
ОГРН — это… Что такое ОГРН?
ОГРН — ОГРНЗ основной государственный регистрационный номер ср.: ГРН … Словарь сокращений и аббревиатур
ОСНОВНОЙ ГОСУДАРСТВЕННЫЙ РЕГИСТРАЦИОННЫЙ НОМЕР (ОГРН) ЮРИДИЧЕСКОГО ЛИЦА — согласно ГОСТ Р 6.30–2003 УСД «Унифицированная система организационно распорядительной документации. Требования к оформлению документов», – реквизит 05. Проставляют в соответствии с документами, выдаваемыми налоговыми органами … Делопроизводство и архивное дело в терминах и определениях
Основной государственный регистрационный номер — ОГРН (основной государственный регистрационный номер) государственный регистрационный номер записи о создании юридического лица либо записи о первом представлении в соответствии с Федеральным законом Российской Федерации «О государственной… … Википедия
ОГРНЗ — ОГРН ОГРНЗ основной государственный регистрационный номер ср.: ГРН … Словарь сокращений и аббревиатур
UniCredit Bank — (ЮниКредит Банк) Сведения о банке UniCredit, миссия, ценности и руководство Информация о банке UniCredit, миссия, ценности и руководство банка, бизнес и награды Содержание Содержание Определения описываемого предмета Общие о Реквизиты Группа bank … Энциклопедия инвестора
Основной государственный регистрационный номер — (ОГРН) с 1 июля 2002 года присваивается организации при ее создании, а точнее при внесении записи о ее государственной регистрации в Единый государственный реестр юридических лиц (ЕГРЮЛ). ОГРН используется в качестве номера регистрационного дела… … Банковская энциклопедия
Адреса и реквизиты для помощи пострадавшим от пожаров — Президент России, объявив о введении режима чрезвычайной ситуации в семи субъектах Федерации, призвал россиян не оставаться в стороне и прийти на помощь тем, кто лишился крова из за лесных пожаров. У многих семей вообще не осталось ничего всё… … Энциклопедия ньюсмейкеров
Контрольное число — Эта статья или раздел нуждается в переработке. Пожалуйста, улучшите статью в соответствии с правилами написания статей … Википедия
Контрольная цифра — Контрольное число, контрольная цифра разновидность контрольной суммы, добавляется (обычно в конец) длинных номеров с целью первичной проверки их правильности. Применяется с целью уменьшения вероятности ошибки при обработке таких номеров: машинном … Википедия
Контрольное число — Эта статья требует доработки. Вы поможете проекту, исправив и дополнив её. Надо разнести практическую информацию по соответствующим статьям. stas® 01:53, 14 сентября 2009 (MSD) Контрольное число, контрольная цифра разновидность контрольной су … Бухгалтерская энциклопедия
Узнать коды статистики по ИНН/ОГРН онлайн
Политика конфиденциальности (далее – Политика) разработана в соответствии с Федеральным законом от 27.07.2006. №152-ФЗ «О персональных данных» (далее – ФЗ-152). Настоящая Политика определяет порядок обработки персональных данных и меры по обеспечению безопасности персональных данных в сервисе vipiska-nalog.com(далее – Оператор) с целью защиты прав и свобод человека и гражданина при обработке его персональных данных, в том числе защиты прав на неприкосновенность частной жизни, личную и семейную тайну. В соответствии с законом, сервис vipiska-nalog.com несет информационный характер и не обязывает посетителя к платежам и прочим действиям без его согласия. Сбор данных необходим исключительно для связи с посетителем по его желанию и информировании об услугах сервиса vipiska-nalog.com.
Основные положения нашей политики конфиденциальности могут быть сформулированы следующим образом:
Мы не передаем Ваши персональную информацию третьим лицам. Мы не передаем Вашу контактную информацию в отдел продаж без Вашего на то согласия. Вы самостоятельно определяете объем раскрываемой персональной информации.
Собираемая информация
Мы собираем персональную информацию, которую Вы сознательно согласились раскрыть нам, для получения подробной информации об услугах компании. Персональная информация попадает к нам путем заполнения анкеты на сайте vipiska-nalog.com. Для того, чтобы получить подробную информацию об услугах, стоимости и видах оплат, Вам необходимо предоставить нам свой адрес электронной почты, имя (настоящее или вымышленное) и номер телефона. Эта информация предоставляется Вами добровольно и ее достоверность мы никак не проверяем.
Использование полученной информации
Информация, предоставляемая Вами при заполнении анкеты, обрабатывается только в момент запроса и не сохраняется. Мы используем эту информацию только для отправки Вам той информации, на которую Вы подписывались.
Предоставление информации третьим лицам
Мы очень серьезно относимся к защите Вашей частной жизни. Мы никогда не предоставим Вашу личную информацию третьим лицам, кроме случаев, когда это прямо может требовать Российское законодательство (например, по запросу суда). Вся контактная информация, которую Вы нам предоставляете, раскрывается только с Вашего разрешения. Адреса электронной почты никогда не
Код ОКОПФ узнать по ИНН
Политика конфиденциальности (далее – Политика) разработана в соответствии с Федеральным законом от 27.07.2006. №152-ФЗ «О персональных данных» (далее – ФЗ-152). Настоящая Политика определяет порядок обработки персональных данных и меры по обеспечению безопасности персональных данных в сервисе vipiska-nalog.com(далее – Оператор) с целью защиты прав и свобод человека и гражданина при обработке его персональных данных, в том числе защиты прав на неприкосновенность частной жизни, личную и семейную тайну. В соответствии с законом, сервис vipiska-nalog.com несет информационный характер и не обязывает посетителя к платежам и прочим действиям без его согласия. Сбор данных необходим исключительно для связи с посетителем по его желанию и информировании об услугах сервиса vipiska-nalog.com.
Основные положения нашей политики конфиденциальности могут быть сформулированы следующим образом:
Мы не передаем Ваши персональную информацию третьим лицам. Мы не передаем Вашу контактную информацию в отдел продаж без Вашего на то согласия. Вы самостоятельно определяете объем раскрываемой персональной информации.
Собираемая информация
Мы собираем персональную информацию, которую Вы сознательно согласились раскрыть нам, для получения подробной информации об услугах компании. Персональная информация попадает к нам путем заполнения анкеты на сайте vipiska-nalog.com. Для того, чтобы получить подробную информацию об услугах, стоимости и видах оплат, Вам необходимо предоставить нам свой адрес электронной почты, имя (настоящее или вымышленное) и номер телефона. Эта информация предоставляется Вами добровольно и ее достоверность мы никак не проверяем.
Использование полученной информации
Информация, предоставляемая Вами при заполнении анкеты, обрабатывается только в момент запроса и не сохраняется. Мы используем эту информацию только для отправки Вам той информации, на которую Вы подписывались.
Предоставление информации третьим лицам
Мы очень серьезно относимся к защите Вашей частной жизни. Мы никогда не предоставим Вашу личную информацию третьим лицам, кроме случаев, когда это прямо может требовать Российское законодательство (например, по запросу суда). Вся контактная инфо
Что такое ОКФС, его расшифровка и зачем он нужен
Политика конфиденциальности (далее – Политика) разработана в соответствии с Федеральным законом от 27.07.2006. №152-ФЗ «О персональных данных» (далее – ФЗ-152). Настоящая Политика определяет порядок обработки персональных данных и меры по обеспечению безопасности персональных данных в сервисе vipiska-nalog.com(далее – Оператор) с целью защиты прав и свобод человека и гражданина при обработке его персональных данных, в том числе защиты прав на неприкосновенность частной жизни, личную и семейную тайну. В соответствии с законом, сервис vipiska-nalog.com несет информационный характер и не обязывает посетителя к платежам и прочим действиям без его согласия. Сбор данных необходим исключительно для связи с посетителем по его желанию и информировании об услугах сервиса vipiska-nalog.com.
Основные положения нашей политики конфиденциальности могут быть сформулированы следующим образом:
Мы не передаем Ваши персональную информацию третьим лицам. Мы не передаем Вашу контактную информацию в отдел продаж без Вашего на то согласия. Вы самостоятельно определяете объем раскрываемой персональной информации.
Собираемая информация
Мы собираем персональную информацию, которую Вы сознательно согласились раскрыть нам, для получения подробной информации об услугах компании. Персональная информация попадает к нам путем заполнения анкеты на сайте vipiska-nalog.com. Для того, чтобы получить подробную информацию об услугах, стоимости и видах оплат, Вам необходимо предоставить нам свой адрес электронной почты, имя (настоящее или вымышленное) и номер телефона. Эта информация предоставляется Вами добровольно и ее достоверность мы никак не проверяем.
Использование полученной информации
Информация, предоставляемая Вами при заполнении анкеты, обрабатывается только в момент запроса и не сохраняется. Мы используем эту информацию только для отправки Вам той информации, на которую Вы подписывались.
Предоставление информации третьим лицам
Мы очень серьезно относимся к защите Вашей частной жизни. Мы никогда не предоставим Вашу личную информацию третьим лицам, кроме случаев, когда это прямо может требовать Российское законодательство (например, по запросу суда). Вся контактная информация, которую Вы нам предоставляете, раскрывается только с Вашего разрешения. Адреса электронной почты никогда не публикуются на Сайте и используются нами только для связи с Вами.
Защита данных
Администрация Сайта осуществляет защиту информации, предоставленной пользователями, и использует ее только в соответствии с принятой Политикой конфиденциальности на Сайте.
Страница не найдена · GitHub Pages
Страница не найдена · Страницы GitHubФайл не найден
Сайт, настроенный по этому адресу, не содержать запрошенный файл.
Если это ваш сайт, убедитесь, что регистр имени файла соответствует URL.
Для корневых URL (например, http://example.com/ ) вы должны предоставить index.html файл.
Прочтите полную документацию для получения дополнительной информации об использовании GitHub Pages .
,
Классификация — это процесс прогнозирования класса заданных точек данных. Классы иногда называют целями / метками или категориями. Классификационное прогнозное моделирование — это задача аппроксимации функции отображения (f) входных переменных (X) в дискретные выходные переменные (y).
Например, обнаружение спама у поставщиков услуг электронной почты можно определить как проблему классификации. Это двоичная классификация, поскольку существует только 2 класса спама и спама.Классификатор использует некоторые обучающие данные, чтобы понять, как заданные входные переменные связаны с классом. В этом случае в качестве обучающих данных должны использоваться известные спамовые и не спамовые сообщения. Когда классификатор обучен точно, его можно использовать для обнаружения неизвестного адреса электронной почты.
Классификация относится к категории контролируемого обучения, где цели также снабжены входными данными. Существует множество приложений классификации во многих областях, таких как одобрение кредита, медицинская диагностика, целевой маркетинг и т. Д.
Существует два типа учащихся, классифицируемых как ленивые и активные.
- Ленивые ученики
Ленивые ученики просто сохраняют данные обучения и ждут, пока не появятся данные тестирования. Когда это происходит, классификация проводится на основе наиболее связанных данных в сохраненных обучающих данных. По сравнению с активными учениками, у ленивых учеников меньше времени на обучение, но больше времени на прогнозирование.
Пр. k-ближайший сосед, аргументация на основе случая
2.Активные ученики
Активные ученики создают модель классификации на основе заданных данных обучения перед получением данных для классификации. Он должен иметь возможность придерживаться единственной гипотезы, охватывающей все пространство экземпляров. Из-за построения модели у активных учеников требуется много времени на обучение и меньше времени на прогнозирование.
Пр. Дерево решений, наивный байесовский алгоритм, искусственные нейронные сети
Сейчас доступно множество алгоритмов классификации, но невозможно сделать вывод, какой из них лучше другого.Это зависит от приложения и характера доступного набора данных. Например, если классы линейно разделимы, линейные классификаторы, такие как логистическая регрессия, линейный дискриминант Фишера, могут превзойти сложные модели и наоборот.
Дерево решений
Дерево решений строит модели классификации или регрессии в виде древовидной структуры. Он использует набор правил «если-то», который является взаимоисключающим и исчерпывающим для классификации. Правила изучаются последовательно с использованием обучающих данных по одному.Каждый раз при изучении правила кортежи, на которые распространяется действие правила, удаляются. Этот процесс продолжается на обучающем наборе до тех пор, пока не будет выполнено условие завершения.
Дерево строится по принципу нисходящей рекурсии «разделяй и властвуй». Все атрибуты должны быть категоричными. В противном случае их следует заранее дискретизировать. Атрибуты в верхней части дерева имеют большее влияние на классификацию и идентифицируются с использованием концепции получения информации.
Дерево решений можно легко переоснастить, создавая слишком много ветвей, и оно может отражать аномалии из-за шума или выбросов.Чрезмерно подогнанная модель имеет очень низкую производительность на невидимых данных, хотя она дает впечатляющую производительность на данных обучения. Этого можно избежать путем предварительной обрезки, которая прерывает строительство дерева раньше, или после обрезки, которая удаляет ветви с полностью выросшего дерева.
Наивный Байес
Наивный Байесовский классификатор — это вероятностный классификатор, созданный на основе теоремы Байеса при простом предположении, что атрибуты условно независимы.
Классификация проводится путем определения максимального апостериорного значения, которое представляет собой максимальное значение P (Ci | X ) с применением вышеуказанного предположения к теореме Байеса.Это предположение значительно снижает вычислительные затраты за счет только подсчета распределения классов. Несмотря на то, что в большинстве случаев это предположение неверно, поскольку атрибуты зависимы, наивный байесовский метод на удивление показал впечатляющие результаты.
Наивный байесовский алгоритм — очень простой в реализации алгоритм, который в большинстве случаев дает хорошие результаты. Его можно легко масштабировать до более крупных наборов данных, поскольку для этого требуется линейное время, а не с помощью дорогостоящего итеративного приближения, как для многих других типов классификаторов.
Наивный байесовский метод может страдать от проблемы, называемой проблемой нулевой вероятности. Когда условная вероятность равна нулю для определенного атрибута, он не может дать действительный прогноз. Это должно быть исправлено явно с помощью оценки Лапласа.
Искусственные нейронные сети
Искусственные нейронные сети — это набор подключенных устройств ввода / вывода, в которых каждое соединение имеет связанный с ним вес, который был запущен психологами и нейробиологами для разработки и тестирования вычислительных аналогов нейронов.На этапе обучения сеть обучается, регулируя веса , , чтобы иметь возможность предсказать правильную метку класса входных кортежей.
Сейчас доступно множество сетевых архитектур, таких как прямая связь, сверточная, рекуррентная и т. Д. Подходящая архитектура зависит от применения модели. В большинстве случаев модели с прямой связью дают достаточно точные результаты, и особенно для приложений обработки изображений сверточные сети работают лучше.
В модели может быть несколько скрытых слоев, в зависимости от сложности функции, которая будет отображена моделью.Наличие большего количества скрытых слоев позволит моделировать сложные отношения, такие как глубокие нейронные сети.
Однако, когда есть много скрытых слоев, требуется много времени для тренировки и настройки существ. Другой недостаток — плохая интерпретируемость модели по сравнению с другими моделями, такими как деревья принятия решений, из-за неизвестного символического значения изученных весов.
Но искусственные нейронные сети показали впечатляющие результаты в большинстве реальных приложений. Это высокая толерантность к шумным данным и способность классифицировать необученные шаблоны.Обычно искусственные нейронные сети работают лучше с непрерывными входами и выходами.
Все вышеперечисленные алгоритмы являются активными учениками, поскольку они обучают модель заранее, чтобы обобщить обучающие данные и использовать их для прогнозирования позже.
k -Nearest Neighbor (KNN)
k -Nearest Neighbor — это алгоритм отложенного обучения, который сохраняет все экземпляры, соответствующие точкам данных обучения в n-мерном пространстве. Когда получены неизвестные дискретные данные, он анализирует k ближайших сохраненных экземпляров (ближайших соседей) и возвращает наиболее распространенный класс в качестве прогноза, а для данных с действительным знаком он возвращает среднее значение k ближайших соседей.
В алгоритме взвешенного по расстоянию ближайшего соседа он взвешивает вклад каждого из k соседей в соответствии с их расстоянием, используя следующий запрос, дающий больший вес ближайшим соседям.
Запрос вычисления расстоянияОбычно KNN устойчив к зашумленным данным, поскольку он усредняет k-ближайших соседей.
Теперь, когда мы познакомились с глубинным обучением и сверточными нейронными сетями в сообщении в блоге на прошлой неделе в LeNet, мы собираемся сделать шаг назад и начать изучать машинное обучение в контексте классификации изображений более глубоко.
Для начала рассмотрим классификатор k-Nearest Neighbor (k-NN), возможно, самый простой и понятный алгоритм машинного обучения . Фактически, k-NN — это , настолько простое , что оно вообще не выполняет никакого «обучения»!
В оставшейся части этого сообщения я подробно расскажу, как работает классификатор k-NN.Затем мы применим k-NN к набору данных Kaggle Dogs vs. Cats, подмножеству набора данных Asirra от Microsoft.
Цель набора данных «Собаки против кошек», как следует из названия, состоит в том, чтобы классифицировать, содержит ли данное изображение dog или cat . Мы будем использовать этот набор данных и в будущих сообщениях в блогах (причины, которые я объясню позже в этом руководстве), поэтому убедитесь, что вы нашли время, чтобы прочитать этот пост и ознакомиться с набором данных.
С учетом всего сказанного, давайте приступим к реализации k-NN для классификации изображений для распознавания собак vs.кошки в изображениях!
Классификатор к-НН для классификации изображений
После того, как вы впервые попробовали сверточные нейронные сети на прошлой неделе, вы, вероятно, почувствуете, что мы делаем большой шаг на назад , обсуждая сегодня k-NN.
Что дает?
Ну вот и сделка.
Однажды я написал (неоднозначный) пост в блоге о том, как выйти из подножки глубокого обучения и получить некоторую перспективу. Несмотря на антагонистическое название, общая тема этой публикации была сосредоточена вокруг различных тенденций в истории машинного обучения, таких как нейронные сети (и то, как исследования в области нейронных сетей почти прекратились в 70-80-х годах), опорные векторные машины и методы ансамбля.
Когда был представлен каждый из этих методов, исследователи и практики были вооружены новыми мощными техниками — по сути, им дали молоток, и каждая проблема выглядела как гвоздь , тогда как на самом деле им было нужно всего несколько простые повороты головки Филлипса для решения конкретной проблемы.
У меня для вас новость: Глубокое обучение ничем не отличается.
Посетите подавляющее большинство популярных конференций по машинному обучению и компьютерному зрению и ознакомьтесь с последним списком публикаций.Какая общая тема?
Глубокое обучение.
Затем перейдите в крупные группы LinkedIn, связанные с компьютерным зрением и машинным обучением. О чем спрашивают многие?
Как применить глубокое обучение к своим наборам данных.
После этого перейдите на популярные разделы Reddit по информатике, такие как / r / machinelearning. Какие руководства пользуются наибольшей популярностью?
Как вы уже догадались: глубокое обучение.
Итог:
Да, я расскажу вам о глубоком обучении и сверточных нейронных сетях в этом блоге — , но вы чертовски хорошо поймете, что глубокое обучение — это просто ИНСТРУМЕНТ, и, как и любой другой инструмент, есть правильный и неправильное время использовать.
Из-за этого для нас важно понять основы машинного обучения, прежде чем мы продвинемся слишком далеко. В течение следующих нескольких недель я буду обсуждать основы машинного обучения и нейронных сетей, в конечном итоге перейдя к глубокому обучению (где вы сможете больше оценить внутреннюю работу этих алгоритмов).
Набор данных Kaggle Dogs vs.Cats
Набор данных «Собаки против кошек» несколько лет назад был частью задачи Kaggle. Сама задача была проста: по изображению, предсказать, есть ли на нем собака или кошка:
 Рисунок 1: Примеры из игры Kaggle Dogs vs.Набор данных кошек.
Рисунок 1: Примеры из игры Kaggle Dogs vs.Набор данных кошек.Достаточно просто, но если вы что-то знаете о классификации изображений, вы поймете, что это:
- Вариант точки обзора
- Изменение шкалы
- Деформация
- Окклюзия
- Фоновый беспорядок
- Внутриклассовая вариация
Проблема значительно сложнее , чем может показаться на поверхности.
Просто случайным образом угадав , вы сможете достичь 50% точности (так как есть только две метки класса).Алгоритм машинного обучения должен достичь точности> 50%, чтобы продемонстрировать, что он действительно чему-то «научился» (или обнаружил базовый шаблон в данных).
Лично мне нравится задача «Собаки против кошек», особенно за обучение глубокому обучению.
Почему?
Набор данных достаточно прост, чтобы осознать — всего два класса: «собака» или «кошка» .
Однако набор данных хорошего размера, содержащий 25000 изображений в обучающих данных.Это означает, что у вас достаточно данных для обучения сверточных нейронных сетей, требующих больших объемов данных, с нуля.
Мы будем часто использовать этот набор данных в будущих публикациях в блогах. Я фактически включил его в раздел «Загрузки» этого сообщения в блоге для вашего удобства, так что прокрутите вниз, чтобы получить код + данные, прежде чем продолжить.
Структура проекта
Скачав архив для этого сообщения блога, распакуйте его в удобное место. Оттуда давайте посмотрим на структуру каталогов проекта:
$ tree --filelimit 10 ,├── kaggle_dogs_vs_cats │ └── train [25000 записей превышает предел файла, не открывает каталог] └── knn_classifier.py 2 каталога, 1 файл
Набор данных Kaggle включен в каталог kaggle_dogs_vs_cats / train (он взят из train.zip , доступного на веб-странице Kaggle).
Сегодня мы рассмотрим один скрипт Python — knn_classifier.py . Этот файл загрузит набор данных, установит и запустит классификатор K-NN и распечатает показатели оценки.
Как работает классификатор k-NN?
Классификатор k-ближайшего соседа — это , безусловно, , самый простой алгоритм машинного обучения / классификации изображений. Фактически, это настолько простое , что фактически ничему не «учится».
Внутри этот алгоритм просто полагается на расстояние между векторами признаков, во многом как при построении поисковой системы изображений — только на этот раз у нас есть меток , связанных с каждым изображением, поэтому мы можем предсказать и вернуть фактическую категорию для изображения. ,
Проще говоря, алгоритм k-NN классифицирует неизвестные точки данных, находя наиболее распространенного класса среди k-ближайших примеров. Каждая точка данных в k ближайших примерах дает голос, и категория с наибольшим количеством голосов побеждает!
Или простым языком: «Скажите мне, кто ваши соседи, и я скажу вам, кто вы»
Чтобы визуализировать это, взгляните на следующий пример игрушки, где я нанес «пушистость» животных по оси x и легкость их шерсти по оси y :
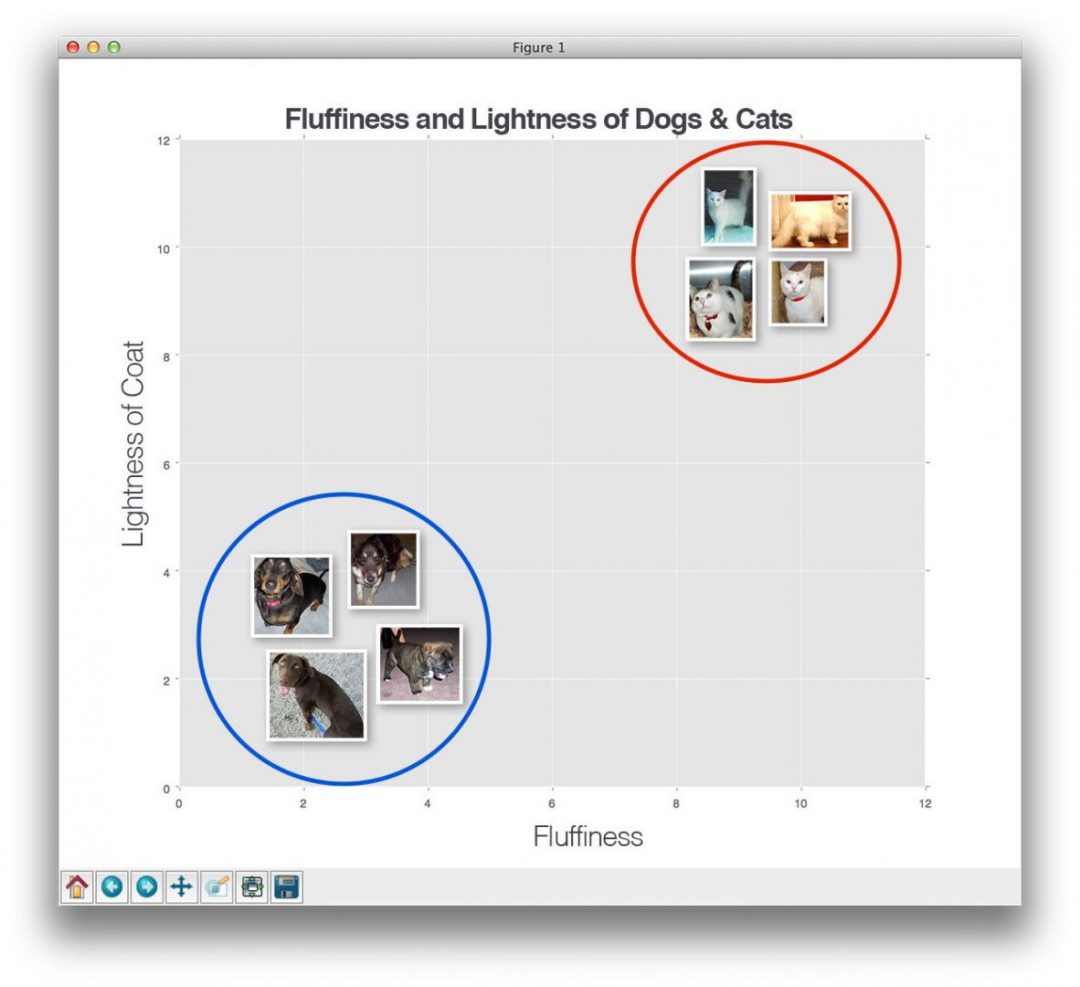 Рис. 2: Нанесение пушистости животных по оси x и легкости их шерсти по оси y .
Рис. 2: Нанесение пушистости животных по оси x и легкости их шерсти по оси y .Здесь мы видим, что есть две категории изображений и что каждая из точек данных в каждой соответствующей категории сгруппирована относительно близко друг к другу в пространстве измерений n-. У наших собак, как правило, темная шерсть, которая не очень пушистая, а у наших кошек очень светлая, но очень пушистая.
Это означает, что расстояние между двумя точками данных в красном круге на намного меньше , чем расстояние между точкой данных в красном круге и точкой данных в синем круге .
Чтобы применить классификацию k-ближайшего соседа, нам нужно определить метрику расстояния или функцию подобия. Обычный выбор включает евклидово расстояние:
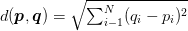 Рисунок 3: Евклидово расстояние.
Рисунок 3: Евклидово расстояние.И расстояние от Манхэттена до городского квартала:
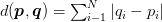 Рисунок 4: Расстояние Манхэттен / городской квартал.
Рисунок 4: Расстояние Манхэттен / городской квартал.В зависимости от типа данных могут использоваться другие метрики расстояния / функции подобия (расстояние хи-квадрат часто используется для распределений [i.е., гистограммы]). В сегодняшнем сообщении в блоге для простоты мы будем использовать евклидово расстояние для сравнения изображений на предмет сходства.
Реализация k-NN для классификации изображений с помощью Python
Теперь, когда мы обсудили, что такое алгоритм k-NN, а также набор данных, к которому мы собираемся его применить, давайте напишем код для фактического выполнения классификации изображений с использованием k-NN.
Откройте новый файл, назовите его knn_classifier.py , и давайте получим код:
# импортировать необходимые пакеты из склеарна.соседи импортируют KNeighborsClassifier из sklearn.model_selection import train_test_split из путей импорта imutils импортировать numpy как np импорт argparse импорт imutils импорт cv2 импорт ОС
Мы начинаем со строк , строки 2–9, с импорта необходимых пакетов Python. Если вы еще не установили библиотеку scikit-learn, следуйте этим инструкциям и установите ее сейчас.
Примечание: Это сообщение в блоге было обновлено для обеспечения совместимости с будущим scikit-learn == 0.20 , где sklearn.cross_validation был заменен на sklearn.model_selection .
Во-вторых, мы будем использовать библиотеку imutils, пакет, который я создал для хранения общих функций обработки компьютерного зрения. Если у вас не установлено imutils , вам нужно сделать это сейчас:
$ pip install imutils
Далее мы собираемся определить два метода для получения входного изображения и преобразования его в вектор признаков или список чисел, которые количественно определяют содержимое изображения.Первый метод можно увидеть ниже:
def image_to_feature_vector (изображение, размер = (32, 32)): # изменить размер изображения до фиксированного размера, затем сгладить изображение в # список яркости необработанных пикселей вернуть cv2.resize (изображение, размер) .flatten ()
Метод image_to_feature_vector — чрезвычайно наивная функция, которая просто берет входное изображение и изменяет его размер до фиксированной ширины и высоты ( размер ), а затем сглаживает яркость пикселей RGB в один список чисел.
Это означает, что наше входное изображение будет уменьшено до 32 x 32 пикселей, и при наличии трех каналов для каждого красного, зеленого и синего компонентов соответственно, наш выходной «вектор характеристик» будет списком 32 x 32 х 3 = 3072 номеров.
Строго говоря, вывод image_to_feature_vector не является истинным «вектором признаков», поскольку мы склонны думать о «характеристиках» и «дескрипторах» как о абстрактных количественных определениях содержимого изображения.
Кроме того, использование яркости необработанных пикселей в качестве входных данных для алгоритмов машинного обучения имеет тенденцию давать плохие результаты, поскольку даже небольшие изменения в повороте, перемещении, точке обзора, масштабе и т. Д. Могут существенно повлиять на само изображение (и, следовательно, на представление выходных характеристик) ,
Примечание: Как мы узнаем в последующих руководствах, сверточные нейронные сети получают фантастические результаты, используя в качестве входных данных необработанные значения интенсивности пикселей — но это потому, что они изучают надежный набор различающих фильтров в процессе обучения.
Затем мы определяем наш второй метод, называемый extract_color_histogram :
def extract_color_histogram (изображение, ячейки = (8, 8, 8)): # извлекаем гистограмму цвета 3D из цветового пространства HSV, используя # указанное количество бинов на канал hsv = cv2.cvtColor (изображение, cv2.COLOR_BGR2HSV) hist = cv2.calcHist ([hsv], [0, 1, 2], Нет, ячейки, [0, 180, 0, 256, 0, 256]) # обрабатываем нормализацию гистограммы, если мы используем OpenCV 2.4.X если imutils.is_cv2 (): hist = cv2.normalize (hist) # в противном случае выполнить нормализацию "на месте" в OpenCV 3 (I # лично ненавижу то, как это делается еще: cv2.normalize (hist, hist) # возвращаем сглаженную гистограмму как вектор признаков вернуть hist.flatten ()
Как следует из названия, эта функция принимает на входе изображение , и строит гистограмму цвета для характеристики цветового распределения изображения.
Сначала мы конвертируем наше изображение в цветовое пространство HSV в строке 19 .Затем мы применяем функцию cv2.calcHist для вычисления трехмерной цветовой гистограммы для изображения ( строки 20 и 21 ). Вы можете узнать больше о вычислении гистограмм цвета в этом посте. Вам также может быть интересно применить цветовые гистограммы к поисковым системам изображений и вообще, как сопоставить цветовые гистограммы на предмет сходства.
Получив наш вычисленный hist , мы затем нормализуем его, заботясь об использовании соответствующей сигнатуры функции cv2.normalize на основе нашей версии OpenCV ( строки 24-30 ).
Учитывая 8 бинов для каждого из каналов оттенка, насыщенности и значения соответственно, наш окончательный вектор признаков имеет размер 8 x 8 x 8 = 512 , таким образом, наше изображение характеризуется вектором признаков 512 d . ,
Затем давайте проанализируем аргументы нашей командной строки:
# построить аргумент parse и разобрать аргументы
ap = argparse.ArgumentParser ()
ap.add_argument ("- d", "--dataset", required = True,
help = "путь к входному набору данных")
ап.add_argument ("- k", "--neighbors", type = int, по умолчанию = 1,
help = "# ближайших соседей для классификации")
ap.add_argument ("- j", "--jobs", type = int, по умолчанию = -1,
help = "Количество заданий для расстояния k-NN (-1 использует все доступные ядра)")
args = vars (ap.parse_args ())
Нам нужен только один аргумент командной строки, за которым следуют два необязательных аргумента, каждый из которых подробно описан ниже:
-
--dataset: это путь к нашему входному каталогу набора данных Kaggle Dogs vs. Cats. -
--neighbors: Здесь мы можем указать количество ближайших соседей, которые учитываются при классификации данной точки данных. По умолчанию это значение равно на , что означает, что изображение будет классифицировано путем нахождения ближайшего соседа в пространстве n – размерности и последующего присвоения метки ближайшего изображения. В публикации на следующей неделе я продемонстрирую, как автоматически настроить k для достижения оптимальной точности. -
--jobs: Поиск ближайшего соседа для данного изображения требует, чтобы мы вычислили расстояние от нашего входного изображения до каждого второго изображения в нашем наборе данных .Очевидно, что это операция O (N) , которая масштабируется линейно. Для больших наборов данных это может стать чрезмерно медленным. Чтобы ускорить процесс, мы можем распределить вычисление ближайших соседей по нескольким процессорам / ядрам нашей машины. Установка--jobsна-1гарантирует, что все процессоров / ядер будут использоваться для ускорения процесса классификации.
Примечание: Мы также можем ускорить классификатор k-NN, используя специализированные структуры данных, такие как kd-деревья или алгоритмы приблизительного ближайшего соседа, такие как FLANN или Annoy.На практике эти алгоритмы могут сократить поиск ближайшего соседа примерно до O (log N) ; однако, для простоты в этом посте, мы выполним исчерпывающий поиск ближайшего соседа.
Теперь мы готовы подготовить наши изображения для извлечения признаков:
# возьмите список изображений, которые мы будем описывать
print ("[ИНФОРМАЦИЯ] с описанием изображений ...")
imagePaths = list (paths.list_images (args ["набор данных"]))
# инициализируем матрицу яркости сырых пикселей, матрицу функций,
# и список ярлыков
rawImages = []
features = []
label = []
Строка 47 захватывает пути ко всем 25 000 обучающим изображениям с диска.
Затем мы инициализируем три списка ( строки 51-53 ) для хранения интенсивностей пикселей необработанного изображения (вектор признаков 3072-d ), другой — для хранения признаков гистограммы (вектор признаков 512-d ) и наконец, класс обозначает себя («собака» или «кошка»).
Давайте перейдем к извлечению функций из нашего набора данных:
# перебираем входные изображения
для (i, imagePath) в перечислении (imagePaths):
# загружаем изображение и извлекаем метку класса (предполагая, что наш
# путь в формате: / путь / к / набору данных / {класс}.{IMAGE_NUM} .jpg
изображение = cv2.imread (imagePath)
label = imagePath.split (os.path.sep) [- 1] .split (".") [0]
# извлекаем необработанные "особенности" интенсивности пикселей, за которыми следует цвет
# гистограмма для характеристики цветового распределения пикселей
# на изображении
пикселей = image_to_feature_vector (изображение)
hist = extract_color_histogram (изображение)
# обновить необработанные изображения, функции и матрицы меток,
# соответственно
rawImages.append (пиксели)
функции.Append (Hist)
labels.append (ярлык)
# показывать обновление каждые 1000 изображений
если i> 0 и i% 1000 == 0:
print ("[ИНФОРМАЦИЯ] обработано {} / {}". format (i, len (imagePaths)))
Мы начинаем перебирать наши входные изображения на Строке 56 . Каждое изображение загружается с диска, а метка класса извлекается из imagePath ( строки 59 и 60, ).
Мы применяем функции image_to_feature_vector и extract_color_histogram к строкам 65 и 66 — эти функции используются для извлечения наших векторов признаков из входного изображения .
Учитывая наши метки функций, мы затем обновляем соответствующие rawImages , features и списки в строках 70-72 .
Наконец, мы отображаем обновление в нашем терминале, чтобы информировать нас о ходе извлечения признаков каждые 1000 изображений ( строки 75 и 76, ).
Вам может быть любопытно, сколько памяти занимают наши rawImages и с матрицами — следующий блок кода сообщит нам при выполнении:
# показать некоторую информацию о памяти, используемой необработанными изображениями
# матрица и матрица признаков
rawImages = np.Массив (rawImages)
features = np.array (функции)
label = np.array (метки)
print ("[ИНФОРМАЦИЯ] матрица пикселей: {: .2f} МБ" .format (
rawImages.nbytes / (1024 * 1000.0)))
print ("[ИНФОРМАЦИЯ] матрица функций: {: .2f} МБ" .format (
features.nbytes / (1024 * 1000.0)))
Начнем с преобразования наших списков в массивы NumPy. Затем мы используем атрибут .nbytes массива NumPy для отображения количества мегабайт памяти, используемой представлениями (около 75 МБ для необработанных пикселей и 50 МБ для цветовых гистограмм.Это означает, что мы можем легко сохранить () в основной памяти).
Затем нам нужно разделить наши данные на два разделения — одно для обучения и другое для тестирования :
# разделить данные на части для обучения и тестирования, используя 75% # данных для обучения и оставшиеся 25% для тестирования (trainRI, testRI, trainRL, testRL) = train_test_split ( rawImages, label, test_size = 0,25, random_state = 42) (trainFeat, testFeat, trainLabels, testLabels) = train_test_split ( функции, метки, test_size = 0.25, random_state = 42)
Здесь мы будем использовать 75% наших данных для обучения, а оставшиеся 25% для тестирования алгоритма k-NN.
Давайте применим классификатор k-NN к яркости необработанных пикселей:
# обучить и оценить классификатор k-NN по яркости необработанных пикселей
print ("[ИНФОРМАЦИЯ] оценка точности сырых пикселей ...")
model = KNeighborsClassifier (n_neighbors = args ["соседи"],
n_jobs = арг [ "работа"])
model.fit (trainRI, trainRL)
acc = model.score (testRI, testRL)
print ("[ИНФОРМАЦИЯ] необработанная точность пикселей: {:.2f}% ". Формат (acc * 100))
Здесь мы создаем экземпляр объекта KNeighborsClassifier из библиотеки scikit-learn, используя предоставленное число --neighbours и --jobs .
Затем мы «обучаем» нашу модель, позвонив по номеру .fit на линии Line 99 с последующей оценкой данных тестирования на Line 100 .
Аналогичным образом мы также можем обучить и оценить классификатор k-NN на наших представлениях гистограммы:
# обучить и оценить классификатор k-NN на гистограмме
# представлений
print ("[ИНФОРМАЦИЯ] оценивает точность гистограммы... ")
model = KNeighborsClassifier (n_neighbors = args ["соседи"],
n_jobs = арг [ "работа"])
model.fit (trainFeat, trainLabels)
acc = model.score (testFeat, testLabels)
print ("[ИНФОРМАЦИЯ] точность гистограммы: {: .2f}%". формат (acc * 100))
Результаты классификации изображений k-NN
Чтобы протестировать наш классификатор изображений k-NN, убедитесь, что вы загрузили исходный код этого сообщения в блоге, используя форму «Загрузки» , которая находится в нижней части этого руководства.
Набор данных Kaggle Dogs vs. Cats включен в загрузку.
Оттуда просто выполните следующую команду:
$ python knn_classifier.py --dataset kaggle_dogs_vs_cats
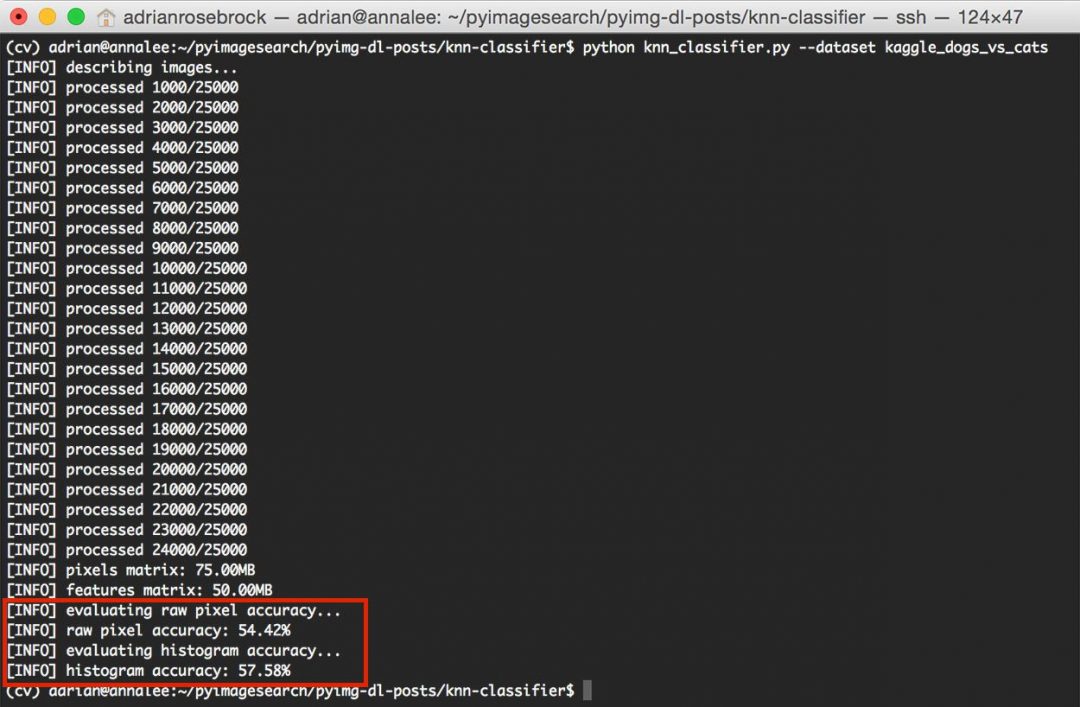
Сначала вы увидите, что наши изображения описываются и количественно оцениваются с помощью функций image_to_feature_vector и extract_color_histogram :
 Рисунок 5: Количественная оценка и извлечение характеристик из набора данных «Собаки против кошек».
Рисунок 5: Количественная оценка и извлечение характеристик из набора данных «Собаки против кошек».Этот процесс не должен занимать более 1–3 минут в зависимости от скорости вашего компьютера.
После завершения процесса извлечения признаков мы можем увидеть некоторую информацию о размере (в МБ) наших представлений признаков:
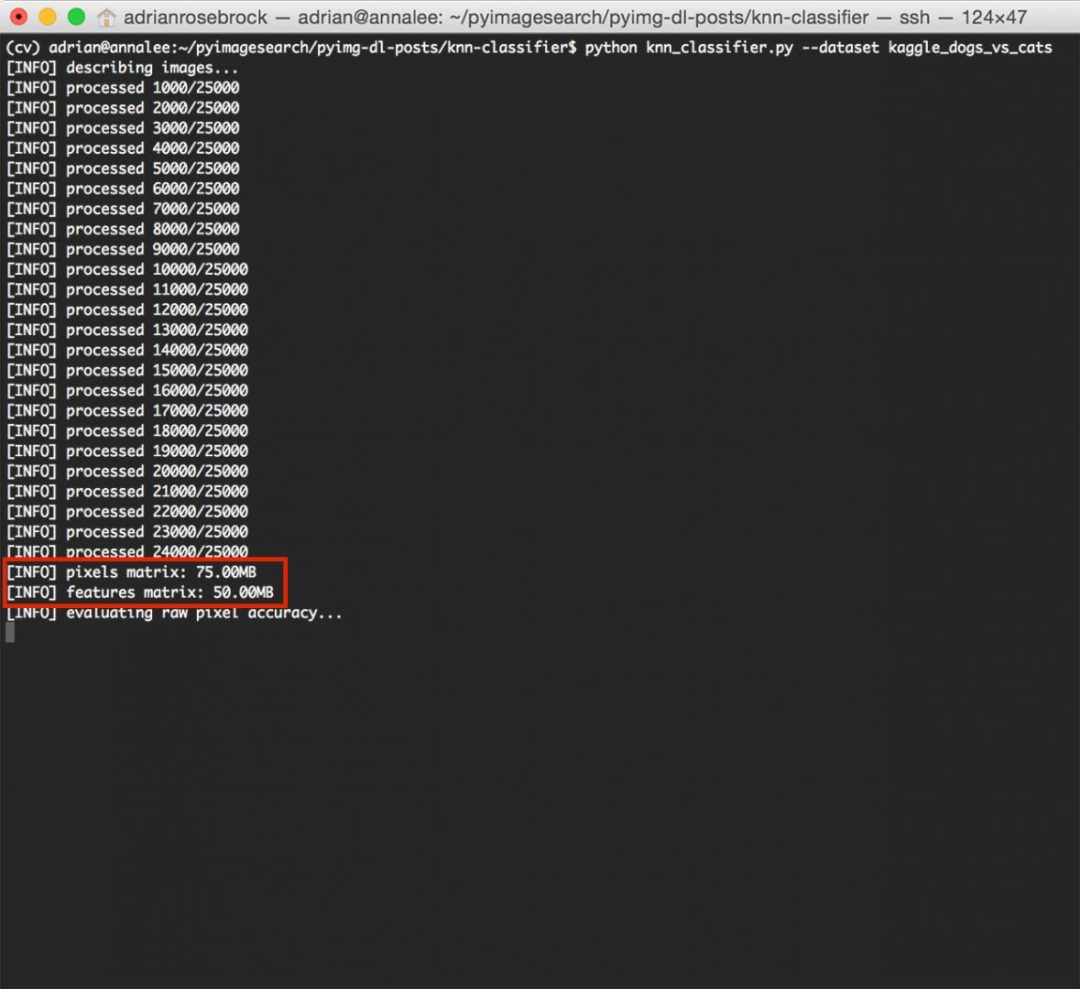 Рисунок 6: Измерение размера наших матриц функций.
Рисунок 6: Измерение размера наших матриц функций.Необработанные пиксельные функции занимают 75 МБ, в то время как цветовые гистограммы требуют только 50 МБ ОЗУ.
Наконец, алгоритм k-NN обучается и оценивается как для яркости необработанных пикселей, так и для цветовых гистограмм:
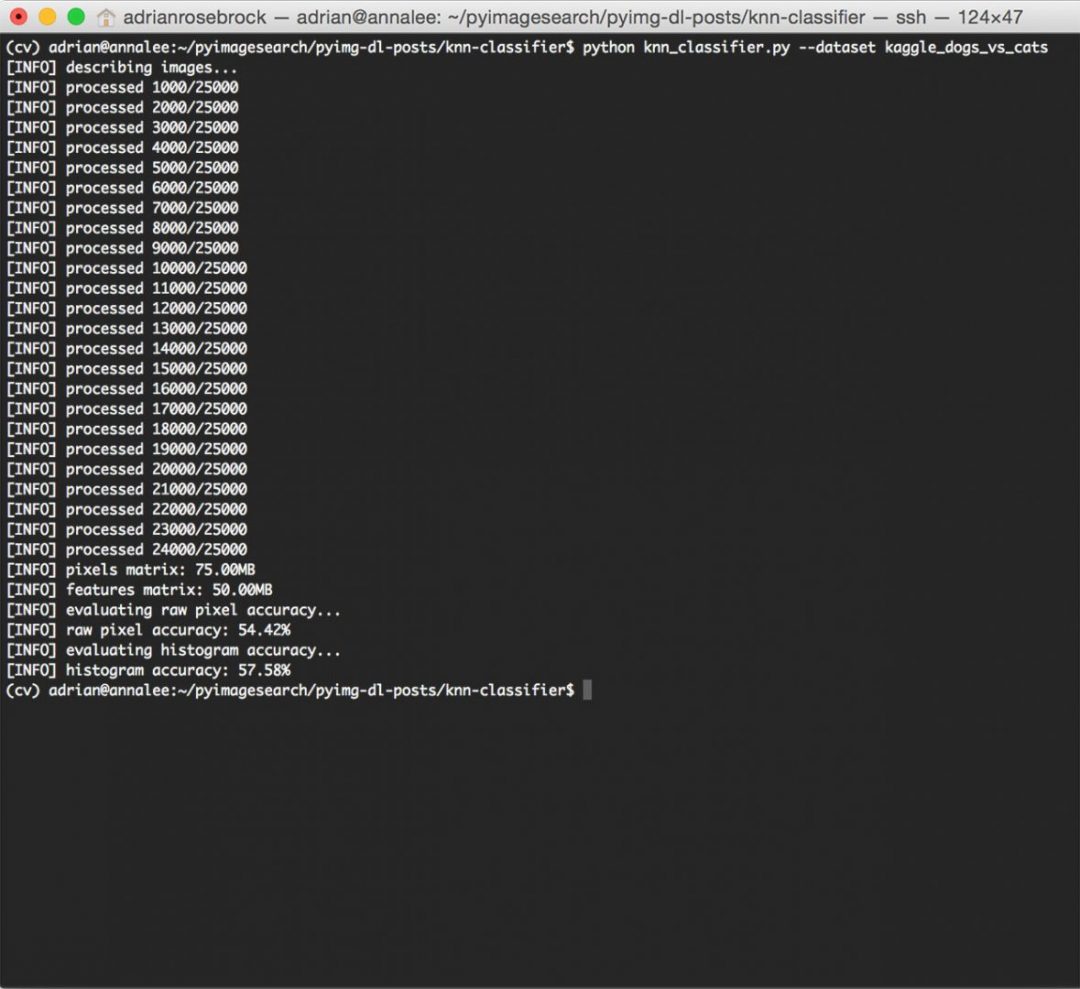 Рисунок 7: Оценка нашего алгоритма k-NN для классификации изображений.
Рисунок 7: Оценка нашего алгоритма k-NN для классификации изображений.Как показано на рисунке выше, используя необработанных пикселей с интенсивностью , мы смогли достичь точности 54,42%. С другой стороны, применение k-NN к цветным гистограммам позволило немного улучшить точность 57,58% .
В обоих случаях мы смогли получить точность> 50%, демонстрируя, что в изображениях присутствует базовая закономерность как для яркости необработанных пикселей, так и для цветовых гистограмм.
Впрочем, точность 57% оставляет желать лучшего.
И, как вы могли догадаться, цветовые гистограммы — не лучший способ отличить собаку от кошки:
- Есть коричневые собаки. А еще есть коричневые кошки.
- Есть черные собаки. И есть черные кошки.
- И, конечно же, собака и кошка могут появляться в одной и той же среде (например, в доме, парке, пляже и т. Д.), Где распределение цветов фона схоже.
Из-за этого строгое использование цвета — не лучший выбор для описания разницы между собаками и кошками, но это нормально.Целью этого сообщения в блоге было просто представить концепцию классификации изображений с использованием алгоритма k-NN.
Мы можем легко применить методы для получения более высокой точности. И, как мы увидим, с помощью сверточных нейронных сетей может без особых усилий достичь точности> 95%, — но я оставлю это для будущего обсуждения, когда мы лучше поймем классификацию изображений.
Хотите узнать больше о сверточных нейронных сетях прямо сейчас?
Если вам понравился этот учебник по классификации изображений, определенно захочет взглянуть на курс PyImageSearch Gurus — самый полный и исчерпывающий курс по компьютерному зрению на сегодняшний день в Интернете.
Внутри курса вы найдете более 168 уроков , охватывающих 2161+ страниц контента на Deep Learning , Convolutional Neural Networks , Image Classification, F ace Recognition , и многое другое .
Чтобы узнать больше о курсе PyImageSearch Gurus (и получить 10 БЕСПЛАТНЫХ уроков + программа курса ), просто нажмите кнопку ниже:
Щелкните здесь, чтобы узнать больше о PyImageSearch Gurus!Можем ли мы сделать лучше?
Вы можете спросить, можем ли мы добиться большей точности классификации, чем 57%?
Вы заметите, что в этом примере я использовал только k = 1 , подразумевая, что только один ближайший сосед учитывается при классификации каждого изображения.Как бы изменились результаты, если бы я использовал k = 3 или k = 5 ?
А как насчет выбора метрики расстояния — было бы лучше выбрать расстояние между кварталами Манхэттен / Сити?
Как насчет одновременного изменения и значения k и метрики расстояния ?
Улучшится ли точность классификации? Становиться хуже? Оставайся таким же?
Дело в том, что почти все алгоритмы машинного обучения требуют небольшой настройки для получения оптимальных результатов.Чтобы определить оптимальный набор значений для этих переменных модели, мы применяем процесс под названием Настройка гиперпараметров , который является темой сообщения в блоге на следующей неделе.
Сводка
В этой записи блога мы рассмотрели основы классификации изображений с использованием алгоритма k-NN. Затем мы применили классификатор k-NN к набору данных Kaggle Dogs vs. Cats, чтобы определить, содержит ли данное изображение собаку или кошку.
Используя только необработанные значения интенсивности пикселей входных изображений, мы получили 54.42% точность. А с помощью цветных гистограмм мы достигли немного лучшей точности 57,58%. Поскольку оба этих результата составляют> 50% (мы должны ожидать получения точности 50% просто путем случайного предположения), мы можем удостовериться, что в необработанных гистограммах пикселей / цветов существует базовый шаблон, который можно использовать для различения собак и кошек. (хотя точность 57% — это довольно плохо).
Возникает вопрос: «Можно ли получить точность классификации> 57%, используя k-NN? Если да, то как? »
Ответ: Настройка гиперпараметров — это именно то, о чем мы расскажем в блоге на следующей неделе.
Не забудьте подписаться на информационный бюллетень PyImageSearch, используя форму ниже, чтобы получать уведомления, когда следующая запись в блоге будет опубликована!

Загрузите исходный код и БЕСПЛАТНОЕ 17-страничное руководство по ресурсам
Введите свой адрес электронной почты ниже, чтобы получить .zip-код кода и БЕСПЛАТНОЕ 17-страничное руководство по компьютерному зрению, OpenCV и глубокому обучению . Внутри вы найдете мои тщательно отобранные учебники, книги, курсы и библиотеки, которые помогут вам освоить CV и DL!
,Сравнение классификаторов— документация scikit-learn 0.23.2
Примечание
Щелкните здесь, чтобы загрузить полный пример кода или запустить этот пример в своем браузере через Binder
Сравнение нескольких классификаторов в scikit-learn на синтетических наборах данных. Смысл этого примера — проиллюстрировать природу границ принятия решений. различных классификаторов. К этому следует отнестись с недоверием, поскольку интуиция подсказывает эти примеры не обязательно переносятся на реальные наборы данных.
В частности, в многомерных пространствах данные могут быть более легко разделены линейно и простота классификаторов, таких как наивные байесовские и линейные SVM может привести к лучшему обобщению, чем это достигается другими классификаторами.
На графиках сплошным цветом показаны тренировочные точки и тестовые точки. полупрозрачными. В правом нижнем углу показана точность классификации теста. устанавливать.
печать (__ doc__)
# Источник кода: Gaël Varoquaux
# Андреас Мюллер
# Изменено для документации Жаком Гроблером
# Лицензия: пункт 3 BSD
импортировать numpy как np
импортировать matplotlib.pyplot как plt
из matplotlib.colors импортировать ListedColormap
из sklearn.model_selection import train_test_split
из sklearn.процесс обработки импорта StandardScaler
из sklearn.datasets импортировать make_moons, make_circles, make_classification
из sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
из sklearn.svm импортировать SVC
из sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels импортировать RBF
из sklearn.tree import DecisionTreeClassifier
из склеарна.импорт ансамбля RandomForestClassifier, AdaBoostClassifier
из sklearn.naive_bayes импортировать GaussianNB
из sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
h = .02 # размер шага в сетке
names = ["Ближайшие соседи", "Линейная SVM", "RBF SVM", "Гауссовский процесс",
«Дерево решений», «Случайный лес», «Нейронная сеть», «AdaBoost»,
"Наивный Байес", "QDA"]
classifiers = [
KNeighborsClassifier (3),
SVC (ядро = "linear", C = 0,025),
SVC (гамма = 2, C = .