peak_color , столбец должен соответствовать назначению цвета Peak1 . # Когда столбец цветов еще не содержит цветов, назначаются случайные цвета
plot_connections (conns,
«chr18», 10000, 112367,
connection_color = "in_chia_100",
сравнение_track = chia_conns,
peak_color = "зеленый",
сравнение_peak_color = "оранжевый",
сравнение_connection_color = "фиолетовый",
gene_model_color = "# 2DD881",
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0.1,
connection_width = .5,
collapseTranscripts = "самый длинный")
# Если мне нужна конкретная цветовая схема, я могу сделать столбец названий цветов
conns $ conn_color <- "оранжевый"
conns $ conn_color [conns $ in_chia_100] <- "зеленый"
plot_connections (conns,
«chr18», 10000, 112367,
connection_color = "conn_color",
сравнение_track = chia_conns,
peak_color = "зеленый",
сравнение_peak_color = "оранжевый",
сравнение_connection_color = "фиолетовый",
gene_model_color = "# 2DD881",
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0.1,
connection_width = .5,
collapseTranscripts = "самый длинный")
# Для раскраски пиков мне нужно, чтобы столбец цвета соответствовал пику 1:
conns $ peak1_color <- ЛОЖЬ
conns $ peak1_color [conns $ Peak1 == "chr18_11604_13986"] <- ИСТИНА
plot_connections (conns,
«chr18», 10000, 112367,
connection_color = "зеленый",
сравнение_track = chia_conns,
пик_цвет = "пик1_цвет",
сравнение_peak_color = "оранжевый",
сравнение_connection_color = "фиолетовый",
gene_model_color = "# 2DD881",
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0.1,
connection_width = .5,
collapseTranscripts = "самый длинный")
Настройка всего с помощью
return_as_list Мы понимаем, что вы можете захотеть отобразить другие типы данных вместе со связями Цицерона. Из-за этого мы
включить опцию return_as_list . Этот параметр позволяет использовать расширенный функционал
Гвиза, чтобы построить много разных
виды геномных данных.Увидеть
Руководство пользователя Gviz
чтобы увидеть множество вариантов.
Если для return_as_list
TRUE , изображение не будет выводиться на печать, и вместо этого будет
список компонентов сюжета будет возвращен. Вернемся к более простому примеру: plot_list <- plot_connections (conns,
«chr18», 10000, 112367,
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0.1,
connection_width = .5,
collapseTranscripts = "самый длинный",
return_as_list = ИСТИНА)
plot_list
# [[1]]
# CustomTrack ''
# [[2]]
# AnnotationTrack 'Пики'
# | геном: NA
# | активная хромосома: chr18
# | аннотаций: 7
# [[3]]
# Ось генома 'Axis'
# [[4]]
# GeneRegionTrack 'Модель гена'
# | геном: NA
# | активная хромосома: chr18
# | аннотаций: 33
Это составило список компонентов в порядке построения.Во-первых, это CustomTrack, то есть Цицерон. соединений, далее идет трек аннотации пика, затем трек оси генома и, наконец, модель гена отслеживать. Теперь я могу добавить еще одну дорожку, переставить дорожки или заменить дорожки с помощью Gviz:
сохранение <- UcscTrack (геном = "hg19", хромосома = "chr18",
track = "Сохранение", table = "phyloP100wayAll",
fontsize.group = 6, fontsize = 6, cex.axis = .8,
from = 10000, to = 112367, trackType = "DataTrack",
start = "start", end = "end", data = "score", size =.1,
type = "гистограмма", window = "auto", col.histogram = "# 587B7F",
fill.histogram = "# 587B7F", ylim = c (-1; 2,5),
name = "Сохранение")
# Я заменю трек оси генома на трек по природоохранным ценностям
plot_list [[3]] <- сохранение
# Чтобы сделать сюжет, я теперь буду использовать функцию Gviz plotTracks
# Включенные параметры являются значениями по умолчанию в plot_connections,
# но все можно изменить в соответствии с документацией Gviz
# Главный новый параметр, который вы должны включить, - это размеры
# параметр.Этот параметр определяет, какая доля
# высота вашего участка отведена под каждую дорожку. Размеры
# параметр должен быть вектором той же длины, что и plot_list
Gviz :: plotTracks (plot_list,
размеры = c (2,1,1,1),
от = 10000, до = 112367, хромосома = "chr18",
transcriptAnnotation = "символ",
col.axis = "черный",
fontsize.group = 6,
fontcolor.legend = "черный",
lwd = .3,
заглавие.ширина = 0,5,
background.title = "прозрачный",
col.border.title = "прозрачный")
Важные соображения в отношении данных, не относящихся к человеку
Параметры Цицерона по умолчанию были разработаны для использования человеком и мышью. Есть несколько параметров, которые мы Ожидается, что необходимо будет изменить для использования в различных модельных организмах. Вот параметры вместе с краткое обсуждение каждого:
Параметры, которые следует учитывать при обработке данных, не относящихся к человеку
| Параметр | Используемые функции | Банкноты | Возможные значения |
|---|---|---|---|
с | Estimation_distance_parameter , generate_cicero_models | Как обсуждалось ранее, значение с является масштабным показателем степенного закона.
функция, которая оценивает глобальный спад контактной частоты.Это значение обычно является оценочным.
с использованием контактных частот Hi-C. По умолчанию мы использовали 0,75, что соответствует
Полимерная модель ДНК «натяжная глобула» (Sanborn et al., 2015). Однако у других организмов
наблюдались различные функции распада. Например, у дрозофилы значение масштабирования 0,85
был предложен (Sexton et al., 2012). | Человек и мышь: 0.75 Дрозофила: 0,85 |
Distance_constraint | параметр оценки_дистанции | Значение Distance_constraint - это расстояние в парах оснований, за которым немногие
(менее 5%) предполагается наличие значимых регулирующих связей цис . Пока есть
в примерах очень дальних регулирующих контактов цис у различных организмов, это значение должно быть
более общее правило, так как Цицерон все еще может обнаруживать соединения на более дальние расстояния с высоким
совместная доступность. | Человек и мышь: 250 000 Дрозофила: 50 000 |
окно | Estimation_distance_parameter , generate_cicero_models | Окно Значение - это длина в парах оснований скользящего окна, которое Цицерон
будет использоваться при измерении совместной доступности. Это значение должно быть значительно больше (> 30%), чем
значение для Distance_constraint .Это максимальное расстояние сайтов, на которых
будет сравниваться. | Человек и мышь: 500000 Дрозофила: 100000 |
Одноячеечные траектории доступности
Вторая важная функция пакета Cicero - расширить Monocle 2 для использования с доступностью одной ячейки. данные. Основное препятствие, которое необходимо преодолеть с помощью данных о доступности хроматина, - это разреженность, поэтому большая часть расширения и методы предназначены для решения этой проблемы.
Построение траекторий с данными о доступности
Мы настоятельно рекомендуем вам обратиться к веб-сайту Monocle, особенно в этом разделе перед чтением описанного Цицероном расширения анализа Monocle. Вкратце, Monocle выводит псевдовременные траектории в три этапа:
- Выбор участков, определяющих прогресс
- Уменьшение размерности данных
- Упорядочивание ячеек в псевдовремя
Агрегация: основной метод решения проблемы разреженности
Основной способ, которым пакет Cicero справляется с разреженностью данных о доступности одноклеточного хроматина происходит через агрегацию. Агрегирование количества отдельных ячеек или отдельных пиков позволяет нам получить «консенсусная» матрица подсчета, уменьшающая шум и позволяющая нам выйти из двоичного режима. Под этим группировка, количество ячеек, в которых доступен конкретный сайт, можно смоделировать с помощью бинома распределения или, для достаточно больших групп, соответствующее гауссовское приближение.Моделирование сгруппировано счетчики доступности, как обычно распределенные, позволяют Цицерону легко настраивать их для произвольных технических коварирует, просто подбирая линейную модель и принимая остатки по ней как скорректированные оценка доступности для каждой группы ячеек. Ниже мы продемонстрируем, как применить эту группировку на практике.
aggregate_nearby_peaks Первичная агрегация, используемая для реконструкции траектории, находится между ближайшими пиками.Это сохраняет одиночные клетки
разделяются, агрегируя области генома и ища доступность хроматина внутри них. В
функция aggregate_nearby_peaks находит сайты на определенном расстоянии друг от друга и
объединяет их вместе, суммируя их подсчеты. В зависимости от плотности ваших данных вы можете попробовать
различное расстояние параметров. В опубликованных работах мы использовали 1000 и 10 000.
данные ("cicero_data")
input_cds <- make_atac_cds (cicero_data, binarize = TRUE)
# Добавляем метаданные ячеек
данные ("cell_data")
pData (input_cds) <- cbind (pData (input_cds), cell_data [row.имена (pData (input_cds)),])
pData (input_cds) $ cell <- NULL
ag_cds <- aggregate_nearby_peaks (input_cds, расстояние = 10000)
ag_cds <- detectGenes (agg_cds)
ag_cds <- EstimationSizeFactors (agg_cds)
agg_cds <- EstimationDispersions (agg_cds) Выбор сайтов, определяющих прогресс
Есть несколько вариантов выбора сайтов, которые будут использоваться при уменьшении размерности. Монокль имеет обсуждение вариантов здесь. Любой из этих вариантов может быть использован с вашей новой агрегированной CDS, в зависимости от информации, которую вы иметь доступный в вашем наборе данных.Здесь мы покажем два примера:
Выбор участков с помощью дифференциального анализа Альтернативный вариант
Если в ваших данных определены начальная и конечная точки, вы можете определить, какие сайты определяют прогресс, по
дифференциальный тест доступности. Мы используем функцию Monocle diffGeneTest для поиска
сайты, которые различаются по временным группам.
# Запуск занимает несколько минут
diff_timepoint <- DifferenceGeneTest (agg_cds,
fullModelFormulaStr = "~ момент времени + num_genes_expressed")
# Мы выбрали очень высокое пороговое значение q, потому что есть
# так мало сайтов в примере набора данных, в общем, q-значение
# отсечка в диапазоне 0.От 01 до 0,1 будет уместно
ordering_sites <- row.names (subset (diff_timepoint, qval <1)) Выбрать сайты по dpFeature Альтернатива
В качестве альтернативы вы можете выбрать сайты для уменьшения размерности с помощью Monocle's dpFeature метод. dpFeature выбирает сайты в зависимости от того, насколько они различаются среди кластеров ячеек. Здесь мы даем некоторый пример кода, воспроизведенный из Monocle, для получения дополнительной информации см. Описание монокля.
plot_pc_variance_explained (agg_cds, return_all = F) # Выбрать 2 ПК agg_cds <- reduceDimension (agg_cds,
max_components = 2,
norm_method = 'журнал',
num_dim = 3,
сокращение_method = 'tSNE',
многословный = T)
ag_cds <- clusterCells (agg_cds, verbose = F)
plot_cell_clusters (agg_cds, color_by = 'as.коэффициент (Кластер) ') clustering_DA_sites <- DifferenceGeneTest (agg_cds, # Занимает несколько минут
fullModelFormulaStr = '~ Кластер')
ordering_sites <-
row.names (clustering_DA_sites) [order (clustering_DA_sites $ qval)] [1: 1000] Уменьшите размерность данных и упорядочите ячейки
Как бы вы ни выбрали сайты для заказа, первым шагом к уменьшению размерности будет использование setOrderingFilter , чтобы отметить сайты, которые вы хотите использовать для уменьшения размерности.в
на следующих рисунках мы используем ordering_sites из Выберите участки с помощью дифференциального анализа выше.
agg_cds <- setOrderingFilter (agg_cds, ordering_sites) Затем мы используем DDRTree для уменьшения размерности, а затем упорядочиваем ячейки по траектории. Важно отметить, что мы используйте num_genes_expressed в нашей формуле остаточной модели для учета общей эффективности анализа.
agg_cds <- reduceDimension (agg_cds, max_components = 2,
остатокModelFormulaStr = "~ как.числовой (num_genes_expressed) ",
сокращение_method = 'DDRTree')
ag_cds <- orderCells (agg_cds)
plot_cell_trajectory (agg_cds, color_by = "timepoint") Когда у вас есть траектория клетки, вам нужно убедиться, что псевдовремя идет так, как вы ожидаете. В нашем Например, мы хотим, чтобы псевдовремя начиналось там, где большую часть времени находятся ячейки 0, и продолжалось в направлении более поздних временные точки. Дополнительную информацию об этом можно найти здесь, на сайте Monocle.Сначала мы раскрашиваем наш график траектории по State, как Monocle назначает сегменты дерева.
plot_cell_trajectory (agg_cds, color_by = "State") Из этого графика мы видим, что начало псевдовремени должно быть из состояния 4. Теперь мы переупорядочиваем ячейки. установив для корневого состояния значение 4. Затем мы можем проверить, что порядок имеет смысл, раскрасив график Псевдо-время.
agg_cds <- orderCells (agg_cds, root_state = 4)
plot_cell_trajectory (agg_cds, color_by = "Псевдо-время") Теперь, когда у нас есть значения Pseudotime для каждой ячейки ( pData (agg_cds) $ Pseudotime ), нам нужно назначить
эти значения возвращаются к нашему исходному объекту CDS.Кроме того, мы вернем информацию о состоянии обратно в
оригинальные компакт-диски.
pData (input_cds) $ Pseudotime <- pData (agg_cds) [colnames (input_cds),] $ Pseudotime
pData (input_cds) $ State <- pData (agg_cds) [colnames (input_cds),] $ State Анализ дифференциальной доступности
После того, как вы упорядочили свои клетки в псевдовремя, вы можете спросить, где в геноме доступность хроматина меняется во времени. Если вам известны конкретные сайты, которые важны для вашей системы, вы можете визуализировать доступность этих сайтов в псевдовремени.
Визуализация доступности в псевдовремя
plot_accessibility_in_pseudotime Для простоты мы исключим ветвь на нашей траектории, чтобы сделать нашу траекторию линейной.
input_cds_lin <- input_cds [, row.names (subset (pData (input_cds), State! = 5))]
plot_accessibility_in_pseudotime (input_cds_lin [c ("chr18_38156577_38158261", "chr18_48373358_48374180", "chr18_60457956_60459080")]) Выполняется
diffGeneTest с данными о доступности хроматина отдельных клеток В предыдущем разделе мы использовали агрегацию сайтов для обнаружения информации на уровне ячеек (псевдовремя ячейки).В этом разделе нас интересует статистика на уровне сайта (изменяется ли сайт в псевдовремя), поэтому
будем агрегировать похожие ячейки. Для этого у Цицерона есть полезная функция под названием aggregate_by_cell_bin .
aggregate_by_cell_bin Мы используем функцию aggregate_by_cell_bin , чтобы агрегировать наш входной объект CDS по столбцу в
Таблица pData. В этом примере мы назначим ячейки ячейкам, разрезая псевдовременную траекторию на 10 частей.
pData (input_cds_lin) $ cell_subtype <- вырезать (pData (input_cds_lin) $ Pseudotime, 10)
binned_input_lin <-aggregate_by_cell_bin (input_cds_lin, "подтип_ячейки") Теперь мы готовы запустить функцию Monocle DifferenceGeneTest для поиска сайтов, которые отличаются друг от друга. доступный через псевдовремя. В этом примере мы включаем num_genes_expressed в качестве ковариаты, чтобы вычесть ее эффект.
diff_test_res <- diffGeneTest (binned_input_lin,
fullModelFormulaStr = "~ см.ns (Псевдо-время, df = 3) + sm.ns (num_genes_expressed, df = 3) ",
ReducedModelFormulaStr = "~ sm.ns (num_genes_expressed, df = 3)", cores = 1) Полезные функции
annotate_cds_by_site Часто бывает полезно добавить дополнительные аннотации о ваших пиках к вашему объекту CDS. Например, вы можете
хотите знать, какие пики перекрывают экзон или сайт начала транскрипции. Цицерон включает функцию annotate_cds_by_site , который принимает в качестве входных данных ваш CDS и фрейм данных или путь к файлу с
информация о формате кровати (хромосома, bp1, bp2, дополнительные столбцы).Например, предположим, что у меня есть данные
( feat ) об эпигенетических метках в моей системе:
головка (fData (input_cds))
# site_name chr bp1 bp2 num_cells_expressed
# chr18_10025_10225 chr18_10025_10225 18 10025 10225 5
# chr18_10603_11103 chr18_10603_11103 18 10603 11103 1
# chr18_11604_13986 chr18_11604_13986 18 11604 13986 9
# chr18_49557_50057 chr18_49557_50057 18 49557 50057 2
# chr18_50240_50740 chr18_50240_50740 18 50240 50740 2
# chr18_104385_104585 chr18_104385_104585 18 104385 104585 1
feat <- данные.frame (chr = c ("chr18", "chr18", "chr18", "chr18"),
bp1 = c (10000, 10800, 50000, 100000),
bp2 = c (10700, 11000, 60000, 110000),
type = c («Ацетилированный», «Метилированный», «Ацетилированный», «Метилированный»))
голова (подвиг)
# chr bp1 bp2 type
# 1 chr18 10000 10700 Ацетилированный
# 2 chr18 10800 11000 Метилированный
# 3 chr18 50000 60000 Ацетилированный
# 4 chr18 100000 110000 Метилированный Я могу использовать annotate_cds_by_site, чтобы определить, какой из моих пиков имеет эти эпигенетические отметки.
temp <- annotate_cds_by_site (input_cds, feat)
голова (fData (темп))
# site_name chr bp1 bp2 num_cells_expressed тип перекрытия
# chr18_10025_10225 chr18_10025_10225 18 10025 10225 5201 Ацетилированный
# chr18_10603_11103 chr18_10603_11103 18 10603 11103 1 201 Метилированный
# chr18_11604_13986 chr18_11604_13986 18 11604 13986 9 NA
# chr18_49557_50057 chr18_49557_50057 18 49557 50057 2 58 Ацетилированный
# chr18_50240_50740 chr18_50240_50740 18 50240 50740 2501 Ацетилированный
# chr18_104385_104585 chr18_104385_104585 18 104385 104585 1 201 Метилированный Эта функция добавила два столбца по сравнению с приведенным выше.Перекрытие представляет собой количество пар оснований
перекрытие между интервалом в feat и заданным пиком, а type - это присвоенный статус
на основе перекрытия. Если присмотреться, то сайт chr18_10603_11103 фактически перекрывался двумя
интервалы в подвиг . В режиме по умолчанию annotate_cds_by_site выберет
наибольший интервал перекрытия для отчета. Если вы хотите видеть все перекрывающиеся интервалы, вы можете установить все отметки до ИСТИНА .
temp <- annotate_cds_by_site (input_cds, feat, all = TRUE)
голова (fData (темп))
# site_name chr bp1 bp2 num_cells_expressed тип перекрытия
# chr18_10025_10225 chr18_10025_10225 18 10025 10225 5201 Ацетилированный
# chr18_10603_11103 chr18_10603_11103 18 10603 11103 1 98,201 Ацетилированный, метилированный
# chr18_11604_13986 chr18_11604_13986 18 11604 13986 9 NA
# chr18_49557_50057 chr18_49557_50057 18 49557 50057 2 58 Ацетилированный
# chr18_50240_50740 chr18_50240_50740 18 50240 50740 2501 Ацетилированный
# chr18_104385_104585 chr18_104385_104585 18 104385 104585 1 201 Метилированный Как вы видите выше, когда все установлены на ИСТИНА , все перекрывающиеся интервалы
сообщил.
find_overlapping_coordinates Наконец, вы можете просто узнать, какие из ваших пиков перекрывают конкретную область генома. Для этого
Цицерон включает функцию find_overlapping_coordinates .
find_overlapping_coordinates (fData (temp) $ site_name, "chr18: 10,100-10,604")
# [1] "chr18_10025_10225" "chr18_10603_11103"
Часто задаваемые вопросы
Где мне взять файл genome_coordinates для моего генома / сборки?
Файлы genome_coordinates - это просто таблица хромосом и их размеров.Вы можете найти один для вашего генома / построить на веб-сайте браузера генома USCS. Иди сюда, найдите ссылку «Полный набор данных» для интересующего вас генома и найдите файл [genome] .chrom.sizes. Загрузите это и пройдите путь к функции Цицерона, которую вы выполняете! Примечание: некоторые геномы содержат много нестандартных хромосом в файле размеров. (chr_unk, альтернативные гаплотипы и т. д.). Вы можете удалить эти строки из своего файла, что поможет ускорить ваш бег.
Где я могу взять ген_модель / gene_annotation_sample для моего генома / сборки?
Gene_model для перехода к функциям построения графиков может быть получен из ENSEMBL GTF для вашего организм / строение.Загрузите файл GTF отсюда - нашел в столбце «Генные наборы». Файлы GTF нуждаются в небольшой обработке, чтобы быть готовыми к построению:
# загрузить ваши данные с помощью rtracklayer
gene_anno <- rtracklayer :: readGFF ("Путь / Кому / Загружено / GTF.GTF")
# переименовать некоторые столбцы в соответствии с требованиями к графику
gene_anno $ chromosome <- paste0 ("chr", gene_anno $ seqid)
gene_anno $ gene <- gene_anno $ gene_id
gene_anno $ transcript <- gene_anno $ transcript_id
gene_anno $ symbol <- gene_anno $ имя_гена Цитата
Если вы используете Цицерона для анализа своих экспериментов, процитируйте, пожалуйста: цитата («Цицерон»)
# Ханна А.Плинер, Джей Шендур и Коул Трапнелл и др. al. (2018). Цицерон
# Предсказывает цис-регуляторные взаимодействия ДНК из одноклеточного хроматина
# Данные о доступности. Molecular Cell, 71, 858 - 871..e8.
# Запись BibTeX для пользователей LaTeX
# @Статья{,
# title = {Цицерон предсказывает цис-регуляторные взаимодействия ДНК на основе данных о доступности одноклеточного хроматина},
# journal = {Молекулярная клетка},
# volume = {71},
# number = {5},
# pages = {858 - 871.e8},
# year = {2018},
# issn = {1097-2765},
# doi = {https: // doi.org / 10.1016 / j.molcel.2018.06.044},
# author = {Ханна А. Плинер, Джонатан С. Пакер и Хосе Л. Макфалин-Фигероа и
# Даррен А. Кусанович и Риза М. Даза, Деласа Агамирзайе и Санджай Шривацан
# и Сяоцзе Цю, и Дана Джексон, и Анна Минкина, и Эндрю С. Адей, и Фрэнк Дж.
# Стимерс, Джей Шендур и Коул Трапнелл},
#}
Благодарности
Цицерон был разработан Ханной Плинер в лабораториях Коула Трапнелла и Джея Шендура.Эта виньетка была создана на основе документа стиля виньетки Вольфганга Хубера «Биокондуктор» и сделана по образцу виньетка для DESeq Саймона Андерса и Вольфганга Хубера.
Список литературы
Блондель В.Д., Гийом Ж.-Л., Ламбьотт Р. и Лефевр Э. (2008). Быстрое разворачивание сообщества в больших сетях.
Деккер, Дж., Марти-Реном, М.А., Мирный, Л.А. (2013). Изучение трехмерной организации геномов: интерпретация данных взаимодействия хроматина. Nat. Преподобный Жене. 14, 390–403.
Санборн, А.Л., Рао, С.С.П., Хуанг, С.-К., Дюран, Н.К., Хантли, М.Х., Джуэтт, А.И., Бочков, И.Д., Чиннаппан Д., Каткоски А., Ли Дж. И др. (2015). Экструзия хроматина объясняет ключевые особенности образования петель и доменов в геномах дикого типа и сконструированных геномах. . Proc. Natl. Акад. Sci. США. 112, E6456 – E6465.
Секстон, Т., Яффе, Э., Кенигсберг, Э., Бантиньи, Ф., Леблан, Б., Хойчман, М., Парринелло, Х., Танай, А., и Дж. Кавалли (2012). Трехмерное складывание и принципы функциональной организации генома дрозофилы.. Ячейка 148: 3, 458-472.
Пять канонов риторики: для улучшения коммуникации
Изобретение
Изобретение - это процесс придумывания того, что вы хотите сказать, чтобы убедить вашу аудиторию в вашей точке зрения. Какие ключевые сообщения и моменты помогут вам убедить аудиторию в своей точке зрения?
Для того, чтобы хорошо пройти этот этап, требуется ясность цели и понимание предмета и вашей аудитории. На этом этапе вам также необходимо выбрать стиль презентации (а теперь и среду) и решить, какой длины должна быть ваша презентация.
Аранжировка
Речи, как и музыка, должны быть аккуратно аранжированы.Аранжировка - это процесс структурирования вашего контента. Вам нужно привести в порядок все великие вещи, о которых вы думали на стадии изобретения, чтобы они работали вместе и помогали вам донести свое сообщение и убедить вашу аудиторию.
Современная аранжировка обычно состоит из трех этапов: введения, тела и заключения. Классическая схема, которую использовал бы Цицерон, состояла из пяти этапов: введение, констатация нейтральных фактов, аргументация, опровержение альтернативных позиций, завершение презентации.Эту схему можно использовать, если хотите, хотя большинство людей придерживается трехэтапного подхода.
Важно продумать организацию всех форм и средств коммуникации и убедиться, что то, что вы выбираете, подходит вашей аудитории и выбранной вами среде.
Стиль
Стиль - это процесс выбора языка и построения вашей презентации так, чтобы вызвать эмоциональный отклик. Это пафосная часть риторического треугольника.
Красноречие и структурирование помогают достичь этого результата, равно как и умелое использование эмоционального языка и риторических приемов, таких как аналогия, аллюзия и аллитерация.
Юлий Цезарь был современником Цицерона.Память
Память связана с тем, чтобы запоминать достаточно, чтобы вы могли выступать полностью и плавно, без заметок. Это было необходимо в римскую эпоху, когда писались каноны и ораторам приходилось говорить часами. Хотя сейчас это, возможно, немного менее важно, это все еще очень полезный навык.
Многие великие ораторы заранее визуализируют свои презентации, проводят «генеральные репетиции», исследуют свое окружение и понимают несколько уровней своих презентаций (от полного текста до нескольких ключевых пунктов).
Поставка
Каноны используются и сегодня.Доставка - последний из пяти канонов риторики. Это предполагает использование всех доступных вам инструментов для эффективного общения. Мы знаем, что слова - это лишь крошечная часть коммуникации (см. Модель коммуникации 7-38-55), и что для максимальной эффективности в качестве коммуникаторов нам необходимо использовать ряд методов и инструментов.
Акцент, тон голоса, изменение темпа, паузы, громкость, жестикуляция, язык тела, расположение и поддержка - все это инструменты, которые помогут эффективно изложить ваши аргументы.
Многоуровневая система поддержки (MTSS)
Успешное внедрение MTSS требует приверженности многих людей и групп людей, которые работают в рамках систематической системы. Далее следуют краткие описания ролей и обязанностей этих лиц и групп.
Роль групп по решению проблем (PST) в MTSS
Школы часто используют более одного подхода или вмешательства на определенном уровне, как это определено командами по решению проблем.Целью PST является анализ данных об учащихся и принятие учебных решений для учащихся всех трех уровней.
Уровень 1 Важной обязанностью команды является определение эффективности основной учебной программы и инструкций. Если на Уровне 1 менее 80% студентов, то PST несут ответственность за поддержку PLC в определении способов поддержки основной учебной программы. Они также встречаются, чтобы оказать поддержку учащимся, испытывающим академические или поведенческие трудности в школе.Для этих студентов команда отвечает за реализацию подхода к решению проблем, чтобы определить вмешательство в ответ на потребности учащихся и измерить эффективность вмешательств, которые они предписывают.
Данные мониторинга успеваемости используются для определения того, отреагировал ли студент на инструкции на любом уровне многоуровневой системы поддержки или нет. Увеличение интенсивности вмешательства может быть достигнуто несколькими способами, такими как удлинение учебного времени, увеличение частоты учебных занятий, уменьшение размера учебной группы или корректировка уровня обучения.
Кроме того, интенсивность может быть увеличена путем оказания интервенционной поддержки со стороны учителя, обладающего большим опытом и навыками в обучении учащихся с трудностями в обучении или поведении (например, специалист по чтению или специальный педагог).
Мониторинг прогресса и другие данные, собранные в ходе предоставленного вмешательства, должны быть изучены в процессе оценки вместе с данными из различных источников.
Роль классного руководителя
Классные учителя играют решающую роль в успешном внедрении MTSS для своих учеников.Ожидается, что классные учителя будут использовать основанные на исследованиях основные учебные программы и инструкции по всем предметам. Кроме того, если ученику требуется дополнительная поддержка, классные учителя обеспечивают, чтобы его ученики получали необходимую поддержку. Часто этот процесс приводит к тому, что классный руководитель оказывает поддержку Уровня 2 в своих классах, но он также может прибегать к помощи вспомогательного персонала, чтобы приспособиться к расписанию учеников. Мероприятия Уровня 2, ПРЕДОСТАВЛЯЕМЫЕ ДОПОЛНИТЕЛЬНО К ОСНОВНОЙ УЧЕБНОЙ ПРОГРАММЕ, обычно включают обучение в малых группах для удовлетворения выявленных потребностей учащихся.Учащиеся, которые адекватно реагируют на вмешательства Уровня 2, продолжают обучение по основному обучению с постоянным мониторингом успеваемости. Учащиеся, которые проявляют минимальную реакцию на вмешательства Уровня 2, могут перейти на Уровень 3, где более интенсивная и индивидуальная поддержка предоставляется определенным персоналом и координируется классным учителем. Мониторинг успеваемости для студентов Уровня 3 обычно проводится чаще (т. Е. Не реже одного раза в неделю), чем для студентов Уровня 2, из-за серьезности потребностей студентов Уровня 3.
Cicero предсказывает цис-регуляторные взаимодействия ДНК на основе данных о доступности хроматина одиночных клеток.
Резюме
Связывание регуляторных элементов ДНК с их генами-мишенями, которые могут находиться на расстоянии сотен килобаз, остается сложной задачей. Здесь мы представляем Cicero, алгоритм, который идентифицирует совместимые пары элементов ДНК, используя данные о доступности одноклеточного хроматина, и таким образом связывает регуляторные элементы с их предполагаемыми генами-мишенями. Мы применяем Цицерона для исследования того, как динамически доступные элементы организуют регуляцию генов при дифференцировке миобластов.Группы связанных с Цицероном регуляторных элементов соответствуют критериям «хроматиновых хабов» - они обогащены для физической близости, взаимодействуют с общим набором факторов транскрипции и претерпевают согласованные изменения в гистоновых метках, которые предсказывают изменения в экспрессии генов. Псевдотемпоральный анализ показал, что большинство элементов ДНК остаются в центрах хроматина на протяжении всей дифференцировки. Подмножество элементов, связанных с MYOD в миобластах, обнаруживает раннее открытие PBX1- и MEIS1-зависимым образом. Эта стратегия может применяться для анализа архитектуры, детерминант последовательности и механизмов цис-регуляции в масштабе всего генома.
Введение
Доступность хроматина - мощный маркер активной регуляторной ДНК. У эукариот доступность хроматина как на промоторах, так и на дистальных элементах определяет, где факторы транскрипции (TFs) связаны вместо нуклеосом (Felsenfeld et al., 1996). Полногеномный анализ доступности хроматина, измеренный по гиперчувствительности к ДНКазе, показал, что репертуар доступных регуляторных элементов представляет собой высокоспецифичную молекулярную сигнатуру клеточных линий и тканей (Thurman et al., 2012). Кроме того, полногеномные ассоциативные исследования (GWAS) показывают, что значительная часть генетического риска распространенных заболеваний приходится на доступные области в тканях или типах клеток, имеющих отношение к заболеванию (Gusev et al., 2014; Maurano et al., 2012).
Несмотря на его важность, нам по-прежнему не хватает количественного понимания того, как изменения в доступности хроматина связаны с изменениями в экспрессии близлежащих генов. Предпосылкой для такого понимания является карта, которая связывает дистальные регуляторные элементы с их генами-мишенями.С этой целью мы разработали Cicero, алгоритм, который генерирует такие связи на основе всего генома на основе паттернов совместимости в данных отдельных клеток.
Мы демонстрируем возможности Цицерона посредством анализа дифференцировки скелетных миобластов, который остается одной из наиболее охарактеризованных моделей регуляции генов в развитии позвоночных. Дифференцировка миобластов управляется основным набором TF, включая MYOD и MEF2 (Molkentin et al., 1995), которые регулируют экспрессию тысяч генов, когда клетки выходят из клеточного цикла, выравниваются и сливаются с образованием мышечных трубок.Здесь мы использовали комбинаторную индексацию одиночных клеток ATAC-seq (sci-ATAC-seq) на 13 367 клетках, чтобы идентифицировать 329 020 доступных элементов в миобластах, почти 22 000 из которых открываются или закрываются во время дифференцировки. Применительно к этим данным Цицерон связал большинство динамических сайтов с одним или несколькими предполагаемыми целевыми генами. Из полученной в результате cis -регуляторной карты мы можем предсказать изменения в экспрессии генов на основе динамики доступности хроматина связанных дистальных элементов.
Дизайн
В отличие от предыдущих подходов, которые полагаются на большой сборник данных о доступности хроматина, полученных во многих клеточных линиях или тканях (Thurman et al., 2012, Budden et al., 2015), мы искали метод, который работал бы с данными о доступности хроматина отдельных клеток из одного эксперимента, и который был устойчив к разреженности этих данных. Цицерон использует выборку и агрегацию групп похожих ячеек, чтобы учесть технические затруднения и количественно оценить корреляции между предполагаемыми регулирующими элементами. Основываясь на этих корреляциях, Цицерон связывает регуляторные элементы с целевыми генами, используя неконтролируемое машинное обучение. Алгоритм может быть применен к любому типу клеток и организму, для которых доступны секвенированный геном и данные о доступности хроматина отдельной клетки.Поскольку он принимает в качестве входных данных данные об отдельных клетках, Цицерон в принципе может работать со сложными смесями различных типов клеток, которые встречаются в тканях.
Результаты
Траектории доступности хроматина и экспрессии генов во время дифференцировки миобластов очень похожи
Мы выполнили временной график дифференцировки на миобластах скелетных мышц человека (HSMM), собирая клетки через 0, 24, 48 и 72 часа после переключения. от питательной среды к среде дифференциации (). С помощью оптимизированного sci-ATAC-seq (Cusanovich et al., 2018), мы профилировали доступность хроматина в 13,367 клетках в 2 независимых экспериментах. Агрегированные данные ATAC-seq для отдельных клеток были в высокой степени согласованы как с объемными данными ATAC-seq, так и с опубликованными данными гиперчувствительности к DNaseI из миобластов и мышечных трубок (дополнительный рисунок 1A, B) (Консорциум проектов ENCODE, 2012). Чтобы определить доступные области, мы объединили показания всех клеток из каждого эксперимента и вызвали пики с помощью MACS 2 (Zhang et al., 2008). Подавляющее большинство пиков были общими для разных экспериментов (дополнительный рисунок 1B), поэтому мы использовали единый объединенный набор пиков для всех последующих анализов.После исключения 7538 клеток, помеченных как вероятные интерстициальные фибробласты на основании отсутствия доступности промотора в каком-либо из нескольких известных мышечных маркеров (56%, пропорция аналогична нашей оценке по одноклеточной последовательности РНК в этой системе (Qiu et al., 2017a) )), мы идентифицировали 329 020 сайтов, доступных в мышечных клетках. Каждая клетка имела считывания, перекрывающиеся в среднем с 3,466 доступными сайтами проксимального промотора и 9,055 доступными сайтами дистального конца (дополнительный рисунок 1C).
Дифференцирующиеся миобласты следуют сходным траекториям доступности хроматина отдельных клеток и экспрессии генов. A ) Профили доступности одноклеточного хроматина для миобластов скелетных мышц человека (HSMM) были сконструированы с помощью sci-ATAC-seq. Загрязняющие интерстициальные фибробласты (часто встречающиеся в культурах HSMM) информативно удаляли перед дальнейшим анализом. B ) Агрегированный охват считыванием из экспериментов sci-ATAC-seq в области, окружающей TNNT1 и TNNI3, в миобластах (0 часов) и мышечных трубках (72 часа). Объемный ATAC-seq, полученный из тех же скважин, что и эксперимент 2, показан рядом с DNase-seq из ENCODE для сравнения (эксперименты ENCODE ENCSR000EOO и ENCSR000EOP (Консорциум проектов ENCODE, 2012)). C ) Траектория отдельной клетки, выведенная из 2725 профилей sci-ATAC-seq миобластов из эксперимента 1 с помощью Monocle (см. Методы). В последующих панелях и по всей статье мы исключаем ячейки на ветви до результата F 2 , если не указано иное. На вставке показана траектория sc-RNA-seq, описанная для HSMM (воспроизведена из (Qiu et al., 2017a), клетки были из той же партии и культивировались в условиях, идентичных условиям для sci-ATAC-seq). D ) Распределение клеток в псевдовремени доступности хроматина от корня до исхода траектории F 1 . E ) Процент дифференцирующихся клеток, промоторы которых для выбранных генов доступны в псевдовремя. Черная линия указывает псевдовременное среднее значение сглаженной биномиальной регрессии. F ) Процент клеток, промоторы которых для выбранных генов в E доступны в фибробластах, собранных в ростовой среде (GM) или среде дифференцировки (DM), а также в миобластах, локализованных в ветви F 2 . См. Также рисунок S1.
Далее мы попытались охарактеризовать изменения доступности хроматина при дифференцировке миобластов.Однако анализ дифференциации на основе данных временных рядов затруднен из-за асинхронности, , то есть парадокса Симпсона (Simpson, 1951). Чтобы преодолеть это, мы недавно разработали технику «псевдовременного переупорядочения» (или «псевдовремени»), которая использует машинное обучение для организации клеток в соответствии с их прогрессом через дифференцировку (Trapnell et al., 2014). Хотя наш алгоритм, Monocle 2, был разработан для транскриптомов отдельных клеток (Qiu et al., 2017a), мы смогли адаптировать его к данным sci-ATAC-seq с простыми модификациями (см. Методы).
Монокль независимо разместил клетки из каждого эксперимента по аналогичным траекториям с двумя результатами (обозначены F 1 и F 2 ) (, дополнительный рисунок 1D). Эти траектории аналогичны траектории, построенной из транскриптомов одиночных клеток в нашей предыдущей работе (Qiu et al., 2017a) ( врезка ). Клетки, собранные из питательной среды, падали почти исключительно в начале траекторий, в то время как клетки из более поздних временных точек были распределены по своей длине ().На пути к F 1 промоторы хорошо известных миогенных регуляторов и структурных компонентов мышцы открылись (стали более доступными), тогда как промотор ID1 , хорошо охарактеризованный репрессор дифференцировки миобластов (Benezra et al., 1990), закрытый (). Подобно траектории одиночных клеток RNA-seq (Qiu et al., 2017a), ряд клеток был расположен на ветви, ведущей к альтернативному исходу F 2 . То, что эти клетки доступны на промоторе MYOD1 , но не на промоторе MYh4, предполагает, что они представляют собой «резервные миобласты», которые не полностью дифференцировались (Yoshida et al., 1998) (). Сходные траектории, построенные Monocle из трех независимых экспериментов, а также тесное соответствие между кинетикой экспрессии и доступностью хроматина для ключевых мышечных генов, подтверждают точность псевдовременного упорядочения Monocle.
Дистальные элементы ДНК динамически доступны во время дифференцировки миобластов
Дифференциальный анализ выявил значительные псевдовременные изменения доступности на 21 678 из 329 020 (6,6%) сайтов во время дифференцировки миобластов (дополнительный рисунок 2A).Кроме того, мы провели аналогичный дифференциальный анализ ранее опубликованных данных одноклеточной последовательности РНК из той же системы (Trapnell et al., 2014). Из «динамических» доступных сайтов только 1324 (6,1%) были промоторами (), из которых 92 перекрывались с 1464 дифференциально экспрессируемыми транскриптами (FDR <5%) посредством одноклеточной РНК-seq. Из 64 промоторов с непреходящими изменениями как доступности, так и экспрессии генов 62 (97%) были согласованно по направлению. Из 20 354 дистальных, динамически доступных сайтов 68% были аннотированы как энхансеры в миобластах или мышечных трубках (Libbrecht et al., 2016), по сравнению с 36% всех доступных сайтов ().
Тысячи элементов ДНК динамически доступны во время дифференцировки миобластов. A ) Сглаженные кривые доступности, зависящие от псевдодоступности, созданные с помощью отрицательной биномиальной регрессии и масштабированные как процент от максимальной доступности каждого сайта. Кривая регрессии аналогична регрессии для дифференциальной доступности (см. Методы). Каждая строка указывает на отдельный элемент ДНК. Сайты сортируются по псевдовремени, в которое они впервые достигают половины максимальной доступности. B ) Соотношение динамических и статических сайтов по типу сайта. Цвет указывает, является ли сайт проксимальным к промотору (см. Методы), дистальным энхансером (определенным как пики, которые не проксимально проксимальным к промотору и аннотируются Segway как энхансеры в миобластах или мышечных трубках) или другим дистальным (оставшиеся сайты). C ) Процент сайтов, сообщаемых как связанные MyoD в миобластах или мышечных трубках (Cao et al., 2010). D ) Обогащение мотивов в доступных сайтах. P-значения являются результатом моделей логистической регрессии, которые используют наличие или отсутствие заданного мотива на каждом сайте, чтобы предсказать, имеет ли сайт заданную тенденцию доступности (открытие / закрытие / статика).Графики показывают до 6 главных мотивов, значимых для Бонферрони, по значению p. E ) Подсчет сайтов, претерпевающих значительные изменения в ацетилировании h4K27, как измерено с помощью ChIP-Seq (Tang et al., 2015). См. Также рисунок S2.
Используя анализ обогащения набора генов, мы обнаружили, что гены, связанные с сокращением и другими связанными с мышцами функциями, были сильно обогащены среди генов со значительно открывающимися промоторными областями. Напротив, промоторы для генов, связанных с клеточным циклом, которые подавляются на ранних этапах дифференцировки, были лишь незначительно обогащены среди дифференциально доступных сайтов (дополнительный рисунок 2B).Большинство маркеров активно пролиферирующих клеток не показали значительных изменений в доступности промотора (дополнительный рисунок 2C).
Сравнение с данными ChIP-seq (Cao et al., 2010) показало, что 59% сайтов открытия и 34% сайтов закрытия связаны с MYOD в мышечных трубках и миобластах соответственно (). Напротив, только 16% статических сайтов (без значительных изменений доступности) были связаны с MYOD либо в миобластах, либо в мышечных трубках. Динамически доступные дистальные элементы и промоторы также были сильно обогащены мотивами связывания для членов семейства MYOD, MYOG и MEF2 и других TF, играющих центральную регуляторную роль в миогенезе (19).
Многие TF привлекают ферменты, которые маркируют гистоны рядом с регуляторными элементами ДНК. Например, MYOD привлекает p300, гистонацетилтрансферазная активность которого необходима для его роли в активации экспрессии генов (Dilworth et al., 2004; Puri et al., 1997; Sartorelli et al., 1997). Сравнение с данными ENCODE для миобластов и мышечных трубок показало подавляющее соответствие направлений между сайтами, которые получали или теряли ацетилирование h4K27 (h4K27ac), и сайтами, которые открывались или закрывались в доступности хроматина, соответственно ().Однако большинство изменений в метках гистонов во время дифференцировки происходит на сайтах, которые не претерпевают значительных изменений в доступности хроматина (дополнительная фигура 2D). Таким образом, дифференцировка миобластов характеризуется изменениями в h4K27ac в сотнях тысяч сайтов, лишь небольшая часть из которых сопровождалась изменениями в доступности хроматина, по крайней мере, в той степени, в которой они обнаруживаются применяемыми здесь методами.
Цицерон конструирует полногеномные цис-регуляторные модели на основе данных sci-ATAC-seq
Далее мы попытались использовать паттерны совместной доступности между дистальными элементами и промоторами, чтобы построить полногеномную цис-регуляторную карту.Это сложно по нескольким причинам. Во-первых, необработанные корреляции частично обусловлены техническими факторами, такими как глубина считывания на ячейку. Во-вторых, у нас недостаточно наблюдений, чтобы точно оценить корреляцию между миллиардами пар сайтов. В-третьих, данные ATAC-seq одной ячейки очень разрежены. Наконец, в то время как доступность дистальных элементов может быть коррелирована с их целевыми промоторами, очень далекие или межхромосомные пары сайтов также будут коррелированы в силу того, что они являются частью одной и той же регуляторной программы.
Для решения этих проблем мы разработали новый алгоритм Cicero, который вычитает технические и геномные эффекты расстояния при построении глобальной цис-регуляторной карты из профилей доступности хроматина отдельных клеток (). Вкратце, пользователь предоставляет Цицерону в качестве входных данных ячейки, которые были сгруппированы или псевдовременно организованы. Алгоритм создает множество групп ячеек, каждая из которых состоит из 50 ячеек, одинаково расположенных в пространстве кластеризации или траектории. Это помогает преодолеть разреженность данных и избежать парадокса Симпсона (Simpson, 1951; Trapnell, 2015).Затем он объединяет профили доступности для ячеек в каждой группе, чтобы произвести подсчет, который можно легко скорректировать, чтобы вычесть влияние технических переменных. Наконец, он вычисляет корреляции в скорректированных возможностях доступа между всеми парами сайтов в пределах 500 КБ. Для расчета устойчивых корреляций мы используем графический LASSO (Friedman et al., 2008), который оценивает регуляризованные корреляционные матрицы. Цицерон наказывает корреляции в зависимости от расстояния, сохраняя локальные закономерности за счет очень дальнодействующих.Вывод Cicero состоит из оценок совместимости для всех пар сайтов в пределах 500 Кб друг от друга. Полная информация представлена в методах .
Цицерон конструирует цис-регуляторные модели для всего генома на основе данных sci-ATAC-seq. A ) Обзор алгоритма Цицерона (подробности см. В разделе «Методы»). B ) Среднее значение phastCons 46-позиционной консервативности плаценты для дистальных пиков, связанных с промоторами. Пики стратифицировали по расстоянию от промотора и баллу совместимости между промотором и дистальным пиком. C ) Средняя оценка консервации дистального участка по сравнению со шкалой консервации связанного гена, стратифицированная по показателю совместимости. D) Отношения шансов согласованной динамики доступности по дифференцировке в 54-1 миобластах между парами сайтов, ко-доступными в HSMM. Для каждого бина соподоступности в HSMM пары пиков, которые перекрывали пики в 54-1 нецелевых контролях, оценивались на согласованную динамику (> 2 log2-кратное изменение в обоих пиках или <-2 log2-кратное изменение в обоих пиках).Планки погрешностей указывают 95% доверительные интервалы, рассчитанные с использованием точного критерия Фишера. Звездочки представляют оценки, значительно отличающиеся от единицы (p-значения <0,05 по точному критерию Фишера). E ) Показаны две «фазы» дифференцировки миобластов. F ) Краткое изложение связей доступности Cicero между промотором MYOG и дистальными сайтами в окружающей области. Высота связей указывает на величину показателя соподоступности по Цицерону между связанными вершинами.Верхние (красные) ссылки были построены из ячеек в фазе 1, а нижние (синие) были построены из фазы 2. См. Также рисунки S3 и S4.
Мы применили Cicero для создания цис-регуляторной карты всего генома на основе наших данных sci-ATAC-seq по миобластам. В качестве первого шага, например, в эксперименте 1, Цицерон агрегировал дифференцирующиеся миобласты в 277 групп и идентифицировал 6,5 млн пар сайтов с положительной оценкой совместимости, включая 1,8 млн, содержащих дистальный элемент и промотор. По мере увеличения порога совместной доступности промоторы подключаются к меньшему количеству регуляторных элементов с большей достоверностью.Например, при пороговом значении 0,25 промоторы были связаны в среднем с 2 дистальными элементами в эксперименте 1 (дополнительный рисунок 3A). Дистальные участки, которые были в высокой степени доступны с промоторами, были более консервативными у позвоночных (). Эта тенденция была более выражена для сайтов, связанных с высококонсервативными генами, которые имели тенденцию быть доступными с более консервативными дистальными элементами (). Чтобы убедиться, что совместная доступность между сайтами не ограничивается нашей конкретной первичной культурой миобластов, мы выполнили массовую ATAC-seq в миобластах от другого донора («54-1») до и после дифференцировки.Обнадеживает то, что сайты с высокой степенью совместной доступности в 2,2 раза чаще, чем несвязанные сайты подвергаются направленным согласованным изменениям доступности через дифференцировку в клетках 54-1 (). Чтобы исследовать, как доступность соотносится с регуляцией генов во время дифференциации, мы разработали составной «показатель активности гена» для доступности как на промоторах, так и на связанных дистальных участках (метод , ). Оценки активности генов на основе доступности положительно коррелировали с экспрессией (дополнительный рисунок 3B-D).
Поскольку коодоступные элементы имели тенденцию к кластеризации, мы пост-обработали вывод Цицерона с помощью алгоритма обнаружения сообщества, чтобы идентифицировать «сети цис-коодоступности» (CCAN): модули сайтов, которые имеют высокий коодоступность друг с другом. Большинство динамически доступных сайтов были включены в CCAN даже с использованием высокого порога совместной доступности (дополнительный рисунок 4A-E).
Чтобы оценить воспроизводимость карт Цицерона, мы адаптировали метод максимального взвешенного двудольного сопоставления для определения пар CCAN из двух экспериментов, которые имеют общие элементы ДНК ( методы ).Этот алгоритм сопоставил 1868 CCAN между экспериментами, что составляет 84% и 91% сайтов в CCAN в экспериментах 1 и 2, соответственно (дополнительный рисунок 4F). Большинство пар сайтов, связанных в одном эксперименте, также были связаны в другом (оценка> 0,25; 81% сайтов из опыта 1 также связаны в примере 2; 64% сайтов из опыта 2 также связаны в примере 1; дополнительные рисунки 4G ,ЧАС).
Для дальнейшего изучения динамики хроматина во время дифференциации мы построили карты Цицерона на двух «фазах» псевдовременной траектории (до и послепосле ветви F 2 ) и вычислили CCAN для каждой карты (). Общая структура связей Цицерона часто поддерживалась интересующими генами. Например, аналогичный набор дистальных элементов связан с промотором MYOG как на ранней, так и на поздней фазах (). Чтобы идентифицировать CCAN, которые были сохранены, приобретены или потеряны во время дифференциации, мы применили наш алгоритм сопоставления для сравнения CCAN между первой и второй фазами. Для эксперимента 1 этот алгоритм сопоставил 1945 CCAN, что составляет 88% и 91% сайтов в CCAN на первой и второй фазах соответственно.Однако, хотя общая структура CCAN была стабильной (несколько сайтов переключали CCAN), многие сайты присоединялись к CCAN или выходили из них во время дифференциации (дополнительный рисунок 4I, J). Интересно то, что мы идентифицировали 60 мотивов последовательностей, которые предсказывали, присоединится ли сайт, покинет или останется в CCAN, включая CTCF, который убедительно предсказывает, что доступный сайт останется в CCAN (дополнительный рисунок 4K).
Мы предположили, что CCAN, идентифицированные Цицероном, представляют собой «центры хроматина».Хабы хроматина, которые, как полагают, включают петлевые взаимодействия между дистальными регуляторными элементами и генами, на которые они нацелены, могут действовать, чтобы координировать сборку транскрипционных комплексов (de Laat and Grosveld, 2003; Tolhuis et al., 2002). Мы ожидаем, что для соответствия определению хроматинового хаба CCAN должны соответствовать четырем критериям. Во-первых, они должны демонстрировать большую физическую близость, чем ожидалось, исходя из их расстояния в линейном геноме. Во-вторых, они должны взаимодействовать с общим набором белковых комплексов.В-третьих, их следует эпигенетически модифицировать согласованным образом и в одно и то же время. Наконец, они должны вносить существенный вклад в регуляцию генов с промоторами внутри концентратора.
Совместимые элементы ДНК проявляют физическую близость
Чтобы проверить, находятся ли совместно доступные сайты ближе друг к другу в ядре, чем несвязанные сайты на аналогичных расстояниях в линейном геноме, мы создали и применили Цицерона к профилям хроматина sci-ATAC-seq из 889 лимфобластоидных клеток человека. (GM12878), для которого доступны данные ChIA-PET и Hi-C захвата промотора.
Мы наблюдали сильное соответствие между связями на основе Цицерона и элементами ДНК в контактах, опосредованных РНК pol II, захваченных с помощью ChIA-PET (Tang et al., 2015), а также контактах, обнаруженных с помощью захвата промотора Hi-C (Cairns et al. ., 2016; Мифсуд и др., 2015), например. в локусе CD79A (). Около половины элементов ДНК, лигированных с помощью ChIA-PET («якоря»), перекрываются с доступными сайтами в наших данных, причем большее перекрытие между якорями, которые поддерживаются множественными считываниями ChIA-PET, и сайтами, которые были доступны во многих клетках (дополнительные рисунки 5A, Б).Пары сайтов, о которых Цицерон сообщил как совместимые, были в 2–3 раза более вероятны в ChIA-PET и Hi-C, захватывающем промотор, чем несвязанные сайты, разделенные одинаковыми расстояниями (-). В свою очередь, пары сайтов, связанных многими независимыми фрагментами лигирования ChIA-PET или Hi-C, с большей вероятностью также сообщались как совместно доступные для Цицерона (-), , например. ~ 75% достоверных соединений ChIA-PET, обнаруженных на карте Цицерона. Хотя частоты лигирования близости не следует принимать как прямую меру физического расстояния, эти анализы показывают, что сайты, связанные с Цицероном, проявляют большую, чем ожидалось, физическую близость, даже если они очень удалены в линейном геноме.Мы также обнаружили, что связанные сайты Цицерона с большей вероятностью занимали один и тот же топологически связанный домен (TAD), чем несвязанные сайты на том же расстоянии (точный критерий Фишера, p-значение <2e-5 для всех интервалов расстояний, TAD, полученные из разрешения 1 КБ Hi-C анализ GM12878 (Rao et al., 2014)). Точно так же сайты, связанные с Цицероном, были в 1,5 раза более вероятны, чем несвязанные пары на том же расстоянии, которые были обнаружены в одном и том же компартменте A / B (дополнительные рисунки 5C, D).
Совместимые элементы ДНК, связанные Цицероном, физически проксимальны в ядре. A ) Cicero-соединения для локуса CD79A по сравнению с РНК pol-II ChIA-PET (Tang et al., 2015) и промоторного захвата Hi-C (Cairns et al., 2016). Высота связей для ChIA-PET представляет собой логарифмически преобразованные частоты каждого взаимодействия ПЭТ-кластера, а для захвата промотора Hi-C - это логарифмически взвешенные значения p с мягким пороговым значением, полученные из программного обеспечения CHiCAGO. B ) Отношение шансов пар сайтов в пределах заданной совместимости и диапазона расстояний, обнаруженных в РНК pol-II ChIA-PET, по сравнению с парами сайтов с совместной доступностью <= 0.Цвет представляет собой корзину доступности. Планки погрешностей указывают 95% доверительные интервалы, рассчитанные с использованием точного критерия Фишера. Все показанные точки значительно отличались от 1 (p-значения <0,05 по точному критерию Фишера). C ) Аналогично панели B, но сравниваются ссылки Цицерона с сайтами, лигированными в Hi-C с захватом промотора. Все показанные точки значительно отличались от 1 (p-значения <0,05 по точному критерию Фишера), за исключением ячейки размером 10 т.п.н., на которую может повлиять разрешение Hi-C вследствие использования рестрикционного фермента с 6 резцами.Для панелей B и C мы использовали линейную модель, которая включала оценку совместимости и общую доступность, и в обоих случаях обнаружили, что совместимость оказывала значительное влияние на присутствие в наборах данных для сравнения даже после корректировки этого потенциального искажающего фактора (подробности см. В разделе «Методы»). D ) Доля контактов ChIA-PET, обнаруженных в соединениях Цицерона, как функция расстояния, стратифицированная по множественности обнаружений продуктов лигирования. E ) Контакты с промоутером, обнаруженные в соединениях Cicero CCAN, как функция расстояния, стратифицированные по шкале CHiCAGO.См. Также рисунок S5.
Совместимые элементы ДНК несут пары мотивов для взаимодействующих TF
Далее мы исследовали, могут ли связи Цицерона опосредоваться взаимодействующими TF. Мы искали известные мотивы последовательности в пределах каждого пика в данных HSMM, которые могли точно предсказать, свяжет ли Цицерон с ним другие сайты. Промоторы с ДНК-связывающими мотивами для одного или нескольких основных миогенных ТФ были значительно более вероятно связаны (оценка совместимости> 0,25) с открывающимся дистальным сайтом, чем промоторы без них.Например, промоторы, содержащие по крайней мере один мотив MYOD, MYOG или MYF6, имели в 3,6 раза больше шансов быть связаны с открывающимся дистальным сайтом, чем промоторы без ни одного из этих мотивов (p = 8,7 × 10 -270 ; тест отношения правдоподобия для логистическая регрессионная модель).), и аналогичным образом промоторы с по меньшей мере одним мотивом семейства MEF2 были в 2,8 раза более вероятно связаны с открывающимся дистальным сайтом (p = 7,9 × 10 −119 ).
Мы предположили, что эти корреляции являются результатом прямых, опосредованных ТФ взаимодействий.Чтобы исследовать это дальше, мы сосредоточились на промоторах, связанных ровно с одним динамически доступным дистальным сайтом (оценка совместимости> 0,05), и использовали графический LASSO для идентификации пар мотивов, где присутствие мотива в промоторе предсказывает присутствие парного мотива в динамически доступный дистальный участок (методы , ). Мы идентифицировали ряд пар мотивов, соответствующих ТФ, которые, как известно, физически взаимодействуют. Например, открывающиеся дистальные элементы с большей вероятностью будут иметь мотив MEF2 или RUNX1, если они были связаны с промотором с мотивом MYOD (дополнительная фигура 6A).Миогенные регуляторные факторы (MRF), как известно, физически взаимодействуют с MEF2 и RUNX1 (Knoepfler et al., 1999; Molkentin et al., 1995; Philipot et al., 2010).
MYOD координирует модификации гистонов в когортах совместно доступных сайтов
Физическая близость совместных сайтов предполагает, что привлечение модифицирующих гистоны ферментов к одному сайту может вызывать изменения в физически близких сайтах. В самом деле, пары сайтов с большей вероятностью будут подвергаться значительному согласованному усилению в h4K27ac, если они были связаны Цицероном ().Сайты, которые сами по себе демонстрировали статическую доступность, но были связаны с динамическим, открывающимся сайтом, показали значительный прирост h4K27ac, в то время как статические сайты, которые были связаны с динамическими, закрывающимися сайтами, показали сильные потери (). Усиление ацетилирования может быть обусловлено связыванием de novo MYOD в сайте открытия с последующим привлечением гистонацетилтрансферазы (, например, p300). Подтверждая это, из 2050 сайтов со значительным увеличением h4K27ac, но статической доступностью, только 46% были связаны с помощью MYOD в мышечных трубках.Однако 97% были связаны Цицероном с сайтом, связанным с MYOD (). Более того, оснащение регрессионной модели информацией о связанных сайтах повысило ее точность при прогнозировании изменений в метках гистонов сайта (дополнительный рисунок 6B)
Совместимые элементы ДНК, связанные Цицероном, эпигенетически ко-модифицируются. A ) Отношение шансов сайта, получающего h4K27ac во время дифференцировки миобластов, при условии, что он связан с сайтом, который это делает. Цвет указывает на силу ссылок на доступность Цицерона.Самым светлым цветом обозначены пары сайтов, ссылки на которые Цицерон не связывает. B ) Соответствие между увеличением или уменьшением h4K27ac для статически доступного сайта и его максимальной степенью совместимости с сайтом, который открывается (ось x) или закрывается (ось y). Сайты, не связанные с открывающимся или закрывающимся сайтом, отображаются при x = 0 или y = 0 соответственно. C ) Аналогично панели B, но с описанием соответствия между получением или потерей сайта h4K27ac и его максимальной оценкой совместимости с сайтом, который получает или теряет MYOD. D ) Дисперсия, объясненная в серии моделей линейной регрессии, в которых ответом является логарифм 2 -кратное изменение уровня h4K27ac каждого элемента ДНК, а предикторами является то, открывается ли этот сайт, закрывается или статичен, независимо от того, получает или теряет привязку MYOD, и независимо от того, связана ли она с соседями, которые это делают. См. Раздел "Методы" для получения подробной информации о технических характеристиках модели. E ) Карта Цицерона для области 755 kb, окружающей MYh4 вместе с пиками MYOD ChIP-seq из (Cao et al., 2010). Сайты, открывающиеся в режиме доступности, окрашены псевдодействием их открытия (см. Методы), сайты, не открывающиеся в режиме доступности, отображаются серым цветом. На вставке показана область размером 60 т.п.н., окружающая MYh4 вместе с сигнальными дорожками MYOD ChIP-seq и h4K27ac ChIP-seq из (Cao et al., 2010) и (The ENCODE Project Consortium, 2012). Показаны только гены, кодирующие белок. F ) Псевдовремя открытия для всех сайтов открытия, подразделяется на то, связана ли MYOD в миобластах и мышечных трубках, одних мышечных трубках или ни в одном из них. G ) Разница в псевдовременности открытия между парами связанных элементов ДНК. Пары сгруппированы в зависимости от того, связаны ли один или оба сайта конститутивно с помощью MYOD. H ) Мотивы связывания TF, выбранные с помощью эластичной сетевой регрессии (альфа = 0,5), с ответом, кодирующим статус связывания MYOD каждого сайта. См. Также рисунок S6.
Далее мы рассмотрели, было ли усиление связывания MYOD сосредоточено в нескольких CCAN или широко распространено. Из 2323 хабов, содержащих промоторы, 74% содержали по крайней мере один сайт, претерпевающий изменение связывания MYOD.Для подмножества 431 концентратора с дифференциально экспрессируемым геном 92% содержали по крайней мере один сайт, изменяющий связывание MYOD. Например, в пределах одного концентратора, который включает изоформы тяжелой цепи миозина 1, 2, 3, 4, 8 и 13 и множество других генов, 15 сайтов подверглись значительному увеличению доступности. Из них все были связаны MYOD в мышечных трубках (). Интересно, однако, что два сайта очень близко к MYh4 (отмечены звездочками) открылись значительно раньше в псевдовремя, чем другие, и также были связаны с помощью MYOD в миобластах.
Мы задались более общим вопросом, открываются ли сайты, связанные с MYOD в миобластах и на протяжении дифференцировки, раньше, чем сайты, которые связываются с MYOD во время дифференцировки. Анализ точек изменения с использованием PELT (Killick et al., 2012) показал, что сайты, связанные с MYOD на протяжении дифференцировки, открывались значительно раньше в псевдовремя, чем те, которые приобрели MYOD (значение p-критерия Манна-Уитни 1,2e-122) или никогда не были им связаны. (P-значение критерия Манна-Уитни 8,0e-223) (). Более того, вместо того, чтобы обогащаться целыми концентраторами, которые открываются на ранней стадии в группе, сайты, связанные с конститутивно MYOD, открывались значительно раньше, чем связанные с ними сайты, которые либо приобрели MYOD (p-значение двустороннего парного t-критерия Стьюдента = 1.0e-182) или никогда не были им связаны (p-значение двустороннего парного t-критерия Стьюдента = 4,5e-318) (). Сайты, связанные с MYOD, были обогащены мотивами MEIS1 и AP-1 () по сравнению с сайтами, которые приобретают MYOD позже при дифференцировке. В целом сайты с мотивами MEIS1 были связаны с 69% динамически открывающихся сайтов по сравнению только с 16% сайтов в масштабе всего генома (оценка совместимости> 0,25). Сообщалось, что мышиный Meis1 в сочетании с Pbx1 действует как комплекс, необходимый для MYOD-опосредованной активации промотора миогенина, а мутации в MYOD, которые предотвращают взаимодействие с PBX, приводят к потере многих сайтов связывания и регуляторных мишеней (Berkes et al. al., 2004; Фонг и др., 2015). Наши результаты предполагают, что привлечение MEIS1 MYOD может распространяться по всему геному и может вызывать активацию других сайтов в хабе хроматина.
Последовательность активных хабов хроматина предсказывает регуляцию гена
Мы задались вопросом, можно ли использовать предполагаемые карты Цицерона для предсказания изменений в экспрессии генов. В качестве первого теста мы спросили, демонстрируют ли два гена с совместно доступными промоторами большую корреляцию в экспрессии в отдельных клетках, чем гены, находящиеся поблизости, но промоторы которых не были связаны Цицероном.Действительно, дифференциально экспрессируемые гены показали большую корреляцию в экспрессии в зависимости от их оценки совместимости (дополнительная фигура 7F).
Затем мы попытались разработать модель линейной регрессии для прогнозирования изменений либо в экспрессии гена, либо изменений в гистоновых метках «барьерной области», связанных с активацией промотора (). Наша первая модель принимает в качестве входных данных двоичную карту связывающих мотивов TF, присутствующих в промоторе выше каждого TSS. Затем мы обучаем его предсказывать, какая часть наблюдаемых изменений экспрессии гена связана с каждым мотивом TF, используя эластичную сетевую регрессию и 50-кратную перекрестную проверку (методы , ).Модель, основанная на промоторе, объяснила только 17% вариации экспрессии и аналогично работала при прогнозировании панели гистоновых меток (-). Дополнение этой модели мотивами TF в связанных дистальных сайтах улучшило ее способность объяснять изменения экспрессии в 2,27 раза (). Мотивы TF, идентифицированные с помощью модели, включали MRF E-box, MADS-бокс, связанный с белками семейства MEF2, и сайт связывания MEIS1, которые были связаны с повышающей регуляцией, наряду с мотивами для факторов, которые управляют пролиферацией клеток, таких как AP-1, которые были связаны с подавлением ().Таким образом, когда нам поставили задачу предсказать, какие факторы важны для регуляции генов, наша регрессия идентифицировала основные миогенные TF, используя только последовательности в сайтах, связанных вместе Цицероном.
Динамика хроматина в дистальных элементах ДНК предсказывает регуляцию гена. A ) Изменения ацетилирования гистонов в первых 1 т.п.н. ниже TSS каждого гена, соответствующие «барьеру» для удлинения РНК pol II, создаваемому нуклеосомами, коррелируют с изменениями в его экспрессии. B ) Две регрессионные модели предсказывают изменения в гистоновых метках, отложенных по всей барьерной области каждого гена.2 вычисляется как объясненная доля нулевого отклонения. Число справа от каждой полосы указывает соотношение дисперсии, объясненное между первой и второй моделями. C ) Подобно панели B, с изменениями выражения в качестве ответа. D ) Коэффициенты модели, включающей последовательность в дистальных участках для каждого мотива, выживающего при выборе модели с помощью эластичной сети. Обратите внимание, что модель рассматривает каждый мотив дважды: один раз на промоторах и еще раз на дистальных участках, и оба могут быть выбраны эластичной сеткой.См. Также рисунок S7.
MEIS1 и PBX1 необходимы для скоординированной активации хаба хроматина миобластов
Мы предположили, что MYOD, который рекрутирует p300 / PCAF и комплекс BAF при дифференцировке миобластов, может действовать, чтобы зародить модификацию гистонов и ремоделирование нуклеосом по всему хабу хроматина. Чтобы проверить эту гипотезу, мы генетически удалили MEIS1 или PBX1 (который образует гетеродимер с MEIS1) с помощью CRISPR / Cas9 в 54-1 клетках, а затем выполнили массовую ATAC-seq по мере их дифференциации.Миобласты ΔMEIS1 и ΔPBX1 дифференцировались заметно менее эффективно, с меньшим количеством мышечных трубок и меньшего размера, чем клетки, трансдуцированные sgRNAs non-targeting control (NTC) (). Из 14 321 сайта, доступность которого претерпела значительные изменения в 54-1 NTC, 7 868 (55%) и 12 520 (87%) не смогли этого сделать в ΔMEIS1 или ΔPBX1 ячейках соответственно, и почти 25% сайтов, потерпевших неудачу для открытия перекрывающихся сайтов, связанных MYOD как в нормальных миобластах, так и в мышечных трубках ().
MEIS1 и PBX1 нокаутные миобласты не могут дифференцироваться и обнаруживают скоординированные дефекты доступности. A ) Иммунофлуоресцентные микроскопические изображения нематричного контроля, клеток с нокаутом MEIS1 и PBX1 с нокаутом 54-1 в день 0 и день 7 после индукции дифференцировки. Ядра окрашивают с использованием DAPI, MYh4 окрашивают с использованием антимиозина MF20 и Alexa Fluor 594. B ) Процент пиков, которые открываются во время дифференцировки в NTC, которые не открываются в нокаутах PBX1 и MEIS1 .Цвета указывают на присутствие MyoD-связывания в миобластах и мышечных трубках с помощью ChIP-seq в HSMM. C ) Отношения шансов конкордантной неудачи прироста доступности при дифференцировке нокаутных миобластов 54-1 между парами сайтов, ко-доступными в HSMM. Для каждого бина соподоступности в HSMM пары пиков, которые перекрывали пики в 54-1 нематричных элементах управления, оценивались на предмет согласованного отказа в открытии (пики, которые открываются в NTC, но не делают этого в нокаутах). Цвет указывает на нокаут.Планки погрешностей указывают 95% доверительные интервалы, рассчитанные с использованием точного критерия Фишера. Звездочки обозначают оценки, значительно отличающиеся от единицы (p-значения <0,05 по точному критерию Фишера). D ) Аналогично С. Отношения шансов конкордантной неудачи прироста доступности при конститутивном связывании MyoD в одном из пиков. Для каждого бина совместимости в HSMM пары пиков, которые перекрывают пики в 54-1, оценивали на наличие конститутивного связывания MyoD в одном или обоих сайтах, а также на скоординированную неспособность открыть.Были включены только пары сайтов, оба из которых открыты в NTC. Данные для MEIS1 выбиты только из-за недостатка мощности в PBX1 . E) Модель того, как активация хроматинового хаба может быть инициирована подмножеством «преждевременно» открывающихся элементов ДНК. Такие сайты заняты TF, компетентными связывать относительно закрытые, неактивные элементы ДНК, такие как MEIS1 , которые могут связывать менее компетентные факторы, такие как MYOD, с центром. Последующее привлечение p300 и комплекса BAF, возможно, через промежуточные факторы (например,грамм. MYOD), приводит к ремоделированию и ацетилированию гистонов по всему центру. Эти новые доступные сайты затем связываются другими активаторами транскрипции (например, MEF2), что приводит к рекрутированию Pol II. Более того, ацетилирование гистонов после собранных преинициационных комплексов снижает барьер, который они создают для элонгации, повышая эффективную транскрипцию генов внутри концентратора.
Наблюдая, что пары сайтов, идентифицированные Цицероном как высокодоступные в HSMM, с большей вероятностью открываются или закрываются согласованно в клетках 54-1 при дифференцировке (), мы спросили, будут ли коодоступные пары согласованно нарушаться у мутантов.Действительно, пары сайтов, которые открылись в 54-1 NTC и были связаны Цицероном, как правило, не открывались у мутантов. Например, пары сайтов, которые Цицерон связал с показателем совместимости> 0,3, в 2,3 раза чаще не открывались в ΔPBX1 и в 1,6 раза чаще в ΔMEIS1 , чем пары сайтов, которые Цицерон считал несовместимыми, что предполагает эта совместная доступность часто сохраняется даже тогда, когда клетки не могут дифференцироваться ().
Затем мы оценили, могут ли сайты, связанные с MYOD, вызывать изменения во всех концентраторах, сначала разделив нормально открывающиеся сайты на те, которые были конститутивно связаны с MYOD, и те, которые не были.Затем мы проверили, были ли другие сайты, связанные с этими группами на разных уровнях, с большей или меньшей вероятностью скоординированно не открывались в ΔMEIS1 (). В соответствии с нашей гипотезой, высокодоступные сайты в 1,5 раза чаще не открывались в миобластах ΔMEIS1 , когда один из сайтов был конститутивно связан с MYOD, чем когда ни один из них не был конститутивно связан с MYOD (p-значение 0,0011, точное значение Фишера). тестовое задание). Эти находки подтверждают, что MEIS1 может быть важным для правильного MYOD-опосредованного рекрутирования комплексов ремоделирования хроматина в специфические сайты, которые впоследствии действуют на др. В 3D-близости.
Discussion
Несмотря на свою первостепенную важность, карты, которые всесторонне связывают дистальные регуляторные последовательности с их генами-мишенями, все еще отсутствуют. Чтобы решить эту проблему, мы разработали программу Cicero, которая строит предполагаемые цис-регуляторные карты на основе данных о доступности хроматина отдельных клеток. Мы ожидаем, что эти карты будут направлять последующую валидацию с помощью других масштабируемых методов, таких как массивно-параллельные анализы репортеров и редактирование генома, опосредованное CRISPR (epi). В отличие от других подходов, таких как ChIA-PET и Hi-C с захватом промотора, Cicero работает с данными отдельных клеток и поэтому избегает эффектов усреднения, которые могут затруднить массовые анализы.Как описано здесь для модели дифференцировки скелетных мышц, последующий анализ связей на основе Цицерона может продвинуть наше количественное понимание регуляции эукариотических генов, а также может облегчить идентификацию генов-мишеней некодирующих вариантов, лежащих в основе сигналов GWAS.
Псевдо-временное упорядочение профилей доступности хроматина от дифференцирующихся миобластов выявило динамические изменения в тысячах элементов ДНК. Хотя изменения в доступности промоторов были плохим предиктором динамики экспрессии генов, дистальные сайты, связанные с генами Цицероном, улучшили эти модели, особенно когда были включены мотивы последовательности.
Наш анализ показывает, что CCAN, определенные Цицероном, соответствуют определению хроматиновых хабов: они физически близки в ядре, их гистоновые метки изменяются скоординированным образом, а их взаимодействия, вероятно, опосредуются общим набором TF, некоторой родословной. -специфический. Что касается миогенеза, наши результаты подтверждают модель активации генов, в которой подмножество «преждевременных» энхансеров рекрутирует ферменты ремоделирования хроматина и другие эпигенетические модификаторы в концентратор, которые опосредуют увеличение доступности других сайтов связывания ().Для того, чтобы такой механизм работал, хроматиновые хабы, включающие гены, молчащие в миобластах и активируемые во время дифференцировки, должны быть в значительной степени установлены до его начала. В самом деле, Цицерон связал более половины активированных или активированных генов с такими «предустановленными» хроматиновыми центрами. Сайты, которые присоединяются к хабу или покидают его, отличаются от тех, которые остаются его частью, по определенным мотивам TF.
Широко известно, что при дифференцировке миобластов MYOD рекрутирует комплекс BAF и p300 / PCAF для активации энхансеров мышечных генов (Serra et al., 2007; Simone et al., 2004). Хотя роль MYOD в вербовке хорошо известна, то, как рекрутируется сам MYOD, менее ясно. Мы обнаружили, что сайты раннего открытия обогащены мотивами MEIS1 и конститутивным связыванием MYOD. Ранее сообщалось, что Meis1 связывает Myod с неактивным промотором миогенина до начала дифференцировки и необходим для активации миогенина и ремоделирования хроматина, что позволяет связывать MYOD с соседними E-блоками MRF, которые ранее были недоступны (Berkes et al., 2004; Maves et al., 2007; де ла Серна и др., 2005). Действует ли MEIS1 / PBX1 для связывания MYOD с неактивным хроматином в целом по всему геному, остается открытым вопросом.
Наш анализ указывает на то, что MEIS1 и его кофактор PBX1 необходимы для ремоделирования хроматина на большой фракции сайтов, которые обычно открываются во время дифференцировки миобластов, служа в качестве начальных сайтов рекрутирования для ферментов эпигенетического ремоделирования. Связывание p300 с MYOD, привязанным к MEIS1 / PBX1, может затем ацетилировать гистоны по всем элементам ДНК, физически находящимся поблизости в хабе хроматина.Эта модель может помочь объяснить повсеместное усиление и потерю ацетилирования гистонов во всем доступном геноме, несмотря на меньшее количество дифференциально доступных или связанных с MYOD элементов. Хотя мы не можем исключить возможность того, что некоторые дефекты ремоделирования хроматина вызваны вторичными эффектами ниже по течению от MEIS1 / PBX1, наш полногеномный анализ вместе с биохимическими и геномными данными из предыдущих исследований подтверждает прямую роль MEIS1 / PBX1 в рекрутинге факторы, активирующие хроматиновые хабы.
Cicero предоставляет эффективные общегеномные средства для создания возможных связей между регуляторными элементами и генами-мишенями в ткани или типе клеток, представляющих интерес, с использованием данных из одного эксперимента. Хабы хроматина, которые он определяет, будут способствовать построению количественных моделей эпигенетической динамики и динамики экспрессии генов, а также идентификации генов, нарушение регуляции которых лежит в основе ассоциаций GWAS. Поскольку в этой области исследуются атласы клеток в масштабе организма, которые всесторонне определяют каждый тип клеток и их молекулярный профиль, такие регуляторные карты будут иметь важное значение для понимания эпигенетической основы программы экспрессии генов каждого типа клеток как в отношении здоровья, так и болезни.
Single Cell ATAC-seq Analysis с помощью Cicero
Эта виньетка представляет собой сокращенную версию страниц документации на веб-сайте Cicero. Пожалуйста, посетите веб-сайт для получения более подробной информации.
Основная цель Цицерона - использовать данные о доступности одноклеточного хроматина для прогнозирования областей генома, которые с большей вероятностью находятся в физической близости в ядре. Это может быть использовано для идентификации предполагаемых пар энхансер-промотор и для понимания общей структуры цис-архитектуры геномной области.
Из-за редкости данных по одной ячейке, ячейки должны быть агрегированы по сходству, чтобы обеспечить надежную корректировку различных технических факторов в данных.
В конечном счете, Цицерон дает оценку «совместной доступности по Цицерону» от -1 до 1 между каждой парой доступных пиков в пределах определенного пользователем расстояния, где более высокий балл указывает на более высокую совместную доступность.
Кроме того, пакет Cicero предоставляет расширенный набор инструментов для анализа экспериментов с ATAC-seq с одной клеткой с использованием структуры, предоставляемой программным обеспечением для анализа одноклеточной RNA-seq Monocle.Эта виньетка представляет собой обзор рабочего процесса анализа ATAC-Seq одной ячейки с помощью Cicero. Для получения дополнительной информации и дополнительных возможностей см. Страницы руководства для пакета Cicero R, веб-сайт Cicero и наши публикации.
Цицерон может помочь вам выполнить два основных типа анализа:
- Построение и анализ цис-регулятивных сетей. Cicero анализирует совместную доступность для выявления предполагаемых цис-регуляторных взаимодействий и использует различные методы для их визуализации и анализа.
- Общий анализ доступности одноклеточного хроматина. Cicero также расширяет программный пакет Monocle, позволяя идентифицировать дифференциальную доступность, кластеризацию, визуализацию и реконструкцию траектории с использованием данных о доступности одноклеточного хроматина.
- Загрузите пакет с Bioconductor.
если (! RequireNamespace ("BiocManager", quietly = TRUE))
install.packages ("BiocManager")
BiocManager :: install ("cicero") Или установите разрабатываемую версию пакета с Github.
BiocManager :: установить (cole-trapnell-lab / cicero) - Загрузите пакет в сеанс R.
библиотека (Цицерон) Запуск Цицерона
Класс CellDataSet
Cicero хранит данные в объектах класса CellDataSet (CDS). Класс является производным от класса Bioconductor ExpressionSet, который предоставляет общий интерфейс, знакомый тем, кто анализировал эксперименты с микрочипами с Bioconductor.Monocle предоставляет здесь подробную документацию о том, как создать входной CDS.
Чтобы изменить объект CDS, чтобы он содержал доступность хроматина, а не данные экспрессии, Цицерон использует пики в качестве своих данных характеристик fData, а не гены или транскрипты. В частности, многие функции Цицерона требуют пиковой информации в форме chr1_103_103. Например, входная таблица fData может выглядеть так:
| chr10_100002625_100002940 | chr10_100002625_100002940 | 10 | 100002625 | 100002940 |
| chr10_100006458_100007593 | chr10_100006458_100007593 | 10 | 100006458 | 100007593 |
| chr10_100011280_100011780 | chr10_100011280_100011780 | 10 | 100011280 | 100011780 |
| chr10_100013372_100013596 | chr10_100013372_100013596 | 10 | 100013372 | 100013596 |
| chr10_100015079_100015428 | chr10_100015079_100015428 | 10 | 100015079 | 100015428 |
В качестве примера пакет Cicero включает небольшой набор данных, называемый cicero_data.
данные (cicero_data) Для удобства Цицерон включает функцию make_atac_cds. Эта функция принимает в качестве входных данных data.frame или путь к файлу в формате разреженной матрицы. В частности, этот файл должен быть текстовым файлом с разделителями табуляции и тремя столбцами. Первый столбец - это координаты пика в форме «chr10_100013372_100013596», второй столбец - это имя ячейки, а третий столбец - это целое число, которое представляет количество считываний из этой ячейки, перекрывающих этот пик.В файле не должно быть строки заголовка.
Например:
| chr10_100002625_100002940 | ячейка1 | 1 |
| chr10_100006458_100007593 | ячейка2 | 2 |
| chr10_100006458_100007593 | ячейка3 | 1 |
| chr10_100013372_100013596 | ячейка2 | 1 |
| chr10_100015079_100015428 | ячейка4 | 3 |
Результатом make_atac_cds является действительный объект CDS, готовый для ввода в следующие функции Цицерона.
input_cds <- make_atac_cds (cicero_data, binarize = TRUE) Создание компакт-дисков Цицерона
Поскольку данные о доступности одноклеточного хроматина чрезвычайно редки, для точной оценки показателей совместной доступности необходимо агрегировать похожие клетки для создания более плотных данных подсчета. Цицерон делает это, используя подход k-ближайших соседей, который создает перекрывающиеся наборы ячеек. Цицерон конструирует эти наборы на основе координатной карты уменьшенного измерения сходства ячеек, например, из карты tSNE или DDRTree.
Вы можете использовать любой метод уменьшения размерности, чтобы основать агрегированный CDS. Мы покажем вам, как создать две версии, tSNE и DDRTree (ниже). Оба эти метода уменьшения размерности доступны в Monocle (и загружены Цицероном).
Когда у вас есть карта координат уменьшенного измерения, вы можете использовать функцию make_cicero_cds для создания агрегированного объекта CDS. Входными данными make_cicero_cds является ваш входной объект CDS и ваша карта координат уменьшенного измерения.Уменьшенная карта размеров Reddated_coordinates должна быть в форме data.frame или матрицы, где имена строк соответствуют идентификаторам ячеек из таблицы pData вашего CDS. Столбцы уменьшенных_координат должны быть координатами объекта уменьшенного измерения, например:
| ячейка1 | -0,7084047 | -0,7232994 |
| ячейка2 | -4,4767964 | 0,8237284 |
| ячейка3 | 1.4870098 | -0,4723493 |
Вот пример уменьшения размерности и создания CDS Цицерона. Используя Monocle в качестве руководства, мы сначала находим координаты tSNE для нашего input_cds:
набор. Семян (2017)
input_cds <- detectGenes (input_cds)
input_cds <- EstimationSizeFactors (input_cds)
input_cds <- reduceDimension (input_cds, max_components = 2, num_dim = 6,
сокращение_method = 'tSNE', norm_method = "none") Для получения дополнительной информации о приведенном выше коде см. Раздел веб-сайта Monocle о кластеризации ячеек.
Затем мы получаем доступ к координатам tSNE из входного объекта CDS, где они хранятся в Monocle, и запускаем make_cicero_cds:
tsne_coords <- t (уменьшенныйDimA (input_cds))
row.names (tsne_coords) <- row.names (pData (input_cds))
cicero_cds <- make_cicero_cds (input_cds, Reduced_coordinates = tsne_coords)
#> Перекрывающиеся метрики контроля качества:
#> Ячеек в бункере: 50
#> Максимальное количество общих ячеек bin-bin: 44
#> Среднее количество общих ячеек bin-bin: 12.5285714285714
#> Медиана общих ячеек bin-bin: 1
#> Предупреждение в make_cicero_cds (input_cds, Reduced_coordinates = tsne_coords): Вкл.
#> в среднем более 10% ячеек делятся между парными ячейками.#> Предупреждение в if (isSparseMatrix (counts)) {: длина условия> 1 и только
#> будет использован первый элемент Беги Цицерона
Основная функция пакета Cicero заключается в оценке совместной доступности сайтов в геноме для прогнозирования цис-регуляторных взаимодействий. Получить эту информацию можно двумя способами:
- run_cicero, получить выходные данные Cicero со всеми значениями по умолчанию Функция run_cicero вызовет каждый из соответствующих фрагментов кода Cicero, используя значения по умолчанию и вычисляя параметры наилучшей оценки по ходу выполнения.Для большинства пользователей это будет лучшим местом для начала.
- Вызов функций по отдельности, для большей гибкости Для пользователей, которым нужна большая гибкость в вызываемых параметрах, и тем, кому нужен доступ к промежуточной информации, Cicero позволяет вызывать каждую из составляющих по отдельности. Более подробная информация об отдельном запуске функции доступна на страницах руководства по пакету и на веб-сайте Cicero.
Самый простой способ получить оценки совместной доступности Cicero - запустить run_cicero.Чтобы запустить run_cicero, вам понадобится объект CDS cicero (созданный выше) и файл координат генома, который содержит длины каждой из хромосом в вашем организме. Координаты hg19 человека включены в пакет, и к ним можно получить доступ с помощью данных («human.hg19.genome»). Вот пример вызова, продолжающийся с данными нашего примера:
данных ("human.hg19.genome")
sample_genome <- subset (human.hg19.genome, V1 == "chr18")
sample_genome $ V2 [1] <- 10000000
conns <- run_cicero (cicero_cds, sample_genome, sample_num = 2) # Запуск занимает несколько минут
#> [1] "Запуск Цицерона"
#> [1] "Расчет значения параметра distance_parameter"
#> [1] "Бегущие модели"
#> [1] "Сборка соединений"
#> [1] "Успешные модели Цицерона: 39"
#> [1] "Другие модели:"
#>
#> Ноль или один элемент в диапазоне
#> 1
#> [1] "Моделей с ошибками: 0"
#> [1] "Готово"
голова (conns)
#> Peak1 Peak2 coaccess
#> 1 chr18_10006196_10006822 chr18_9755702_9755970 0.00000000
#> 2 chr18_10006196_10006822 chr18_9756925_9757590 -0.02171226
#> 3 chr18_10006196_10006822 chr18_9771216_9771842 -0.05837012
#> 4 chr18_10006196_10006822 chr18_9781976_9782901 -0.17017477
#> 5 chr18_10006196_10006822 chr18_9784605_9785105 0.00000000
#> 6 chr18_10006196_10006822 chr18_9787597_9788029 0.00000000 Визуализация связей Цицерона
Пакет Cicero включает общую функцию построения графиков для визуализации совместной доступности, которая называется plot_connections.Эта функция использует структуру Gviz для построения графиков генома в стиле браузера. Мы адаптировали функцию из пакета Sushi R для отображения соединений. plot_connections имеет множество опций, некоторые из которых подробно описаны в разделе Advanced Visualization на веб-сайте Cicero, но получить базовый график из вашей таблицы совместной доступности довольно просто:
данные (gene_annotation_sample)
plot_connections (conns, "chr18", 8575097, 8839855,
gene_model = образец_гена_аннотации,
coaccess_cutoff =.25,
connection_width = .5,
collapseTranscripts = "самый длинный") Сравнение подключений Цицерона с другими наборами данных
Часто бывает полезно сравнить соединения Cicero с другими наборами данных с подобными видами ссылок. Например, вы можете сравнить вывод Cicero с лигированием ChIA-PET. Для этого Цицерон включает функцию под названием compare_connections. Эта функция принимает в качестве входных данных два фрейма данных с парами соединений, conns1 и conns2, и возвращает логический вектор, из которого соединения от conns1 находятся в conns2.Сравнение в этой функции проводится с использованием пакета GenomicRanges и использует аргумент max_gap из этого пакета, чтобы разрешить неаккуратные сравнения.
Например, если мы хотим сравнить наши прогнозы Цицерона с набором (вымышленных) соединений ChIA-PET, мы могли бы запустить:
chia_conns <- data.frame (Peak1 = c ("chr18_10000_10200", "chr18_10000_10200",
«chr18_49500_49600»),
Peak2 = c ("chr18_10600_10700", "chr18_111700_111800",
"chr18_10600_10700"))
conns $ in_chia <- compare_connections (conns, chia_conns) Вы можете обнаружить, что это перекрытие слишком строго при сравнении полностью различных наборов данных.Если внимательно присмотреться, вторая строка данных ChIA-PET довольно близко совпадает с последней показанной строкой conns. Разница составляет всего ~ 67 пар оснований, что может вызвать пик. Здесь может пригодиться параметр max_gap:
conns $ in_chia_100 <- compare_connections (conns, chia_conns, maxgap = 100)
голова (conns)
#> Peak1 Peak2 coaccess in_chia in_chia_100
#> 1 chr18_10006196_10006822 chr18_9755702_9755970 0.00000000 FALSE FALSE
#> 2 chr18_10006196_10006822 chr18_9756925_9757590 -0.02171226 ЛОЖЬ ЛОЖЬ
#> 3 chr18_10006196_10006822 chr18_9771216_9771842 -0.05837012 FALSE FALSE
#> 4 chr18_10006196_10006822 chr18_9781976_9782901 -0.17017477 FALSE FALSE
#> 5 chr18_10006196_10006822 chr18_9784605_9785105 0.00000000 FALSE FALSE
#> 6 chr18_10006196_10006822 chr18_9787597_9788029 0.00000000 FALSE FALSE Кроме того, функция построения графиков Цицерона позволяет сравнивать наборы данных визуально. Для этого используйте аргумент compare_track.Фрейм данных сравнения должен включать в себя третий столбец после первых двух столбцов пиков, называемый «совместный доступ». Вот как функция построения графиков определяет высоту построенных соединений. Это может быть количественный показатель, например количество перевязок в ChIA-PET, или просто столбец единиц. Подробнее о параметрах построения графиков на страницах руководства? Plot_connections и в разделе Advanced Visualization на веб-сайте Cicero.
# Добавить столбец единиц под названием "coaccess"
chia_conns <- данные.кадр (Peak1 = c ("chr18_10000_10200", "chr18_10000_10200",
«chr18_49500_49600»),
Peak2 = c ("chr18_10600_10700", "chr18_111700_111800",
«chr18_10600_10700»),
coaccess = c (1, 1, 1))
plot_connections (conns, "chr18", 10000, 112367,
gene_model = образец_гена_аннотации,
coaccess_cutoff = 0,
connection_width = .5,
сравнение_track = chia_conns,
include_axis_track = ЛОЖЬ,
collapseTranscripts = "самый длинный") Поиск сетей цис-коодоступности (CCANS)
В дополнение к оценке попарной совместной доступности, Cicero также имеет функцию для поиска Cis-Co-accessibility Networks (CCAN), которые представляют собой модули сайтов, которые очень доступны друг другу.Мы используем алгоритм обнаружения сообщества Лувена (Blondel et al., 2008), чтобы найти кластеры сайтов, которые имеют тенденцию к совместному доступу. Функция generate_ccans принимает в качестве входных данных фрейм данных соединения и выводит фрейм данных с назначениями CCAN для каждого входного пика. Сайтам, не включенным в кадр выходных данных, не был назначен CCAN.
Функция generate_ccans имеет один необязательный вход, называемый coaccess_cutoff_override. Когда coaccess_cutoff_override имеет значение NULL, функция определит и сообщит соответствующее значение отсечки показателя совместной доступности для генерации CCAN на основе общего количества CCAN с различными отсечками.Вы также можете установить coaccess_cutoff_override как числовое значение от 0 до 1, чтобы переопределить часть функции, связанную с поиском отсечки. Эта опция полезна, если вы чувствуете, что автоматически найденное отсечение было слишком строгим или слабым, или для скорости, если вы повторно запускаете код и знаете, каким будет отсечение, поскольку процедура поиска отсечки может быть медленной.
CCAN_assigns <- generate_ccans (conns)
#> [1] "Использовано ограничение соподоступности: 0,63"
голова (CCAN_assigns)
#> Пик CCAN
#> chr18_10006196_10006822 chr18_10006196_10006822 1
#> chr18_10100928_10101986 chr18_10100928_10101986 1
#> chr18_10174163_10174396 chr18_10174163_10174396 1
#> chr18_11604_13986 chr18_11604_13986 6
#> chr18_157883_158536 chr18_157883_158536 6
#> chr18_2049865_2050884 chr18_2049865_2050884 7 Показатель активности гена Цицерона
Мы обнаружили, что часто доступность промоторов является плохим предиктором экспрессии генов.Однако, используя ссылки Cicero, мы можем лучше понять общую доступность промоутера и связанных с ним удаленных сайтов. Этот комбинированный показатель региональной доступности лучше согласуется с экспрессией генов. Мы называем эту оценку оценкой активности гена Цицерона, и она рассчитывается с использованием двух функций.
Начальная функция называется build_gene_activity_matrix. Эта функция принимает входные CDS и список соединений Цицерона и выводит ненормализованную таблицу оценок активности генов. ВАЖНО : входной CDS должен иметь столбец в таблице fData под названием «ген», который указывает ген, если этот пик является промотором, и NA, если пик является дистальным. Один из способов добавления этого столбца показан ниже.
Выходные данные build_gene_activity_matrix ненормализованы. Его необходимо нормализовать с помощью второй функции, называемой normalize_gene_activities. Если вы намереваетесь сравнить активность генов в разных наборах данных подмножеств данных, тогда все подмножества активности генов следует нормализовать вместе, передав список ненормализованных матриц.Если вы хотите нормализовать только одну матрицу, просто передайте ее в функцию. normalize_gene_activities также требует именованного вектора общего количества доступных сайтов на ячейку. Это легко найти в таблице pData вашего CDS, которая называется «num_genes_expressed». См. Пример ниже.
#### Добавьте столбец для таблицы pData, указывающий ген, если пик является промотором ####
# Создайте набор аннотаций генов, который помечает только сайты начала транскрипции
# гены. Мы используем это как прокси для промоутеров.# Для этого нам нужен первый экзон каждого транскрипта
pos <- подмножество (gene_annotation_sample, strand == "+")
pos <- pos [порядок (pos $ start),]
pos <- pos [! duplicated (pos $ transcript),] # удалить все экзоны, кроме первых, в расшифровке
pos $ end <- pos $ start + 1 # сделать маркер 1 пары оснований TSS
neg <- subset (gene_annotation_sample, strand == "-")
neg <- neg [порядок (neg $ начало, уменьшение = ИСТИНА),]
neg <- neg [! duplicated (neg $ transcript),] # удалить все экзоны, кроме первых, в расшифровке
neg $ start <- neg $ end - 1
gene_annotation_sub <- rbind (pos, neg)
# Создайте подмножество столбцов аннотации TSS, содержащее только координаты
# и имя гена
gene_annotation_sub <- gene_annotation_sub [, c (1: 3, 8)]
# Переименуйте столбец символа гена в "ген"
имена (gene_annotation_sub) [4] <- "ген"
input_cds <- annotate_cds_by_site (input_cds, gene_annotation_sub)
#> Предупреждение в.Seqinfo.mergexy (x, y): Каждый из двух объединенных объектов имеет уровни последовательности, которых нет в другом:
#> - в 'x': chr18_GL456216_random
#> - в 'y': chr1, chr2, chr3, chr4, chr5, chr6, chr7, chr8, chr9, chr10, chr11, chr12, chr13, chr14, chr15, chr16, chr17, chr19, chr20, chr21, chr22, chrX, chrY, chrM
#> Убедитесь, что вы всегда комбинируете / сравниваете объекты на основе одной и той же ссылки
#> геном (используйте suppressWarnings (), чтобы подавить это предупреждение).
#> Предупреждение в .Seqinfo.mergexy (x, y): каждый из двух объединенных объектов имеет уровни последовательности, которых нет в другом:
#> - в 'x': chr18_GL456216_random
#> - в 'y': chr1, chr2, chr3, chr4, chr5, chr6, chr7, chr8, chr9, chr10, chr11, chr12, chr13, chr14, chr15, chr16, chr17, chr19, chr20, chr21, chr22, chrX, chrY, chrM
#> Убедитесь, что вы всегда комбинируете / сравниваете объекты на основе одной и той же ссылки
#> геном (используйте suppressWarnings (), чтобы подавить это предупреждение).голова (fData (input_cds))
#> site_name chr bp1 bp2 num_cells_expressed
#> chr18_10025_10225 chr18_10025_10225 18 10025 10225 5
#> chr18_10603_11103 chr18_10603_11103 18 10603 11103 1
#> chr18_11604_13986 chr18_11604_13986 18 11604 13986 9
#> chr18_49557_50057 chr18_49557_50057 18 49557 50057 2
#> chr18_50240_50740 chr18_50240_50740 18 50240 50740 2
#> chr18_104385_104585 chr18_104385_104585 18 104385 104585 1
#> ген перекрытия
#> chr18_10025_10225 NA
#> chr18_10603_11103 1 AP005530.1
#> chr18_11604_13986 NA
#> chr18_49557_50057 1 RP11-683L23.1
#> chr18_50240_50740 1 RP11-683L23.1
#> chr18_104385_104585 NA
#### Создание оценок активности генов ####
# генерировать ненормализованную матрицу активности генов
unnorm_ga <- build_gene_activity_matrix (input_cds, conns)
# удалить все строки / столбцы со всеми нулями
unnorm_ga <- unnorm_ga [! Matrix :: rowSums (unnorm_ga) == 0,! Matrix :: colSums (unnorm_ga) == 0]
# составить список num_genes_expressed
num_genes <- pData (input_cds) $ num_genes_expressed
имена (num_genes) <- row.имена (pData (input_cds))
# нормализовать
cicero_gene_activities <- normalize_gene_activities (unnorm_ga, num_genes)
# если бы у вас было два набора данных для нормализации, вы бы передали оба:
Затем # num_genes должен включать все ячейки из обоих наборов
unnorm_ga2 <- unnorm_ga
cicero_gene_activities <- normalize_gene_activities (список (unnorm_ga, unnorm_ga2), num_genes) Блондель В.Д., Гийом Ж.-Л., Ламбьотт Р. и Лефевр Э. (2008). Быстрое разворачивание сообществ в большие сети.
Деккер, Дж., Марти-Реном, М.А., Мирный, Л.А. (2013). Изучение трехмерной организации геномов: интерпретация данных взаимодействия хроматина. Nat. Преподобный Жене. 14, 390–403.
Сэнборн, А.Л., Рао, SSP, Хуанг, С.-К., Дюран, Северная Каролина, Хантли, М.Х., Джуэтт, А.И., Бочков, И.Д., Чиннаппан, Д., Каткоски, А., Ли, Дж., И др. . (2015). Экструзия хроматина объясняет ключевые особенности образования петель и доменов в геномах дикого типа и сконструированных геномах. . Proc. Natl. Акад. Sci. США. 112, E6456 – E6465.
Секстон, Т., Яффе, Э., Кенигсберг, Э., Бантиньи, Ф., Леблан, Б., Хойчман, М., Парринелло, Х., Танай, А., и Кавалли, Г. (2012). Трехмерное складывание и принципы функциональной организации генома дрозофилы. . Ячейка 148: 3, 458-472.
цитата («Цицерон»)
#>
#> Ханна А. Плинер, Джей Шендур и Коул Трапнелл и др. al. (2018). Цицерон
#> Предсказывает цис-регуляторные взаимодействия ДНК из одноклеточного хроматина
#> Данные о доступности. Molecular Cell, 71, 858-871.e8.#>
#> Запись BibTeX для пользователей LaTeX -
#>
#> @Article {,
#> title = {Цицерон предсказывает цис-регуляторные взаимодействия ДНК на основе данных о доступности одноклеточного хроматина},
#> journal = {Молекулярная клетка},
#> volume = {71},
#> number = {5},
#> pages = {858 - 871.e8},
#> год = {2018},
#> issn = {1097-2765},
#> doi = {https://doi.org/10.1016/j.molcel.2018.06.044},
#> author = {Ханна А. Плинер, Джонатан С. Пакер, Хосе Л. Макфалин-Фигероа и Даррен А.Кусанович, Риза М. Даза, Деласа Агамирзайе, Санджай Шривацан, Сяоцзе Цю, Дана Джексон, Анна Минкина, Эндрю С. Адей, Фрэнк Дж. Стимерс, Джей Шендур и Коул Трапнелл},
#>} Коллекции Блумсбери - Сравнительный анализ Цицерона и Аквинского
Тот факт, что философы, теологи и этики постоянно миссия по открытию принципов, составляющих надлежащее моральное действие, была очевидна на протяжении большей части письменной истории.Точно как мы должны жить в обществе и в соответствии с какими измеримыми стандартами морального и этического контроля включает большую часть дебатов. Для некоторых поиск остается невозможным, несбыточной мечтой и полной тщетностью ответа на такие вопросы. невозможно ответить во вселенной, столь хаотичной или относительной. Для других вопрос хорошего или правильного поведения строго стоит. отражение культурной относительности, социализации и образования, зависящее от личного опыта.В этой настройке решения о стандартах человеческой жизни на самом деле невозможно различить - по крайней мере, в универсальном смысле. Некоторые возразят что этот дрейф в сторону неспособности формализовать и окончательно оформить моральные стандарты - тенденцию, которую лучше всего описать как «зловещую».
В других исследовательских школах заключение о надлежащих моральных действиях основывается на том, что полезен или полезен; доставляет ли действие удовольствие или нет; как власть и статус требуют ответа; как Священное Писание диктует определенный рецепт жизни.Другие избранные сторонники представляют рациональность, обычай и использование, традиция, космология и история как основа для их анализа. На протяжении более 4000 лет, с тех пор как самые ранние греческие философы писали свою мудрость на древних документах, комментаторы сильно стремились получить рекламный список того, что заставляет действовать правильно или неправильно.
Хотя несомненно, что объяснения, несомненно, меняются на протяжении всего курса истории есть идентифицируемые нити объяснения, которые никогда не испаряются из дискурса.Например, в этом долгосрочного анализа, нельзя оспаривать, что роль богов или Бога была предложена как значимая сила в этом проницательность. Также было бы неразумно отрицать наши наблюдения, основанные на ни на опыте и объективной реальности, с которой мы сталкиваемся, ни на субъективной реальности, которая, как мы надеемся, будет правдой. В другом ключе, вопросы морали и этики часто находят важное значение и объяснение в определенных религиозных традициях и авторитетах. например, в случае Декалога, Магистериума, раввинских наставлений Торы и явных директивы для продуктивной и последовательной жизни.Все эти концепции постоянно появляются и снова появляются при анализе морального и этическое объяснение.
В более широком контексте этот квест можно свести к двум фундаментальным тенденциям. Первый, те, которые определяют человеческую природу на основе потребностей, желаний и желаний - и, следовательно, моральные и этические правила должны отражать эти критерии. Во-вторых, те, кто утверждает, что этика, построенная на индивидуальном горизонте, обречена на крах из-за ее ошибочных и непредсказуемые основания, и, как следствие, некая «телеология» необходима для этого определения.Другими словами, как утверждает последняя школа, не может быть никакой моральной или этической системы без зависимости. на что-то более высокое или внешнее по отношению к игроку-человеку. В книге «After Virtue» Аласдера Макинтайра, похоже, отсутствие телеологии определяется как гарантированный «провал».
С одной стороны, индивидуальный моральный агент, свободный от иерархии и телеологии, мыслит философы-моралисты считают его суверенным в своем моральном авторитете. С другой стороны, унаследованное, если частично преобразованные нормы морали должны быть обретены в каком-то новом статусе, лишенном прежних телеологических характер и их еще более древний категоричный характер как предельно божественный закон.
Макинтайр, среди многих других, ценит эту необычайную пропасть в тех, кто стремитесь к личному, а не к телеологическому. В первом случае человек по сути является моральным агентом без границ или почти без границ. в то время как в последнем случае он или она может ухватиться за что-то более вечное или постоянное. Что полезно в индивидуальном мире Вы можете быть бесполезны для меня, и в этом заключается вакуум. Банальности о том, чтобы поступать правильно, проявлять доброту к другим, и проявление уважения к ближнему ничего не значит для одних и все для других.Макинтайр далее анализирует неизбежное тщетность этической системы, лишенной какого-то высшего авторитета, когда он называет эти индивидуализированные аргументы не более чем «моральные вымыслы», потому что такого рода обоснование не обеспечивает «объективных и безличных критерий », в результате чего возникает« пробел », который невозможно преодолеть. Школы индивидуального предпочтения, будь то утилитарный, последовательный или функционалистский по замыслу, отдавать предпочтение этическим конструкциям один за другим без особой привлекательности в высшую инстанцию.Сложите руки вокруг 3 подход, для целей очерчивания некоторой формулы правильных человеческих действий просто и практически невозможен. Индивидуализм означает то, что он говорит - это «мое» решение, а не твое, и будь я проклят, если нам нужно будет уйти. дальше, чем мои нынешние соображения. Все этическое здание Джереми Бентама построено на этой концептуальной основе. поскольку его удовольствия искали, а боль избегала, подчинение никогда не могло быть универсальным.Каждому человеку его собственные вкусы не могут привести к точному выводу о том, что работает, а что нет для человеческого вида. Жан Портер идеи иллюстрируют дилемму, объявляя подход Бентама формой «рационального эгоизма», исходящего от изолированные особи.
Какая может быть альтернативная эволюция, если этическая система строится на личном? предпочтение и желание? Ничего, и, говоря прямо и недвусмысленно, ничто не может быть безопасным в системе, где по желанию толкуется так же хорошо, как и любой другой.Хотя принято считать, что Бентам и его сторонники смотрели дальше в сторону мажоритарной подсчитывать - величайшие выгоды для наибольшего числа подсчитанных людей - на это тоже нельзя полагаться, хотя Сторонники теории полезности бродят по академическим залам с мажоритарными числами. Генриха Роммена философский шедевр "Естественный закон: исследование правовой и социальной истории", написанный в годы террора гитлеровского Третьего рейха показывает тщетность аргумента о полезности:
Моральный закон далек от внутреннего и объективного; даже полезность нашего действия - это не объективное качество.Следовательно, это не что иное, как совокупность социальных условностей, адаптированных для служения человечеству. потребности и побуждения согласно нашему опыту, которые, однако, могут быть заменены другим опытом в будущем.
Моральная или этическая система, построенная на коллективных предпочтениях, так же ошибочна, как и индивидуальная версия. Роммен стал свидетелем заразы и рвения обожающего немецкого населения над одним из худших моральных принципов. агентов истории, человека, способного морально оправдать смерть миллионов, потому что это было его предпочтением и выбором, в то время как его увлеченные сторонники падали в обморок либо от прямой похвалы, либо от жалкого молчания.Роммен осуждает моральную формулу, которая зависит от «Volkgeist или дух народа».
Что-то более надежное и значимое, чем прихоть и фантазия одного или многие имеют решающее значение в этом анализе. В то время как множество возможных альтернатив велико, масштабы и конечная цель этот текст призван взвесить и оценить две основные переменные в мире этической теории; во-первых, роль «Природа». может сыграть в разъяснении правильного рецепта продуктивной, счастливой и нравственной жизни, быть своего рода мерой для санкционированного и осуждаемого поведения, и во-вторых, чтобы определить, приравнивается ли «Природа» к юридической школе, известной как «Естественная Закон.Рассуждая с другой точки зрения, рассуждают ли теории о естественном порядке вещей, рациональном порядке космоса? или вселенная, и столь же критично уникальные рабочие качества каждого, отличного и различающегося вида существа, предлагают какие уроки о приемлемости человеческого поведения? Может ли телеология быть природой и естественным порядком, или это просто недостаточный?
Более пристально и внимательнее был бы сравнительный комментарий к римскому философу, оратор, юрист Цицерон и доминиканский проповедник и профессор св.Фома Аквинский, самый влиятельный в западном мире Защитник естественного права, проясните эти вопросы? Почему Цицерон и Фома Аквинский? Никто не станет оспаривать значение того и другого. мыслитель в развитии нашей истории и традиций. В случае Цицерона самым известным юридическим адвокат и философ разработали коллекцию работ, затрагивающих множество актуальных проблем, от ораторского искусства и риторики до старых возраст и дружба; от ходатайств и прошения о правовой защите до всеобъемлющих рассуждений о природе богов и т. д. концы и долг.Цицерон вместе с Аквинским предвкушает множество предсказуемых критических замечаний. часто бросали в ангельского доктора католицизма, например, рупора для священнослужителей и курии, богослова, скорее, чем философ, жесткий доктринер, а не философ, любознательный и открытый, и это лишь некоторые из них. Часто становятся жертвами карикатурно, Сент-Томас представляет собой необычайную, если не несравнимую, работу о законе, добродетелях, справедливости и пути к счастливой и этичной жизни.Как указывает Антон Херманн Хруст, только Сент-Томас был способен на «эту полную и гармоничная интеграция ».
После почти четырнадцати веков разлуки можно легко сделать вывод, что эпохи этих двух фигур делают совместное видение маловероятным. Действительно, язычество Цицерона по отношению к христианству Философия Фомы Аквинского на первый взгляд заставила бы это сравнение показаться серией мостов слишком далеко. На каком концептуальном, Интеллектуальный и философский смысл этих двух фигур взаимосвязан? Как могли такие резко разные эпохи и соответствующие мировоззрения? найти согласованные мысли и идеи, достойные изучения? Как такое возможно, что философское мировоззрение Цицерона могло предсказал или спроектировал вечные идеи, которые Томас считает само собой разумеющимся или которые он даже принял, а затем усовершенствовал и развил? С точки зрения этики, морали и хорошей и продуктивной жизни, насколько правдоподобно, что каждая фигура пересекается больше чем часто отвлекается на альтернативную дорогу? В Цицероне мы находим известного светского деятеля, республиканского гуманиста, процессуального защитника обвиняемых по уголовным делам, политика, и человек, способный игнорировать несправедливый закон и даже призывать к смерти императоров, занятых тиранией.С. Адам Сигрейв призывает читателей оценить глубину и широту философских работ Цицерона:
Хотя Цицерона всегда ценили за его достижения в области риторики, только в последние годы он начал восстанавливать научную признательность, которую он получил в средние века за его достижения в политической философии.
Философские работы Цицерона появляются позже в жизни - в промежутке между его утратой станции и политически навязанные изгнанники, большинство из которых демонстрируют своего рода меланхолию по поводу состояния человеческих и моральных дела.Цицерон - государственный деятель, ищущий чего-то более надежного, чем объявления Сената или повсеместное искоренение тех же изданий именованными Богом Цезарем.
Напротив, жизнь и времена Святого Фомы Аквинского были радикально отделены друг от друга океаном. Хотя Фома Аквинский родился из знати, он решил, что интеллектуальная и религиозная жизнь тянет его сильнее, чем любая другая сила. Присоединение к Доминиканцы проявили его сильное интеллектуальное любопытство и почти три десятилетия поддерживали его в качестве монаха и профессора. философии и теологии в университетах Парижа, Кельна и Неаполя.За это время он накопил плодовитое тело. научных работ, кульминацией которых стала его всеобъемлющая «Summa Theologica». На протяжении его непревзойденный научный труд, Сент-Томас считал множество предметов, некоторые из которых переплетаются в одну и ту же интеллектуальный бассейн, как у Цицерона, а именно справедливость и несправедливость в человеческих действиях и человеческой природе, природе и космосе, естественных закон, теория добродетели, цели и благо человеческой личности, порядок во вселенной и множество других концепций.Полемика всегда кружил вокруг Томаса из-за его очевидной привязанности и потребности в эллинских и римских философских традициях, которые часто цитируется в его основных работах. В этом смысле языческий Цицерон кажется ближе к христианской, предпоследней католической философии. Аквинского, из-за взаимосвязи их интеллектуальных интересов, даже по современным стандартам. Нигде это не так очевидно чем в их измерениях хорошего и плохого поведения, правильного и неправильного мышления, естественного и неестественного поведения - ибо в этих выражать контексты, оба мыслителя ищут формулу для измерения.Оба говорят о природе и естественном законе. И анализировать, и оценивать роль добродетели и порока в этом континууме человеческого поведения, пытаясь осмысленно определить природу бытия и законы, которые можно увидеть из указанных определений. Наконец, оба мыслителя насмехаются над относительностью и предлагают систематический подход. для определения 6когда человеческие действия не прекращаются или пересекает черту и отклоняется от своих естественных норм. Роммен ценит эту реальность, когда наблюдает:
Добро - это то, что соответствует сущности.Бытие вещи также раскрывает свою цель в порядке творения, и в своем совершенном исполнении она также является концом или целью своего роста и развитие. Таким образом, сущность - это мера.
Цицерон и Фома Аквинский, независимо от их различий, могут быть самыми странными из пары или самые совместимые братья по идеям, когда-либо придуманные - по крайней мере, по некоторым из этих вопросов. Это то, что это исследование все о поиске общей нити или темы между этими двумя традициями - от классики до средневековья. и определение того, существует ли общая основа, по которой этические дебаты и дилеммы могут быть надежно оценены и аргументированное уважение.Вместо полемической обличительной речи Цицерон и Аквинский могут наставить метод компромисса, посредством которого основная масса из сторон оставляем довольными. Таким образом, вежливый апологет либертарианских стремлений, таких как однополое равенство и брак; досрочное прекращение жизни без чрезвычайной медицинской необходимости и вмешательства; и претензии естественного метода и методологии в воспитании детей, дисциплине и размере семьи, и это лишь некоторые из них, могли бы найти Цицерона более сочувствующим ухом, а Фома Аквинский - с другой стороны, могут применяться или не применяться одни и те же методы измерения с использованием одних и тех же барометров.Здесь нам нужно подождать и узнайте, как их выразительный язык во множестве произведений и названий может позволить создать более или менее ограничительную серию суждений об этических затруднениях. Где-то по пути Фомы Аквинскому пришлось кое-что приспособить - не выходить полезности или морального компромисса, но более широкого понимания вещей. В противном случае его частый дескриптор, как человек, который христианизировал философия Аристотеля принесла бы скудные плоды. Не секрет, что Фома Аквинский любил Аристотеля, обозначая его « Философ »к ужасу прелатов и церковников.Его привязанность к эллинской и римской философии сделала не заканчивая аристотелевским проектом, но распространяя и заботливо включив в него Цицерона, которого он существенно цитировал в своих работах. Таким образом, Фома, а не Цицерон, взял на себя все риски, связанные с его возможным отступничеством и ересью. Этот тип интеллектуальное мужество не следует сбрасывать со счетов, поскольку оно означает сильную страсть к цицероновскому идеалу - необузданную комплимент, касающийся как его основополагающих элементов, так и его хорошо разработанных идей.Томас безоговорочно любил основные принципы философии Цицерона, а именно: человеческая природа и естественный порядок, закон как отражение природы, закон как рациональное упражнение, природа и разум соединились, и обязанность гражданина восстать против несправедливости. Этот анализ соединяет точки с увидеть, где единство царит безраздельно или где различия делают невозможным идеальное единство.
7Наконец, учитывая все эти сравнения, предложат ли Цицерон и Фома Аквинский новый путь? для моральной меры, основанной на конкретно определенных и разработанных принципах? Охватят ли их философские подходы степень совместимости, при которой может быть обнаружено согласие или возможное несогласие? Доставили ли Цицерон и Фома определенные моральные и этические принципы человеческой жизни, которые каждый согласен быть верными и обязательными? Чтобы прийти к любому стоящему ответу, требуют глубокого и точного освещения следующих проблем:
Идея и определение природы и естественного заказ
Цицерон и Фома Аквинский о природе и естественном порядке
Цицерон и Фома Аквинский о природе и разуме
Цицерон и Аквинский о естественном праве
Природа и естественное право: принципы человеческих действий
Совместимость Цицерона и Аквинского
Здесь указаны течения мысли и выражения, которые можно увидеть в произведениях. Цицерона и Фомы Аквинского.Как ни странно, эти категории появляются со значительной регулярностью в большинстве своих работает - ясная и неоспоримая забота о правилах и законах природы, особенно о том, как жить в соответствии с ее догмы и его собственно человеческая деятельность. В обоих мирах мы сталкиваемся с преобладанием разума и рациональности и с тем, как разум и природа неумолимо и бесспорно связаны в нравственном предприятии. На обоих стыках философских идей, мы обнаруживаем, что высший закон, телеология, призывающая к божественному руководству, провидение, и Создатель, издающий естественный закон что каждое существо, особенно разумное существо, обязано без исключения.В рамках этих параметров этот анализ обнаруживает сольются ли миры Цицерона и Аквинского таким образом, чтобы более инклюзивно и убедительно передать моральный рецепт для человеческой жизни это неоспоримо. Учитывая нынешний выбор фиксированного догматизма и непривязанной теории относительности, это шанс стоит брать.
После более чем 1350 лет разлуки вопрос о том, Цицерон и Фома Аквинский мог согласиться с определенными аспектами своей философии, что является сложной задачей.Помимо очевидных различий в религиозном воспитании, профессиональных направлениях, мирском взаимодействии и контрастном культурном опыте каждый мыслитель проявил уровень творчества, который позволил создать большой объем работы, которая одновременно бросила вызов статус-кво во многих вопросы дня. Например, интенсивный республиканизм Цицерона, его непоколебимое «осуждение целей и методов всех так называемых народных лидеров, предупреждение об обещаниях. от этих ложно названных друзей людей, единственной целью которых было самовозвеличивание и чья главная надежда на успех лежала в разногласиях и гражданском порядке »можно охарактеризовать только как политически и социально рискованно, хотя, по общему признанию, смелый.Был ли Цезарь возведен до роли диктатора и божественного правителя, независимо от сенаторских предпочтений, было решено. актуальный вопрос в ту эпоху. С другой стороны, Цицерон, адвокат-адвокат, берет на себя защиту по уголовным делам, которой больше всего боятся. как слишком большой риск и снова демонстрирует тип смелой личности, которая никогда не упускает из виду доминирующую роль, которая закон играет роль в любом обществе, надеющемся на долголетие. Как заключает Томас Митчелл, Цицерон считал право «единственным мастером, который свободные люди могут терпеть, и ни одной группе или отдельному человеку, независимо от их положения, нельзя позволить стать более могущественным, чем закон.Цицерон заработал репутацию яростного и творческого адвоката, который работает как в зале суда, так и в между страницами он пишет. Биограф Энтони Эверитт разделяет это видение мужественного духа с детства: «Он был полон решимости стать лучшим и самым храбрым, чтобы пополнить ряды величайших героев Республики. Он планировал чтобы преуспеть не на поле битвы, а в священном центре Рима, Форуме ».
Точно так же святой Томас, несмотря на карикатуры, продолжает свои замечательные жизнь во времена различных проблем.Речь идет о новой критике некогда стойких католических доктрин в адрес политики. папства и мира, от развития интеллектуального класса, отличного от клерикальных орденов, до увеличения распространение идей. Как поэтически выразился Честертон:
Невозможно больше ни от кого скрыть тот факт, что остров Св. Фомы Фома Аквинский был одним из великих освободителей человеческого интеллекта. Сектанты семнадцатого и восемнадцатого веков были по сути обскурантистами, и они охраняли обскурантистскую легенду о том, что Школьник был мракобесом.Это было одето худой даже в девятнадцатом веке; это будет невозможно в двадцатом.
Вместо того, чтобы утверждать, что Сент-Томас всего-навсего догматик и мальчик на побегушках папства, большинство из тех, кто сталкивается с его работой и честно оценивает ее, остаются с ясностью цели и концептуальной полнотой что типичный интеллектуал просто не может ни покрыть, ни освоить. Его продуктивность как ученого-автора более чем легендарна. он завещал поколениям католических интеллектуалов сокровища, которые восхищают даже самых опытных философов.Жизнь в догматические времена не притупляла и не мешала уму Аквинского, но вместо этого, похоже, обеспечивала еще большее стимулирование освещать темы, когда-то запрещенные для чтения, и включив греческие и римские принципы непосредственно в свои тексты. Томас проявил непоколебимую привязанность к Аристотелю, которого он назвал «Философом» - когда основная церковная иерархия громогласно осуждала языческие идеи греками или римлянами. Здесь Томас проявляет интеллектуальное мужество, терпя осуждения за свое путешествие в мир. Аристотеля, вплоть до епископальной дисциплины и вызова.В основе этих обвинений лежало основной мотив священнослужителей исключить теорию Аристотеля из рассмотрения в католических богословских исследованиях или философских исследованиях. выводы. Удовлетворяясь платонизмом святого Августина, те, кто упрекал и осуждал святого Фомы, напоминали ему, что Святой Августин имел большее влияние, чем любой языческий философ; что воля преобладает в человеческой деятельности над разумом; что творение закреплено в платонических формах больше, чем научное развертывание.Чтобы Сент-Томас решительно отверг вызов статус-кво был бы и оставался интеллектуально пустым, поскольку Томас «кажется, прочитал почти все, что казалось важным. или интересно университетам своего времени. Многое из этого было совершенно новым, заимствованным из арабских и еврейских источников ». Приверженность этим новым теориям означает уверенную, но уважительную храбрость перед лицом широкий спектр негативных последствий. Честертон замечает:
Анафема после анафемы прогремела с высоты; и под тенью преследования, как это часто бывает, на мгновение показалось, что всего одна или две фигуры стояли в одиночестве в охваченном штормом районе.Оба они были в черно-белом цвете доминиканцев; ибо Альберт и Аквинский стояли твердо.
Последствия этого интеллектуального духа далеко идущие и все еще ощущаются в наших современный период. По словам Алисдэра Макинтайра, Фома Аквинский предоставляет лучший и наиболее аргументированный способ урегулирования конфликта. в разнообразных традициях. Это отчасти потому, что он открыт для изучения и анализа противоположных точки зрения, а также тот факт, что там, где он может найти достойные темы в мировоззрении антагониста, он примет и включит.Открытость и способность к приобщению к разнообразным традициям можно описать только как результат нахождения ума в состоянии постоянного развития и роста. Даже диалектический замысел его шедевра Summa Theologica отражает эту тенденцию рассматривать все возможные пути объяснения. Макинтайр рассказывает:
Фома Аквинский был осторожен в каждой дискуссии, чтобы собрать все соответствующие вклады аргументации и интерпретации, которые были сохранены и переданы в рамках двух основных традиций.Итак, библейские источники приводятся в разговор с Сократом, Платоном, Аристотелем и Цицероном, а также с арабскими и еврейскими мыслителями, поскольку а также святоотеческих писателей и более поздних христианских богословов. 10 длина и детализация Summa не являются случайными его характеристиками, а являются неотъемлемой частью его цели и, в частности, обеспечения как сам Аквинский, так и его читатели с уверенностью, что аргументы, приведенные для конкретных статей, были самыми сильными. произведено так далеко с какой-либо известной точки зрения.
Это необычный способ борьбы с миром тринадцатого века. был для Цицерона простым способом подчиниться могуществу римского правления во времена республиканского правления. переворот. Каждый мыслитель был готов вступить в бой с противником в целях аргументации, но с такой же готовностью, как средство для назидать, изучать и охватывать идею или концепцию во всей полноте. У Цицерона и Аквинского читатель поднимается вверх по необходимости это не выбор, потому что это похоже на «восхождение на гору» - в этом трудно убедиться, но «подъем по тропе, проложенной возвышающимся интеллект »на вершине« мудрость.”
Биографический Эскиз Цицерона
Марк Туллий Цицерон родился 3 января 106 г. до н. Э. На юго-востоке страны. Италии - примерно в семидесяти милях от Рима, в городе Арпинум. По большинству показателей его семья была экономически состоятельные и политически связанные с более элитной социальной структурой Рима. В этот период становления римские мир находился под сильным политическим стрессом из-за противоречивых представлений о роли сената, его императоров и национальных интересов.Гражданские войны, группировки отдельных военачальников и вызовы территориальной целостности - вот вопросы, по которым оба Рим и молодой Цицерон были весьма осведомлены. Он жил «в бурное время». Другими словами, Цицерон получил образование и обучение, а также социализацию в кругах, которые должны были учитывать эту динамику. В результате его политические интересы определялись временем, в котором он жил, и личностями, с которыми он встречался.
В возрасте десяти лет его семья переехала в фешенебельный район Рима, где он начал его формальное образование, соответствующее его происхождению и будущим амбициям.К середине подросткового возраста Цицерон был полностью разоблачен. к различным философским школам, таким как эпикуреизм и стоицизм, а также другим направлениям, и все это под эгидой образования «Академия». Цицерон не только учился у великого Филона, но и почувствовал себя более чем комфортно. с академическим скептицизмом, который по самой своей природе отвергает строгие догматические выводы о знании в целом. Академический скептики исследуют «все позиции, чтобы найти наиболее вероятную, и это всегда был метод Цицерона, так что как он выступал против всякого абсолютизма в философии, так и против всякого абсолютизма, реального или находящегося под угрозой, в правительстве, независимо от того, исходила ли угроза от Суллы, Катилины, Цезарь или Антоний.В период 88–81 гг. До н. Э. Цицерон продолжил свое образование еще в двух важные направления, которые повлияли бы на его профессиональную и личную жизнь, а именно в риторике и праве. В риторическом искусства, Цицерон объединил свою правовую защиту для достижения максимальных результатов, поскольку главная цель риторики - доказать или удовлетворить требования конкретного аргумента или аргументации. Следовательно, большую часть своей профессиональной жизни Цицерон беспокоился не только с фактической истинностью данного дела, но и с тем, как факт констатируется или артикулируется, и независимо от того, не приведенные аргументы могут убедить слушателя.В области права, как практикующий юрист, Цицерон преуспел. в создании исключительной репутации в первые годы адвокатской жизни. Не менее убедительно и процедурный тактика, его сила убеждения и методы формулирования существенного плана юридической аргументации адвоката стали имеет решающее значение для его навыков как члена коллегии адвокатов. Неудивительно, что его первая крупная публикация под названием «Темы» for Speeches (De Inventione) был написан около 81 г. до н.э. в начале его юридической практики.Вначале один раскрывает страсть Цицерона к риторике и ее очевидное взаимодействие с правовой защитой. К 77 году до н. Э. Цицерон был в таких требованиях, как адвокат, что он был перенапряжен, «пахнущий полуночным маслом» и физически осушен. В добровольном изгнании на несколько лет Цицерон взял отпуск, чтобы подзарядиться и найти счастье в браке. детей, и снова навестить его многочисленных друзей. Кроме того, он «посещал различных знаменитых и модных учителей риторики, [и] уделял время философским занятиям.В конце концов, Цицерон вернулся к общественной жизни. как избранный квестор в 75 г. до н.э., роль в первую очередь вспомогательного консула. Его размещение на Сицилии вызвало некоторое разделение от жены и новой дочери Туллии, но Цицерон выполнил свою задачу, проявив «талант к грамотному и справедливому управлению». Политический подъем Цицерона в сочетании с его исключительной репутацией юриста-адвоката способствовал развитию его восходящая траектория до его назначения эдилом, административной должностью на ступеньку ниже консула.Назначение подтвердил то, что уже было известно большинству, он был силой, с которой нужно было бороться.
Имя Цицерона росло все шире благодаря его постоянным успехам в баре - ни одного более убедительно, чем обвинение Верреса. Веррес жил в верхних слоях римского общества, бывший губернатор Сицилии находится под следствием по делу о вымогательстве. Дело Верреса действительно вызвало живой интерес общественности. поскольку его «коррупция была печально известна». После успешного преследования Цицерон переехал о других проблемах в мире судебных споров, включая Манилия, Корнелиуса и Катилину, и это лишь некоторые из них.К 64 г. до н. Э. Цицерон пришел к выводу, что пора стать кандидатом в консульство, «должность, наиболее высоко ценимую и ревниво охраняемую дворянством». Из-за его «Неутомимый труд и блеск в судах» Цицерон взял на себя роль консула в этом году. 63 г. до н. Э. С этого периода Цицерон был затронут противоречиями между абсолютной тиранией и диктатурой и упадком и уменьшение власти и авторитета сенаторской функции в римском мире.За это время его репутация эффективное руководство было укреплено с окончанием восстания Катилины, восстания, которое поддержало бесправных и забыт в римской жизни в результате «продолжающейся классовой напряженности и отчуждения низших слоев общества из-за экономических лишения и увеличивающаяся пропасть между богатыми и бедными ». Катилина была менее эффективна в достижении его политические цели и возглавил вооруженное восстание против римского сената. При ее обнаружении, невыполнении и последующем наказании, Цицерона превозносили как главного участника в его разгадывании.Он также санкционировал смерть с минимальными процессуальными правонарушениями. членов - факт, который часто называют редким упущением в процессуальном решении. Его общественная репутация была на высоком уровне. высокая точка превозносится как «Спаситель» Рима и «Отец Отечества», хотя это возвышает общественное мнение было недолговечным, учитывая приближающуюся напряженность Цезаря, Помпея и Красса. Этот союз часто упоминался как «Первый Триумвират», цель которого состояла в том, чтобы уравновесить возникающую напряженность между диктатурой и историческая республиканская форма правления.Учитывая всю эту политическую динамику и неустойчивую позицию Цицерона, попытки чтобы объединить традиционные представления о римском правлении, Цицерон наложил на себя период изгнания в Грецию между 58 г. и 57 г. до н. э.
По мере того, как диктаторские тенденции Цезаря становились все более очевидными, беспокойство Цицерона а возражения сделали его политическое возвышение менее вероятным в последующее десятилетие. Когда Цезарь укрепил свое абсолютное правление, приостановив республиканизма, беспокоящего сенаторский класс, нет сомнений в том, что диктатура победила в течение этот период.Пытаясь затаиться на дно и избежать последствий возражения или сопротивления, произведения Цицерона и его философские в это время занятия приобрели дополнительный смысл. Его работа о природе государства и правительства, Де Re Publica, подтверждение сенаторского республиканизма и сопротивления тирании, создавалась с 54 по 51 год до нашей эры. В течение в то же время был опубликован его проницательный и оригинальный шедевр по праву «Де Легибус». Его научная продуктивность была поразительной по обычным меркам на протяжении всего предыдущего десятилетия, например:
Хотя Цицерон в основном сопротивлялся тихо, рев его книг и текстов, он не мог оставаться изолированной фигурой во время правления тирана.Пострадавший Цицерон также, кажется, очевиден в его личной жизни. жизнь, его многочисленные браки, смерть его дочери Туллии и его собственная изоляция - все это глубоко повлияло на него. Каждый попытки удержать раздавленную республику, похоже, в то время потерпели неудачу, и хотя Цицерон не был прямым участником после смерти Цезаря он одобрил это действие. К 43 г. до н.э. сложности после убийства Цезаря и неудавшийся союз Цицерона с внучатым племянником Цезаря Октавианом, который выступил против Цезаря, присоединившись к Антонию, завершился в начале очень быстрый конец.Антоний назвал сенаторов и им подобных «преступниками» и забрал их собственность. В конце концов Цицерон был найден и казнен по приказу Антония; его руки отрезаны как символ наказание для этого незаурядного человека идей и логики. Что несомненно в Цицероне, так это постоянное влияние на его жизнь, его работы и его идеи имели отношение к любой демократической и республиканской форме правления. Создатели Соединенных Штатов Конституция, особенно Джефферсон, были глубоко обязаны идеалам Цицерона.Более поздние философы в образе св. Фомы Фома Аквинский без колебаний цитировал Цицерона. В конечном итоге произведения Цицерона «выразили многим непреходящим идеалы западной культуры, особенно в отношении свободы, гражданских прав и гуманистического образования ». Цицерон, в сторону от своих политических и философских идеалов, хотя и не был святым человеком, все же ценил роль характера и целостности в публичных отношениях - факт, совершенно утерянный в нашей постмодернистской культуре, где личный интерес ценится превыше всего.Томас Митчелл считает это своим величайшим наследием.
Он также строго придерживался стандартов самоограничения и чистоты рук. что он прописал хорошему государственному деятелю, и его всесторонняя моральная целостность отличала его от многих его современников. во все более коррумпированном и аморальном мире поздней республики.
Биографический эскиз Святого Фомы Аквинского
Жизнь столь же богатая и продуктивная, как у Аквинского (1225–1274 гг.), Трудна. резюмировать на нескольких страницах.Жизнь и времена Фомы Аквинского были предметом некоторых исключительных биографий и других исследований, которые подчеркивают огромность его влияния. Что он доктор церкви, покровитель католического образования и назначен ангельским доктором. Римского католицизма является одновременно свидетельством его духовной глубины и широты, а также его огромного интеллекта. На оборотной стороне этих обозначений - серия карикатур, которые сопровождают Томаса, где бы ни учитывалась его мысль - Томас церковник, папист, теолог и защитник догматов.Всем, кто серьезно знакомится с произведением Св. Фомы можно различить безрассудство этих дескрипторов, ибо в Фоме Аквинского можно встретить философского гения.
Итальянская семья Акино была связана с королями Ломбардии и несколькими королевскими домами. Европы. Его отец Ландульф носил титулы графа Акино и лорда Лорето, Асерро и Белкастро. Как племянник Император Фридрих Барбаросса был также связан с семьей короля Франции Людовика IX.Его жена Феодора была графиней Теано, части Сицилии, завоеванной нормандскими баронами. Таким образом, Святой Томас, родившийся в Рокказекке около 1225 года, происходит из известного семья с обычными большими надеждами на потомство. С раннего возраста Сент-Томас проявлял сверхъестественную интеллектуальность. способностей и в результате был отправлен в исключительные школы с большими ожиданиями для значительной карьеры в армии, политическая или канцелярская служба. В его конкретном случае, поскольку брат его отца был настоятелем бенедиктинского монастыря. в Монте-Кассино ожидалось, что Томас может войти в жизнь с бенедиктинцами.После классического образования в Монте-Кассино и последующим зачислением в университет в Неаполе, Сент-Томас удивил свою семью своим решением присоединиться к доминиканцам - новому порядку, основанному св. Домиником. Его семья была настолько расстроена этим выбором, что его мать попросила других своих сыновей запереть Томаса в замке в Монте-Сан-Джованни-Кампано, пока его мнение не вернется к Монте-Кассино. Более года Святого Томаса держали в стенах замка и даже искушали потерять свою добродетель. проститутки.
Решение присоединиться к доминиканскому ордену никогда не было отменено семьей или влиянием. и его поступление в Парижский университет в 1245 году положило начало интеллектуальному пути, с которым немногие могли соперничать в истории цивилизация. Будучи студентом, Томас познакомился со своим наставником Альбертом Великим, чье влияние и поддержка стали очевидными. непоколебим с самого начала. В то время как Альберт был свидетелем исключительных возможностей интеллекта, большинство из тех, кто имел Ранее встреченный Томас нашел его одновременно тихим и безоговорочно большим и высоким для своего времени.Его коллеги-студенты назвали его «немым быком», на что Альберт парировал: «Вы называете его немым быком, но в своем учении он будет день произведет такой рев, что его услышат во всем мире ».
15Во время своей работы в Париже он тесно сотрудничал с Альбертом и следовал за ним в его последующая встреча в Кельне. В начале своей профессорской карьеры Томас сосредоточился на священных писаниях и библейских книгах. исследования. Автор почти пятидесяти оригинальных научных текстов, его первые произведения связаны с Ветхим и Новым Заветами. в том числе следующее:
Expositio in Job ad litteram - 1260
In Psalmos Davidis exposition - 1272–1273
Expositio в Canticum Canticorum - утерянная работа
Expositio in Isaiam prophetam - 1256–1259
Expositio in Jeremiam prophetam - 1267–1268
Expositio в Threnos Jeremiae prophetae - 1267–1268
Glossacontina в Маттеуме, Маркуме, Лукаме, Иоаннеме (Glossa обычно называют Catena aurea) —1263–1264
Expositio в евангелии с.Matthaei — 1269–1272
Expositio in evangelium s. Иоаннис - 1269–1272
Expositio в с. Паули Эпистолас - 1259–1272
В то же время святой Фома углубился во все богословские и философские вопросы. предметом, десятилетиями работая над завершением массивных сборников, богословских и философских трактатов. Его первый главный синтез приговоров Питера Ломбарда занял три года, чтобы закончить и доставить некоторые ранние выводы о большой склонности Томаса к этическим и юридическим идеям.Реле Вернона Бурка:
К тридцати годам Фома Аквинский уже был хорошо известен как блестящий ученый. и учитель. Его подготовительные занятия были более тщательными, чем у большинства его коллег. Он читал много и глубоко в доступной литературе современной науки, философии и религии. Он учился в четырех больших и разных центры обучения: Монте-Кассино, Государственный университет Неаполя, Доминиканский институт в Кельне и университет Парижа.
Его два других фолианта, Summa Contra Gentiles и Summa Theologica, составленная между 1261 и 1267 годами, включает в себя полноту и полноту католической философской и теологической мысли. Другие работы, обычно называемые Академическими диспутами, были произведены молниеносно. скорость в течение оставшейся части его академической жизни в Париже, Кельне и Неаполе. Эти работы включают следующее:
De veritate — 1256–1259
De Potentia Dei — 1259–1268
De spiritibus creaturis — 1269
16De anima — 1269–1270
De unione Verbi incarnate — 1268–1272
De malo — 1263–1271
De virtutibus — 1269–1272
De immortalitatae animae?
Utrum anima concuncta cognoscat seipsam per essentiam?
Contra оспаривает Dei cultam etreligem - 1256
De perfectione vitae spiritis — 1270
Contra pestiferam doctrinam retrahentium pueros a Religionis ingress — 1270
De unitate intellecuts, contra Averroistas - 1270
De aeternitate mundi, contra murmurantes - 1271
De fallaciis ad quosdam nobiles artistas — 1244–1245
De propositionibus modalibus — 1244–1245
De ente et essential - до 1256
De Principiis naturae ad fratrem Sylvestrum - до 1256
Compendium theologiae ad fratrem Reginaldum socium suum carissimum — 1260–1273
Deaterialtiis separatis, seu de angelorum natura, ad fratrem Reginaldum, socium suum carissimum - после 1270
De Regno (De regimine Principium), ad regem Cypri - 1267
Невозможно должным образом обработать необъятные просторы Томаса. библиография, объем которой «относится ко многим сферам деятельности и является точным отражением его участия в религиозная и интеллектуальная жизнь его возраста.Энтони Кенни правильно называет Томаса интеллект «необычайной силы и трудолюбия». От бытия и сущности к царству и тирании, от добра и зла, весь спектр научных продуктов не может быть легко каталогизирован даже для мировых политических деятели и высокопоставленный церковный персонал запросили мнения, высказанные Томасом.
К 1252 году его опека под руководством Альберта Великого закончилась, и впоследствии он вернулся в Парижский университет для дальнейшего обучения, кульминацией которого стало получение лицензии на преподавание богословия в Париже в 1256 году.В 1259 г. Томас был назначен на различные преподавательские должности в Италии в Папской курии, а также в Орвието, Риме и Витербо. с 1261 по 1268 год. В это время Томас приложил много интеллектуальных усилий, комментируя и критикуя работы «Философ» Аристотеля с особым и проницательным анализом его теории этики и добродетели. Пара его концептуальных привязанность к Аристотелю с его уважением к арабским мыслителям, таким как Авиценна и Аверроэс, а также к еврейскому философу 17Маймонид, и то, что выясняется, является теологом / философом без спички.Это ум, который лучше всего можно описать как безграничный, оживленный, пребывающий в постоянном стремлении, живущий в том, что Пегис называет «исторически социальный характер своей философской работы». Он живет и думает в компании другие ».
Именно этот интеллектуальный динамизм дает пищу его критикам во время его второго срок в Парижском университете с 1268 года. Традиционные христианские платоники, действующие с благословения и согласия Августинцы сочли большую часть томистского метода слишком радикальным, чтобы успокоить его.Например, усилия Томаса по «Ассимилировать аристотелизм» казалось гораздо более агрессивным, чем необходимо. Другие бросили вызов психология Св. Фомы, чье видение человека и его или ее потенциальных возможностей было почти безграничным, ибо у Фомы расцвет человеческого фактора нормативен, а не экстраординарен. Критики святого Фомы сомневались, что человек свободен как моральный агент, независимо от того, может ли человек действительно понять сложности вселенной и ее многочисленные операции, и уместно ли даже рассматривать бессмертие души.Конечно, Сент-Томас не был сокращающийся фиолетовый, но диорама цветов, разрывающихся цветами, готовая взяться за реальность на всех уровнях, на которых она могла бы быть понял.
Для своих более традиционных коллег Сент-Томас действовал на периферии своим очень щедрость ума и мысли. В последний семестр в Парижском университете его продуктивность достигла апогея. в авторстве второй части его Summa Theologica - более миллиона слов по длине - наряду с другими текстами, которые он одновременно создавал.Объем его опуса потрясает даже современный наблюдатель. Как отмечает Энтони Кенни,
Если посмотреть на огромную часть его произведений между 1269–1273 гг., Можно поверить в то, что свидетельство его главного секретаря о том, что он имел обыкновение, как гроссмейстер на шахматном турнире, диктовать трем или четыре секретаря одновременно; можно почти верить дальнейшим свидетельствам того, что он мог диктовать связную прозу, в то время как он спал.
Несмотря на его выдающуюся работу и неизменную репутацию выдающегося богослова и философский анализ, его вторая поездка в Париж оставалась спорной до конца его срока.Томаса спросил его Доминиканское начальство основало доминиканский дом учебы в Неаполе, и во время своих путешествий он испытал ряд изменений. внутренне и внешне это навсегда изменило его когда-то укоренившиеся привычки. Некоторые утверждали, что Томас был мистически тронут и способен левитации. Он проявлял признаки таинственной внутренней молитвы и религиозного рвения. Кроме того, во время путешествия, катаясь на открытом телегу, его голова ударилась о низко свисающая ветка дерева.В 1274 году, когда он лечился в монастыре, его здоровье продолжало свое здоровье. отрицательные тенденции. После еще одного мистического опыта Томас показал своим коллегам, что его огромный объем работ, когда по сравнению с контекстом истинного, божественного знания «кажется соломинкой». На смертном одре, Последние слова св. Фомы Аквинского монахам-цистерцианцам означают его мирное принятие его надвигающейся кончины: «Это это мой покой во веки веков: Здесь я буду жить, потому что Я избрал его (Псалом 131: 14).”
Св. Фома Аквинский, которого часто называют «Всеобщим Учителем», умер в монастырь Фосанова 7 марта 1274 года. Хотя некоторые из его философских взглядов были оспорены в официальной программе ошибок в 1277 году, изложенных парижским епископом Этьеном Темпье, ни одна из проблем никогда не сводила на нет блеск Аквинского. Он был канонизирован Папой Иоанном XXII в 1323 году и провозглашен Ангельским Доктором Папой Пием V в 1567 году. В 1879 году Папа Римский Лев XIII охарактеризовал богословие Фомы как исчерпывающее изложение католической доктрины и постановил, что все католики семинарии и университеты должны быть основаны на томизме.В 1880 году святой Томас был объявлен покровителем всех католических учебных заведений.
Влияние томизма было подвержено приливу и отливу философских школ, нет более явных антагонистов, чем те, которые продвигают этическую и моральную относительность. В «Томасе» читатель сталкивается с надежная система, достойная любого интеллектуала; открытый, но устойчивый к хаосу, фиксируемый, когда это необходимо, и подлежащий тонкой настройке если оправдано. В этом тексте Томас дает методологию истины, «глубоко религиозную, чувствительную к ценности. традиции », в то время как« тем не менее новатор как в философии, так и в богословии.»Лейблы Антона Пегиса Фома Аквинский - «Гигант».
.Он стоял в гигантском прошлом; и хотя сам он был великаном, он всегда смотрел на его интеллектуальный рост с подлинным смирением того, кто, даже в своих высших умозрительных достижениях, принял плоды философской победы столько же, сколько и тех, кто шел до него, так и его собственной.