
Как выглядит выписка из ЕГРЮЛ – фото и образец документа
Как выглядит выписка из ЕГРЮЛ интересует многих людей, которые впервые сталкиваются с данным документом. Какие данные включает в себя выписка? Каким нормативным актом утверждена ее форма? Какой государственный орган уполномочен выдавать выписки? Как выглядит документ? Ответы на эти вопросы читатель узнает, прочитав статью.
СОДЕРЖАНИЕ СТАТЬИ:
Форма выписки из ЕГРЮЛ, содержание документа, образец
Выписка из реестра отражает актуальные данные обо всех зарегистрированных на территории России организациях. Получить ее можно, обратившись в налоговую (ФМС), либо МФЦ. Кроме того, возможно получение документа в электронном виде.
Форма выписки из реестра юридических лиц, порядок и сроки ее выдачи закреплены в Регламенте, который утвержден Приказом Минфина РФ от 15.01.2015 № 5н. Перечень информации, которая содержится в документе указан в ст. 5 ФЗ «О государственной регистрации…» от 08.08.2001 № 129-ФЗ.
- Наименование организации, ее ОГРН, организационно-правовая форма и адрес регистрации.
- Информация о размере уставного капитала.
- Данные о директоре компании.
- Сведения о наличии лицензий.
- Информация об участниках.
- Данные о банкротстве (если начата процедура).
- Информация о видах осуществляемой деятельности.
- Иные сведения.
Образец выписки из ЕГРЮЛ можно скачать по ссылке.
Как выглядит выписка из ЕГРЮЛ – фото
Выписка представляет собой официальную бумагу в формате А4, подготовленную на унифицированном бланке. Перечень информации обо всех организациях, зарегистрированных на территории РФ фиксированный. Документ в электронном виде выглядит точно также, как и бумажный вариант. Каждая выписка содержит данные только об одной организации.
Ввиду того, что документ достаточно объемный, приведем фото, содержащее часть выписки:
Документ в бумажном варианте заверяется должностным лицом налогового органа, его выдавшего, и печатью ФНС.
***
Таким образом, выписка из реестра юридических лиц составляется в отношении одной организации и отражает информацию, содержащуюся в ЕГРЮЛ об этой фирме. Данные находятся в общем доступе и доступны любому желающему.
Образец выписки из ЕГРЮЛ и ЕГРИП по Санкт-Петербургу
ВЫПИСКА
из Единого государственного реестра юридических лиц
24 09 2008 №__________ 114218_______
(дата)
Настоящая выписка содержит сведения о юридическом лице
____________________ Общество с ограниченной ответственностью «ЛОГО» .
(полное наименование юридического лица)
1067712439342
(основной государственный регистрационный номер)
включенные в Единый государственный реестр юридических лиц по месту нахождения данного юридического лица, по следующим показателям:
| N п/п |
Наименование показателя | Значение показателя |
| 1 | 2 | 3 |
Сведения об организационно-правовой форме и наименовании юридического лица
| 1 | Организационно-правовая форма | Общество с ограниченной ответственностью |
| 2 | Полное наименование юридического лица | Общество с ограниченной ответственностью «ЛОГО» |
| 3 | Сокращенное наименование юридического лица | ООО «ЛОГО» |
| 4 | Фирменное наименование юридического лица | Общество с ограниченной ответственностью «ЛОГО» |
| 5 | Наименование юридического лица на языке народов Российской Федерации | нет |
| 6 | Национальный язык | нет |
| 7 | Наименование юридического лица на иностранном языке | нет |
| 8 | Иностранный язык | нет |
| 9 | ИНН | 4834332434 |
Сведения об адресе (месте нахождения) юридического лица
| Сведения о принадлежности адреса | ||
| 10 | Вид адреса | Адрес постоянно действующего исполнительного органа |
| 11 | Наименование органа | Генеральный директор |
| Адрес (место нахождения) юридического лица | ||
| 12 | Почтовый индекс | 190022 |
| 13 | Субъект Российской Федерации | Город Санкт-Петербург |
| 14 | Нет | |
| 15 | Город | Нет |
| 16 | Населенный пункт | Нет |
| 17 | Улица (проспект, переулок и т. д.) д.) |
Проспект Невский |
| 18 | Номер дома (владение) | 3/4 |
| 19 | Корпус (строение) | нет |
| 20 | Квартира (офис) | офис 12 |
| Контактный телефон | юридического лица | |
| 21 | Код города | 812 |
| 22 | Телефон | 3110809 |
| 23 | Факс | нет |
Сведения об уставном капитале (складочном капитале, уставном фонде, паевых взносах)
юридического лица
| 2 | 3 | |
| 24 | Вид | Уставный капитал |
| 25 | Размер (в рублях) | 10000 |
Сведения о состоянии юридического лица и регистрирующем органе, в котором находится
регистрационное дело
26 |
Сведения о состоянии юридического лица | Действующее |
| 27 | Наименование регистрирующего органа, в котором находится регистрационное дело | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
Сведения об образовании юридического лица
| 28 | Способ образования | Государственная регистрация юридического лица при создании |
| 29 | Дата регистрации | 29. 09.2004 09.2004 |
| 30 | Основной государственный регистрационный номер (ОГРН) | 1067712439342 |
| 31 | Наименование органа, зарегистрировавшего создание юридического лица | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
Сведения о прекращении деятельности юридического лица
32 Сведений нет
Сведения о количестве учредителей (участников)юридического лица
| 33 | Количество учредителей (участников) — всего | 1 |
|
в том числе |
||
| 34 | — юридических лиц | 0 |
| 35 | — физических лиц | 1 |
Сведения об учредителях (участниках) юридического лица — российских юридических лицах
36 Сведений нет
Сведения об учредителях (участниках)юридического лица — иностранных юридических лицах
37 Сведений нет
Сведения об учредителях (участниках) юридического лица — физических лицах
| 1 | ||
| Данные учредителя (участника) — физического лица | ||
| 38 | Фамилия | Иванов |
| 39 | Имя | Сергей |
| 40 | Отчество | Владимирович |
| 41 | Размер вклада (в рублях) | 10000 |
Сведения о держателе реестра акционеров акционерного общества
42 Сведений нет
Сведения о юридических лицах, правопреемниках при реорганизации
Сведения о крестьянском (фермерском) хозяйстве, на базе имущества которых создан >производственный кооператив или хозяйственное товарищество
44 Сведений нет
Сведения о количестве физических лиц, имеющих право без доверенности действовать от имени
юридического лица
| 45 | Количество | 1 |
Сведения о физических лицах, имеющих право без доверенности действовать от имени
юридического лица
|
1 |
||
| 46 | Должность | Генеральный директор |
| 47 | Фамилия | Иванов |
| 48 | Имя | Сергей |
| 49 | Отчество | Владимирович |
Сведения о лице, имеющем право без доверенности действовать от имени юридического лица
50 Сведений нет
Сведения о филиалах юридического лица
51 Сведений нет
Сведения опредставительствах юридического лица
52 Сведений нет
Сведения о количестве видов экономической деятельности, которыми занимается юридическое
лицо
| 53 | Количество видов экономической деятельности | 2 |
Сведения о видах экономической деятельности,которыми занимается юридическое лицо
|
1 |
||
| 54 | Код по ОКВЭД | 51.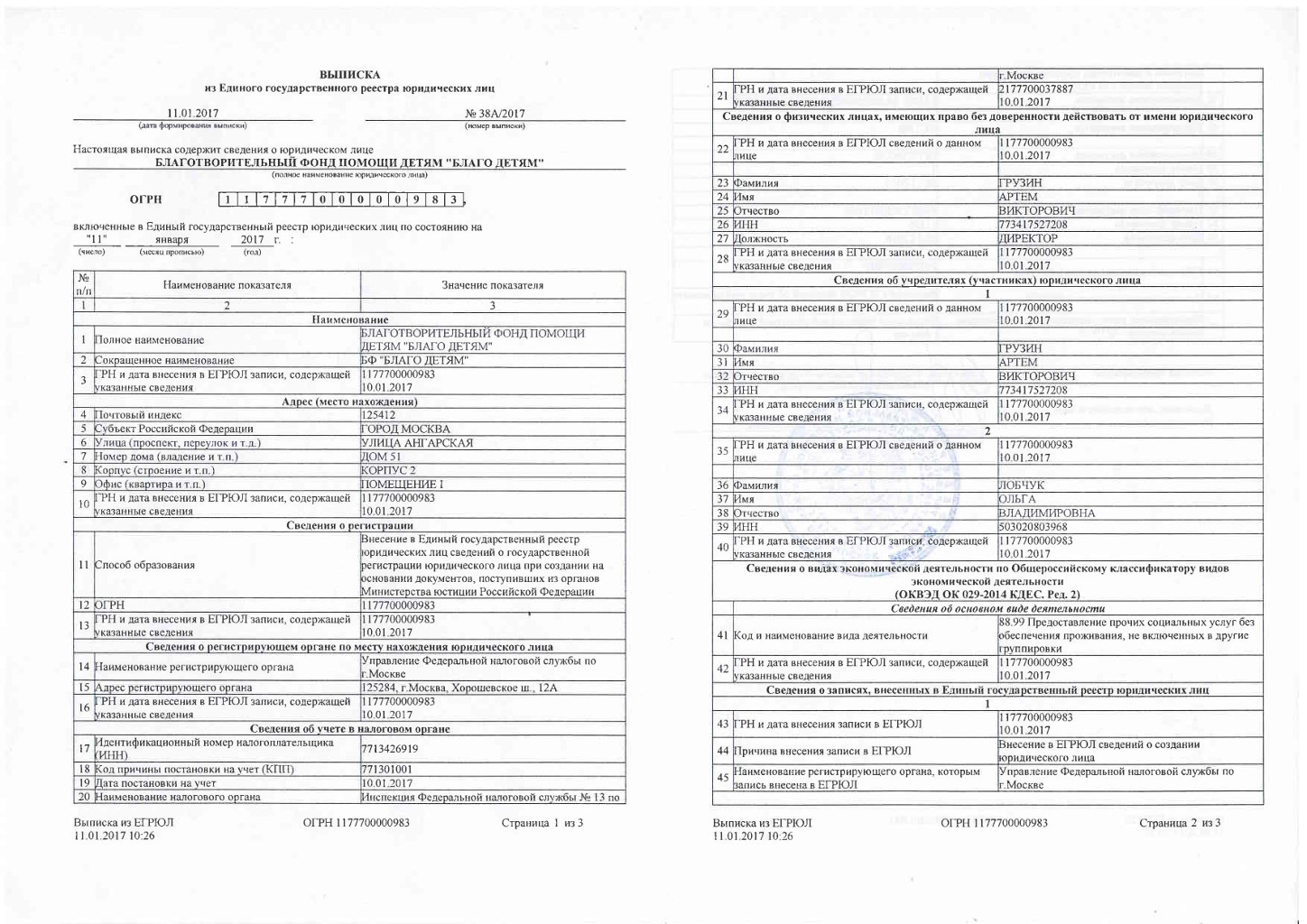 45 45 |
| 55 | Тип сведений | Основной вид деятельности |
| 56 | Наименование вида деятельности | Оптовая торговля парфюмерными и косметическими товарами |
| 2 | ||
| 57 | Код по ОКВЭД | 52.33 |
| 58 | Тип сведений | Дополнительный вид деятельности |
| 59 | Наименование вида деятельности | Розничная торговля косметическими и парфюмерными товарами |
Сведения об учете юридического лица в налоговом органе
| 1 | ||
| 60 | Идентификационный номер налогоплательщика (ИНН) | 7838300423 |
| 61 | Код причины постановки на учет (КПП) | 780001001 |
| 62 | Дата постановки на учет | 20. 09.2004 09.2004 |
| 63 | Дата снятия с учета | нет |
| Наименование налогового органа | Межрайонная инспекция Федеральной налоговой службы №7 по Санкт-Петербургу | |
Сведения о записях, внесенных в Единый государственный реестр юридических лиц на основании
представленных документов
| 1 | ||
| 65 | Государственный регистрационный номер записи | ххх7812449ххх |
| 66 | Дата внесения записи | 23.09.2004 |
| 67 | Событие, с которым связано внесение записи | Государственная регистрация юридического лица при создании |
| 68 | Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
Сведения о заявителях при данном виде регистрации
| 1 | ||
| 69 | Вид заявителя | Учредитель юридического лица — физическое лицо |
| Данные заявителя, физического лица | ||
| 70 | Фамилия | Иванов |
| 71 | Имя | Сергей |
| 72 | Отчество | Владимирович |
Сведения о выданных свидетельствах, подтверждающих внесение данной записи в Единый
государственный реестр юридических лиц
| 1 | ||
| 73 | Серия свидетельства | 458 |
| 74 | Номер свидетельства | 003405ххх |
| 75 | Дата выдачи | 23. 09.2004 09.2004 |
| 76 | Наименование регистрирующего органа, выдавшего свидетельство | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
| 77 | Статус | Действующее свидетельство |
| 2 | ||
| 78 | Государственный регистрационный номер записи | ххх7876549ххх |
| 79 | Дата внесения записи | 23.09.2004 |
| 80 | Событие, с которым связано внесение записи | Внесение в Единый государственный реестр юридических лиц сведений об учете юридического лица в налоговом органе |
| 81 | Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
| 3 | ||
| 82 | Государственный регистрационный номер записи | ххх7876549ххх |
| 83 | Дата внесения записи | 28. 09.2004 09.2004 |
| 84 | Событие, с которым связано внесение записи | Внесение в Единый государственный реестр юридических лиц сведений о регистрации юридического лица в качестве страхователя в территориальном фонде обязательного медицинского страхования |
| Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу | |
| 86 | Государственный регистрационный номер записи | ххх7876549ххх |
| 87 | Дата внесения записи | 13.10.2005 |
| 88 | Событие, с которым связано внесение записи | Внесение в Единый государственный реестр юридических лиц сведений о регистрации юридического лица в качестве страхователя в исполнительном органе Фонда социального страхования Российской Федерации |
| 89 | Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
| 90 | Государственный регистрационный номер записи | ххх7876549ххх |
| 91 | Дата внесения записи | 09. 05.2006 05.2006 |
| 92 | Событие, с которым связано внесение записи | Внесение в Единый государственный реестр юридических лиц сведений о регистрации юридического лица в качестве страхователя в территориальном органе Пенсионного фонда Российской Федерации |
| 93 | Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
| 94 | Государственный регистрационный номер записи | ххх7876549ххх |
| 95 | Дата внесения записи | 18.03.2007 |
| 96 | Событие, с которым связано внесение записи | Внесение в Единый государственный реестр юридических лиц сведений о банковских счетах юридического лица |
| 97 | Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
| 98 | Государственный регистрационный номер записи | ххх7876549ххх |
| 99 | Дата внесения записи | 18. 02.2007 02.2007 |
| 100 | Событие, с которым связано внесение записи | Внесение в Единый государственный реестр юридических лиц сведений о банковских счетах юридического лица |
| 101 | Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
| 102 | Государственный регистрационный номер записи | ххх7876549ххх |
| 103 | Дата внесения записи | 02.11.2007 |
| 104 | Событие, с которым связано внесение записи | Внесение в Единый государственный реестр юридических лиц сведений о банковских счетах юридического лица |
| 105 | Наименование регистрирующего органа, в котором внесена запись | Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу |
| Выписка сформирована по состоянию на 25 09 2008 |
Межрайонная инспекция Федеральной налоговой службы № 15 по Санкт-Петербургу _____________________________________________ полное наименование регистрирующего органа) |
| Должность ответственного лица: Начальник отдела межрайонной инспекции |
Сидорова Елена Владимировна ________________ (ФИО) |
специалисты свяжутся с вами
Налог ру выписка егрюл с эцп
С момента создания единой базы налогоплательщиков, зарегистрированных в форме юридического лица, прошло уже 14 лет и за это время все свыклись с понятием ЕГРЮЛ и выписки из него, что не одно правовое действие не совершается без этого документа1.
Что такое выписка из ЕГРЮЛ
Выписка из Единого государственного реестра юридических лиц (ЕГРЮЛ) — это официальный документ, который можно получить в налоговом органе в отношении любой организации, которая прошла регистрацию в установленном законом порядке.
В базе можно найти историю деятельности не только функционирующих предприятий, но и тех, что уже давно ликвидированы или находятся в завершающей стадии банкротства.
Выписка является единственным доказательством факта существования компании в момент получения ответа на запрос и содержит все сведения о ней с момента ее создания и до настоящего времени. Сам документ представляет собой сводную таблицу, поделенную на разделы, каждый из которых несет определенные информационные данные.
Функции по ведению реестра возложены на ФНС РФ и право предоставления официальных данных так же относится к ее компетенции. Вся информационная база находится в открытом доступе, и обратиться с требованием о выдаче может любое лицо, для этого придется уплатить государственную пошлину и подать соответствующее заявление в адрес инспекции.
До 30 июня 2015 года налоговая служба выдавала выписки на бумажном носителе, подписанном должностным лицом и скрепленной официальной печатью, именно они признавались в качестве легитимного доказательства законности регистрации и деятельности юридического лица.
После указанной даты старые выписки становятся историей, судьбоносный Приказ Минфина РФ № 25н от 18.02.2015г. изменил порядок предоставления информации из ЕГРЮЛ, установив электронную форму, заверенную электронной подписью руководителя организации, придав ей силу официального документа.
Какие сведения содержит
Выписка — это, по сути, паспорт юридического лица или история его деятельности и финансового состояния. Каждый его раздел несет определенную информационную нагрузку и может дать детальное и подробное описание организации. В зависимости от давности регистрации предприятия объем сведений может быть от нескольких страниц до десятков.
Выписка выглядит следующим образом:
- наименование: сокращенное и полное, регистрационный номер и дата первой записи о создании юридического лица;
- подробный адрес с указанием офисов, занимаемых компанией по месту ее нахождения и сведения о его смене;
- данные о регистрации, дата и ОГРН;
- указание на ИФНС, которая произвела регистрационные действия;
- цифровые идентификаторы: ИНН, КПП;
- сведения о постановке на учет во внебюджетных фондах, присвоенном номере и дате события;
- размеры уставного капитала, информация об увеличении или уменьшении;
- данные руководителя организации, как бывшего, так и действующего;
- сведения об участниках, с указанием суммы долей, паев, принадлежащих им;
- виды деятельности организации по установленному российскому классификатору;
- информация о выданных лицензиях на право занятия определенными видами деятельности;
- история внесенных изменений в реестр с указанием, послужившего для этого основания;
- данные о состоянии предприятия: действующее, ликвидируемое или пребывающее на стадии банкротства.


В каком виде выдается
В зависимости от способа изготовления выписки можно подразделить на бумажную и электронную.
Получить выписку из ЕГРЮЛ по-прежнему можно в бумажном варианте, при чем многие ведомства продолжают ее считать единственно верной. Выдается таковая по запросу заинтересованного лица и для нее потребуется представить инспектору квитанцию об уплате госпошлины и заявление. На выписке должна стоять подпись должностного лица инспекции и печать.
Электронная выписка может быть скачана на сайте ФНС, по виду она не будет отличаться от обычной, но она будет носить неофициальный характер, поскольку никем не заверена. Полученные вышеуказанным способом базовые данные, могут быть использованы в информационных целях и не более. Онлайн выписка предоставляется бесплатно, и получить ее можно с любого устройства, у которого имеется доступ в Интернет.
О выдаче электронного документа, подписанного усиленной электронно-цифровой подписью (ЭЦП) нужно подать официальную заявку на сайт налогового органа. Запрашиваемый документ может быть предоставлен на информационный носитель (диск, флешка), приложенный к заявке, если она подана в обычном порядке или на электронную почту.
Запрашиваемый документ может быть предоставлен на информационный носитель (диск, флешка), приложенный к заявке, если она подана в обычном порядке или на электронную почту.
По объему содержащейся в выписке информации, она может быть расширенной или стандартной.
Обычный документ из ЕГРЮЛ будет состоять из тех разделов, что указаны выше. А расширенная, кроме всего прочего указывает на источники дохода, открытые расчетные счета в банках, контакты участников и руководителя организации, их паспортные данные.
Правовая база
Порядок предоставления сведений из единого реестра регулируется Федеральным законом о государственной регистрации юридических лиц и индивидуальных предпринимателей, который провозглашает открытость доступа к информационной базе для любых лиц.
Приказ Минфина РФ, упорядочивающий данный процесс был принят еще в 2011 году, им был детально разработан процесс получения выписок на бумажных носителях. Время не стоит на месте, ежегодно появляются новинки в сфере Интернет технологий, позволяющие совершать отдельные действия, не выходя из дома, поэтому электронные документы из ЕГРЮЛ стали актуальнее, чем стандартные, распечатанные налоговым органом.
Время не стоит на месте, ежегодно появляются новинки в сфере Интернет технологий, позволяющие совершать отдельные действия, не выходя из дома, поэтому электронные документы из ЕГРЮЛ стали актуальнее, чем стандартные, распечатанные налоговым органом.
Изменения в порядок выдачи выписок из ЕГРЮЛ были внесены Приказом № 25н Минфина России от 18 февраля 2015 года (ССЫЛКА), но вступили в силу позже, летом прошлого года. Задержка была вызвана подготовкой серверов, информационной базы, сайтов налоговой службы, позволяющих сделать процесс быстрым и безопасным.
Новый нормативный акт уравнял бумажные и электронные выписки, вел понятие абонентское обслуживание, которое дает возможность любым лицам получить доступ к базе за определенную плату и скачивать на сайте необходимые документы из единых реестров.
Теперь для участия в электронных торгах не нужно сканировать выписку и загружать на аукционную площадку, достаточно выслать электронную версию, заверенную усиленной ЭЦП руководителя организации. Новшество уже давно опробовано и пришлось по душе многим участникам гражданских правоотношений.
Новшество уже давно опробовано и пришлось по душе многим участникам гражданских правоотношений.
К сведению лиц, обращающихся за муниципальными или государственными услугами, им не нужно предоставлять выписку, сведения из информационной базы налоговые органы предоставляют официальным ведомствам в рамках системы взаимодействия в соответствии с законом, регулирующим данную сферу.
Как заказать и получить выписку из ЕГРЮЛ или ЕГРИП через интернет на сайте ФНС России
Получить электронную версию выписки из ЕГРЮЛ или ЕГРИП можно посредством трех вариантов:
- через личный кабинет налогоплательщика;
- через портал государственных услуг;
- через сайт ФНС РФ.
Попробуем это сделать совместно через официальный сайт налоговой службы, для чего нужно перейти в раздел «Сведения о государственной регистрации юридических лиц, индивидуальных предпринимателей, крестьянских (фермерских) хозяйств» по адресу https://egrul.nalog.ru/.
Далее, спускаемся ниже и находим раздел «Критерии поиска» и задаем нужную информацию. Если известны ОГРН или ИНН компании, то вводим их, в противном случае пишем наименование юридического лица. Выбираем нужный регион и вводим в окошечке число с картинки, затем нажимаем на синий указатель «Найти»
Если известны ОГРН или ИНН компании, то вводим их, в противном случае пишем наименование юридического лица. Выбираем нужный регион и вводим в окошечке число с картинки, затем нажимаем на синий указатель «Найти»
После чего к вашему обозрению откроется таблица со всеми компаниями, подходящими по описание.
В таблице выбираем из числа вариантов нужный и нажимаем на значок PDF версии документа, его можно увидеть рядом с наименованием в левом углу. При нажатии выйдет электронная форма выписки
Если заинтересованному лицу понадобится официальная версия электронной выписки с усиленной цифровой подписью должностного лица, то на той же странице, где отображена таблица, понадобится перейти по нужной ссылке «Выписку из ЕГРЮЛ/ЕГРИП о конкретном юридическом лице/индивидуальном предпринимателе в форме электронного документа, подписанного усиленной квалифицированной электронной подписью», нажав на значок «Здесь».
Откроется другой сервис, воспользовавшись которым можно получить необходимые сведения. Перед тем, как начать работать потребуется пройти авторизацию (или регистрацию) и уже после можно будет запросить электронную выписку.
Удобство и простота работы сервера привнесли в жизнь российского бизнесмена определенные преимущества. Быстрое получение выписки с необходимыми сведениями о жизни контрагента или потенциального партнера помогут сделать процесс заключения сделок безопасным.
Теперь не нужно сканировать выписки на бумажных носителях и отправлять нужному адресату и получать претензии по плохому качеству, после принятых новшеств вполне достаточно загрузить электронную версию выписки, что в свою очередь является гарантией того, что предприятие реально существует и продолжает работать, а не ликвидировано или признано банкротом.
Источник
О предстоящем банкротстве контрагента можно узнать из ЕГРЮЛ
ФНС предупредила налогоплательщиков, что расширился список сведений, отражаемых в Едином государственном реестре юридических лиц (ЕГРЮЛ).
Как отмечается в сообщении ФНС от 20.12.2019, теперь в ЕГРЮЛ указывается информация о том, что в отношении организации возбуждено дело о банкротстве. Также в реестре отражаются сведения о введении наблюдения, финансового оздоровления, внешнего управления, о дате начала соответствующей процедуры, прекращении производства по делу о банкротстве, сведения об утвержденном внешнем управляющем.
Все указанные сведения автоматически вносятся в ЕГРЮЛ на основании информации, представленной в ФНС РФ в электронной форме оператором Единого федерального реестра сведений о банкротстве.
Ранее в ЕГРЮЛ вносились только данные об открытии конкурсного производства и назначенном конкурсном управляющем.
БУХПРОСВЕТ
Предоставление налоговиками сведений из ЕГРЮЛ и ЕГРИП осуществляется по запросу любого заинтересованного лица. Сведения об организации или физлице из ЕГРЮЛ/ЕГРИП предоставляются в виде выписки из госреестра (в электронной форме или на бумаге), либо в форме справки об отсутствии запрашиваемой информации в ЕГРЮЛ/ЕГРИП.
Выписку из ЕГРЮЛ можно запросить на официальном сайте ФНС России в разделе «Сведения о государственной регистрации юридических лиц, индивидуальных предпринимателей…». Для получения выписки об организации в разделе необходимо выбрать опцию «Юридическое лицо» и ввести ОГРН или ИНН этого юрлица либо указать его наименование. Для получения сведений об ИП необходимо указать его фамилию, имя и отчество, либо ОГРНИП, либо ИНН.
Сведения из реестра на бумажном носителе предоставляются заявителю в срок не более 5 дней с момента направления в ИФНС соответствующего запроса. Если заявитель дает в налоговую инспекцию запрос о срочном предоставлении выписки из госррестра, такая выписка предоставляется ему не позднее одного рабочего дня.
Извлечь процесс преобразования нагрузки в системе банковской отчетности
https://doi.org/10.1016/j.mex.2021.101260Получить права и контентАннотация
Банки должны поддерживать, рассчитывать и контролировать ликвидность, используя коэффициент покрытия ликвидности (LCR) показатель. В Индонезии они отчитывались ежедневно, ежемесячно или ежеквартально онлайн с помощью бумажного шаблона, подготовленного Управлением финансовых услуг (OJK). Эта отчетность должна быть точной и своевременной, в противном случае могут быть предусмотрены штрафные санкции. Для банков, которые все еще обрабатывают LCR в полуавтоматическом режиме, эта система отчетности является препятствием, с которым они продолжают сталкиваться и преодолевать.В этой статье обсуждается метод процесса автоматизации, разработанный с использованием концепции Extract Transform Load (ETL) с водопадной моделью разработки программного обеспечения, так что ежедневные отчеты создаются автоматически. В этой статье предложена методология прогнозирования проблем при интеграции банковского дела с регулирующими органами путем применения одной из структур Базель III, в первую очередь на основе тематических исследований Индонезии. Результат исследования — метод для процесса отчета LCR через ETL. Предложенный в этом исследовании метод ETL оказался успешным при обработке LCR в банковской сфере.Этот метод является решением и рекомендацией для банков при составлении отчетов на основе Базеля III для завершения отчетности LCR с помощью метода ETL.
- •
o Ведение, расчет и мониторинг ликвидности с помощью индикатора коэффициента покрытия ликвидности (LCR) в банковском деле.
- •
o Метод автоматизации, разработанный с использованием концепции извлечения нагрузки преобразования (ETL).
- •
o Рекомендация банкам заполнять отчеты LCR с помощью метода ETL).
Название метода
Процесс автоматизации извлечения нагрузки преобразования (ETL)
Ключевые слова
Коэффициент покрытия ликвидности
Загрузка преобразования извлечения
Базовый банкинг
Хранилище данных
Система банковской отчетности
Basel III
Basel III
Рекомендуемые статьиЦитирующие статьи (0)
© 2021 Авторы. Опубликовано Elsevier B.V.
Рекомендуемые статьи
Цитирующие статьи
Как сделать банковскую выверку
Шаги выверки банковских счетов
Банковская сверка происходит, когда вы сравниваете свои записи о продажах и расходах с записями вашего банка.Именно так вы проверяете бухгалтерские номера своей компании.
- Получить банковскую выписку
Вам нужен список операций из банка. Вы можете получить это из выписки, в онлайн-банке или попросив банк отправить данные прямо в вашу бухгалтерскую программу. Если у вас текущий счет и счет кредитной карты, вам понадобятся обе выписки. - Получите бизнес-записи
Откройте книгу доходов и расходов. Это может быть в бортовом журнале, электронной таблице или в программном пакете бухгалтерского учета.Некоторое бухгалтерское программное обеспечение будет получать счета и квитанции с помощью инструментов сбора данных и извлекать данные автоматически. - Найдите свою отправную точку
Найдите последний раз, когда баланс вашей бухгалтерской книги был таким же, как баланс вашего банковского счета. Начните примирение оттуда. - Выполнение банковских вкладов
Убедитесь, что каждый депозит отображается как доход на ваших счетах. Если чего-то не хватает, введите это. Вам нужно будет выяснить, была ли это продажа, проценты, возврат или что-то еще. - Проверьте доход в своих книгах
Каждая запись должна соответствовать сумме депозита в вашей банковской выписке. Если чего-то не хватает, узнайте, почему. Например, платеж клиента может быть отклонен. - Выполнение снятия средств с банка
Все снятия средств с банка должны регистрироваться в ваших книгах. Сюда входят такие вещи, как банковские сборы, которые вы, возможно, еще не учли. - Проверьте расходы в своих книгах.
Каждая запись должна соответствовать снятию средств в вашей банковской выписке.Если нет, узнайте, почему. Возможно, один из ваших платежей еще не прошел, или вы заплатили наличными или с другого счета. - Конечный баланс
После того, как вы проверили все депозиты и снятие средств, баланс вашего коммерческого банка должен совпадать с итогами на ваших корпоративных счетах. Это будет отправной точкой для вашего следующего примирения.
Как сделать банковскую выверку простым способом
Банковская выверка может работать. Переключение между документами и сравнение чисел — занятие не для всех.Если вы не можете уделить время или терпеть однообразие, есть альтернатива. Программное обеспечение значительно ускорит процесс.
Как использовать программное обеспечение для выверки банковских счетов
Большинство банков могут отправлять данные о транзакциях напрямую в бухгалтерское программное обеспечение, такое как Xero, через безопасное онлайн-соединение. Когда вы будете готовы выполнить сверку, программное обеспечение поочередно запрашивает каждую банковскую транзакцию и либо:
предлагает совпадение с соответствующей записью в ваших учетных записях, или
спрашивает, для чего была сделана транзакция, и вводит информацию в ваши учетные записи.
С правильным программным обеспечением вы можете проводить выверку банковских счетов на своем телефоне.
Проблемы с выверкой банковских счетов
Независимо от того, как вы проводите выверку банковских счетов, время от времени вам будут попадаться тайные транзакции. В одном наборе записей будут указаны суммы, а в другом — нет. Не позволяйте этому вас паниковать. Вот почему вы делаете банковские реквизиты, и часто этому есть простое объяснение.
Деловые книги показывают что-то, чего нет в вашей банковской выписке?
Если транзакция не отображается в вашей банковской выписке, это, скорее всего, связано с тем, что вы получили доход, который не поступил в банк, или вы заплатили за что-то с другого счета или наличными. Доберитесь до сути и сделайте необходимые записи.
В банковской выписке указано что-то, чего нет в ваших деловых книгах?
Если транзакция не отображается в ваших бухгалтерских книгах, это может быть связано с ошибкой нажатия клавиши при вводе транзакции.Или это может быть транзакция, которую вы забыли ввести. Внесите необходимые исправления или обновления.
Устранение проблем с выверкой банковских счетов
Выявление несовпадений может занять много времени. Чтобы попасть туда, вам нужно будет просмотреть счета-фактуры, квитанции, электронные письма и записи в дневнике. Выполняя банковскую выверку еженедельно — или даже ежедневно — вы можете избежать этих утомительных поисков, потому что у вас будет более четкая и свежая память о проверяемых транзакциях.
Сделайте банковский счет менее тяжелым
Как бы вы ни занимались банковскими реквизитами, делайте это часто. Чем дольше вы будете бездельничать, тем больше времени потребуется, чтобы наверстать упущенное. Дело не только в том, что вам нужно выполнить больше транзакций, это займет больше времени на транзакцию, потому что вам будет труднее вспомнить детали.
Запланируйте время, чтобы делать это каждую неделю или даже каждый день. И настройте систему, которая позволяет быстро и легко получать нужные вам записи. Ознакомьтесь с программным обеспечением Xero для выверки банковских счетов.
Извлечение строк продуктов
Определение и разделение систем по линейкам продуктов.
Многие приложения созданы для обслуживания нескольких логических продуктов в одной физической системе. Часто это вызвано желанием повторного использования. «Хм, потребительские кредиты очень похожи на бизнес-кредиты» или «одежда — это продукт, поэтому шторы изготавливаются на заказ, насколько они могут отличаться?». Основная проблема, с которой мы сталкиваемся, заключается в том, что внешне продукты выглядят одинаково, но они сильно различаются в деталях.
Со временем отдельные системы, обслуживающие несколько продуктов, могут стать излишне универсальными, при этом код будет развиваться для обработки всех возможных комбинаций всех возможных продуктов. Например, для общей системы, которая предназначена для обработки n продуктов с n изменениями для каждого продукта, объем тестирования, который необходимо провести для проверки всех возможных комбинаций, равен n факториальному. Это число быстро становится большим. Это также объясняет, почему многие из приложений этого типа, с которыми столкнулись авторы, имели очень мало возможностей автоматического тестирования, вместо этого полагаясь на огромные, часто ручные комплекты регрессии.Просто невозможно протестировать так много разных кодовых путей.
Таким образом, проблема часто связана с экономикой. Трудно согласиться с тем, что разработка и поддержка системы для каждого продукта может иметь больший экономический смысл, чем разработка и поддержка единой системы. Разбивая по продуктам, мы используем тот факт, что изменения в несколько продуктов могут быть внесены одновременно, и снижаем риск, избегая комбинаторного взрыва изменений, которые могут привести к дефектам в нежелательных местах.
Конечно, это компромисс — нам не нужны отдельные заявки на красные брюки и черные брюки, но мы можем захотеть подать заявку на индивидуальную или индивидуальную подачу заявки или на страхование жилья и страхование домашних животных.
Также характерно, что разные продуктовые линейки имеют очень разные потоки создания ценности, как описано в разделе «Извлечение потоков создания ценности».
Как это работает
Определите продукты или линейки продуктов в системе . Это будет сформировать тонкий слой, который нужно построить / перенести.Посмотрите, чтобы определить все возможности, которые предоставляет существующая система, и сопоставьте их с новыми продукт. Мы склонны смотреть через разные линзы, когда определяем возможности, данные, процесс, пользователи и т. д.
Определение общих возможностей . Определите, есть ли у другого продукта линии имеют общие бизнес-возможности. Есть несколько способов приближаясь к этому, о чем мы расскажем в UnderstandingYourBusinessCapabilities. Мы, как всегда, советуем ценить использование перед повторным использованием, поэтому, если сомневаетесь, постарайтесь ограничить максимальное количество общих возможностей
Выберите, кто пойдет первым .Какие линейки продуктов вы собираетесь перемещать выкл первым? Один из подходов, который нам нравится, — это мыслить категориями риска. После понимая риск миграции для бизнеса, мы часто * вторая по риску продуктовая линейка *. Это может показаться нелогичным, и что мы должны сначала выбрать наименее рискованный вариант, но на самом деле нам нравится определять продукт, который достаточно мясистый, чтобы удерживать внимание бизнеса и вызывать им уделять приоритетное внимание финансированию, но не настолько рискованно, чтобы бизнес потерпел неудачу, если есть проблемы.
Определите целевую архитектуру программного обеспечения . Очень редко мы советуем заменить большой взрыв, что в данном случае будет означать наращивание все программное обеспечение для всех продуктов сразу. Вместо этого постарайтесь определить подходящая архитектура для тонкого среза, определенного на шаге 1.
Определите вашу стратегию технической миграции . Как мы обсуждаем в в разделе о моделях миграции технологий существует ряд различных варианты, которые могут быть развернуты в зависимости от текущих ограничений.Если это простое веб-приложение, тогда можно будет использовать ForkByUrl. В других случаях, когда подходит ForkingOnIngress, может быть лучше выбрать Шаблон MessageRouter. Имейте в виду, что переходная архитектура может быть необходимо.
Когда это использовать
У вас есть система с легко определяемыми товарными линиями, которые выгода от:
- Работаем самостоятельно. Разделение системы на отдельные продуктов означает, что команды могут быть сформированы вокруг отдельных продуктов позволяя добиться прогресса без типичных проблем, связанных с изменениями координация, включая ад слияния и длинные циклы регрессии.
- Имеют разные нефункциональные характеристики. Ты хочешь стать возможность предлагать разные SLO для каждого продукта. Например разная нагрузка требования к заданной задержке.
- Различные скорости изменения. Некоторые линейки продуктов стабильны, в то время как другие продукция находится в стадии активной разработки. Разрушение системы означает что вы не рискуете вносить изменения в стабильные продукты.
Пример страхования
В сфере страхования разные типы продуктов имеют очень разные характеристики.Например, страхование транспортных средств, как правило, имеет большой объем. но низкая маржа, тогда как страхование жилья наоборот. Это также очень конкурентный, поэтому очень важна способность быстро вносить изменения. Один страховая компания, с которой мы работали, разработала трехуровневую архитектуру, которая служил механизмом котировки для всех различных продуктов страховщика предлагается, включая линии Vehicle, Life, Home и Pet, как показано на рисунке 1.
Поймите результаты, которых вы хотите достичь
Владельцы продукта компании все больше разочаровывались в время выполнения изменений, которое длилось долго и становилось все длиннее.Они решили получить Thoughtworks, чтобы взглянуть на их архитектуру и развитие процессы, чтобы увидеть, сможем ли мы определить, почему все было так плохо. Значение карта потока для процесса разработки выявила ряд ограничений которые способствовали взрывному росту сроков выполнения заказов. Хотя каждый технический домен был отделен от других, разные бизнес-домены были плотно соединены вместе. Это означало добавление нового требования для Продукт автомобиля часто влияет на дом, жизнь и так далее.Эти изменения потребовали как тщательного обдумывания, так и обширного регрессионного тестирования, прежде чем обычно чревато развертыванием. Многопродуктовая архитектура также требовала ограничение на количество людей, которые могут безопасно работать с кодовой базой, в дальнейшем замедление прогресса.
Наконец, из-за требований к объему продуктовой линейки автомобилей и рост бизнеса, базовое хранилище данных необходимо было масштабировать часто, требуя простоя для всех других продуктов, размещенных на система.
Решите, как разбить проблему на более мелкие части
В результате страховщик решил уйти со своего n-го уровня. архитектура организована вокруг технических возможностей в сторону одного организованного по продуктовым линейкам. Продукты уже были идентифицированы: Автомобиль, Дом, Страхование жизни и домашних животных. Как только они были поняты, разные были определены возможности, в которых каждый из них нуждался, например, индивидуальные наборы вопросов, цитаты и учетная запись клиента, а также многое другое технические возможности, такие как аутентификация и авторизация.Покупатель Учетная запись была определена как ключевая общая возможность, которую линий, это хороший пример заимствования подхода к координации из Магического квадранта EA, который более подробно описан в The One True Ring.
Следующее, что нужно было сделать, — это определить, с чего начать. В порядок доходов компании, продуктовые линейки с рейтингом «Транспортное средство», «Дом», Жизнь и домашнее животное. А по количеству клиентов заказ был отменен. В результате было решено, что страхование жилья будет первым продуктом. Линия реализована отдельно.Этот сбалансированный риск для бизнеса что-то идет не так с достаточным доходом, чтобы сделать выбор важный.
Успешно доставить запчасти
На приведенном выше рисунке показана управляемая событиями архитектура, которую команда начал строить. Связь с механизмом цитирования и с Возможности управления клиентами были через события, передаваемые через RabbitMQ. шина сообщений. Эти события также были распространены на существующее предприятие. хранилище данных для целей отчетности.
Поскольку команда построила новые системы на стороне существующей, были предприняты приготовления, чтобы сократить трафик из устаревшей системы к новому. Один из недостатков перемещения всей линейки продуктов заключалась в том, что поставленный вопрос должен быть полностью реализован, прежде чем клиенты можно переключить. Из-за этого ограничения новая система стала Бета-фаза, на которой определенным клиентам была предложена возможность подписаться на используйте бета-версию. Те, кто выбрали, также имели возможность оставить отзыв о новом интерфейсе.Поскольку новая система была прогрессивно улучшены, и были добавлены последние косметические функции, было принято решение go-nogo, и клиенты постепенно перенаправлялись на новая система в течение нескольких недель. Сначала один процент, потом пять, затем десять процентов и т. д. Это позволило команде и бизнесу расти в уверенность в том, что новая система работает, как ожидалось, как со стороны функциональная и нефункциональная точки зрения. Наконец, новая система была обслуживает стопроцентный трафик по страхованию жилья.Команда тогда обратился к постоянному развитию продукта.
Измените организацию, чтобы это происходило на постоянной основе
После успеха первой миграции внимание переключилось на следующую проблема, перемещение Страхование транспортных средств с использованием того же подхода и шаблон повторялся до тех пор, пока миграция не была завершена и старая система выключено.
Между тем постепенно вся техническая организация перешла от проектного подхода к разработке к ориентированному на продукт.У этого, конечно, были проблемы с прорезыванием зубов. Владение продуктом — это навык, который необходимо развивать с течением времени, поэтому переход был постепенным. Они также применили тот же подход к традиционным ИТ-операциям и под руководством технического директора и главного архитектора перешли к подходу к разработке платформенных продуктов для инфраструктуры по запросу, а затем к данным и аналитике.
Citibank, JP Morgan and Chase и другие крупные банки тратят триллионы на проекты по ископаемому топливу
По мере того как мир приближается к климатической катастрофе, крупнейшие банки мира все еще финансируют ископаемое топливо в триллионах долларов.
Это согласно недавно опубликованному отчету группы экологических групп, включая Rainforest Action Network и Sierra Club, под названием «Ставка на климатический хаос ». В отчете установлено, что 60 крупнейших частных банков в мире профинансировали ископаемое топливо на сумму 3,8 триллиона долларов за пять лет с момента подписания Парижского климатического соглашения в 2016 году.
Хотя в 2020 году произошло глобальное падение спроса и производства из-за пандемии коронавируса, а финансирование ископаемого топлива упало на 9 процентов, сумма, потраченная на проекты по добыче ископаемого топлива в прошлом году, все еще была больше, чем в 2016 году, что означает, что мировая практика крупнейшие банки принципиально не согласны с поставленной в Париже на 2016 год целью ограничить глобальное потепление до 1.5 градусов по Цельсию.
Компании, работающие на ископаемом топливе, имеют несколько возможностей для привлечения капитала для своих проектов. Самый распространенный — обратиться в банк за ссудой; другой — продать акции или предложить часть будущей прибыли — но в любом случае им нужна помощь банка.
Это означает, что банки должны сыграть важную роль в уходе мира от грязного ископаемого топлива к менее загрязняющим формам энергии — но только если они захотят это сделать. И, судя по выводам отчета «Банки на климатический хаос», большинство из них явно не делают этого.
И хотя Америка возглавляла переговоры по Парижскому соглашению более пяти лет назад, в отчете было обнаружено, что все четыре худших банка в мире по финансированию ископаемого топлива базировались в Соединенных Штатах.
JPMorgan Chase был худшим «банком ископаемых» в мире, вложив 51,3 миллиарда долларов в финансирование ископаемого топлива только в прошлом году и 317 миллиардов долларов с 2016 по 2020 год.
Это на 33 процента больше, чем у Ситибанка, занимающего второе место в мире, который потратил 48,4 миллиарда долларов в прошлом году и в общей сложности 237 миллиардов долларов с 2016 года.Wells Fargo занял третье место с 26 миллиардами долларов в 2020 году, хотя в отчете отмечается, что финансирование банка на ископаемое топливо в 2020 году фактически упало на 42 процента. Bank of America занял четвертое место, потратив почти 200 миллиардов долларов за последние пять лет.
Если вы добавите Morgan Stanley на 12-е место в мире и Goodman Sachs на 15-е место, «это почти треть банковского финансирования ископаемого топлива», поступающего из Соединенных Штатов, Джейсон Дистерхофт, эксперт по финансированию ископаемых ресурсов в Rainforest Action Network и один из авторов отчета сказал мне.
Поскольку банки США являются огромной частью проблемы финансирования ископаемого топлива, они должны быть огромной частью решения проблемы изменения климата. «США не могут достоверно называть себя мировым лидером в области климата, пока их банки в такой степени способствуют изменению климата, без каких-либо планов по прекращению этой деятельности», — добавил Дистерхофт.
В рамках общегосударственного подхода к борьбе с климатическим кризисом администрация Байдена планирует привлечь министерство финансов к усилиям по прекращению международного финансирования источников энергии на основе ископаемого топлива.
«Мы впервые видим, как администрация набрасывает, как выглядит повестка дня в этой сфере», — сказал Дистерхофт.
Но банкам в других странах тоже есть над чем поработать.
Французский BNP Paribas был худшим в Европейском союзе. Он потратил 41 миллиард долларов на финансирование ископаемого топлива в 2020 году — на 41 процент больше, чем в 2019 году, на . Японский MUFG был худшим в Азии и шестым худшим в целом.
Ни один южноамериканский или африканский банк не вошел в список 60 крупнейших банков мира.
Куда идут деньги?
В отчет включены несколько тематических исследований, которые показывают влияние крупных банков, финансирующих ископаемое топливо, на сообщества по всему миру, которые непропорционально сильно пострадали от климатического кризиса, которого они в значительной степени не создавали.
Citibank был назван худшим банком по «финансированию экспандеров», то есть по финансированию 100 крупнейших компаний, расширяющих использование ископаемого топлива. Одна из таких компаний — канадская энерготранспортная компания Enbridge, расширение нефтепровода которой по линии 3 встречает ожесточенное сопротивление со стороны коренных народов Миннесоты.
Китайские CNOOC Limited и французская Total — две крупнейшие в мире нефтегазовые компании — финансируют Восточноафриканский нефтепровод, по которому будет транспортироваться 216 000 баррелей сырой нефти в день из Уганды в Танзанию.
Если строительство будет завершено, он станет самым длинным обогреваемым трубопроводом в мире и выбросит в воздух более 33 миллионов тонн нагревающего планету CO2 — больше выбросов, чем в настоящее время производят обе страны вместе взятые.
И еще в одном случае BP, Shell, ConocoPhillips и Equinor поддерживают гидроразрыв в аргентинских нефтегазовых месторождениях Vaca Muerta в Патагонии.Хотя общины коренных народов выступают против этого проекта, крупные банки предоставляют миллионы в виде субсидий нефтегазовым компаниям, заинтересованным в развитии региона, что имело бы катастрофические последствия для глобального потепления.
В преддверии конференции ООН по изменению климата в этом году давление на крупнейшие банки мира теперь двоякое: прекратить финансирование компаний, расширяющих использование ископаемого топлива, и согласиться на поэтапный отказ от финансирования проектов по ископаемому топливу в соответствии с ограничением потепления до 1 .5 градусов Цельсия
Тысячелетиями песок и гравий использовался при строительстве дорог и зданий. Сегодня спрос на песок и гравий продолжает расти. Операторы горнодобывающей промышленности вместе с компетентными ресурсными агентствами должны работать над тем, чтобы добыча песка велась ответственно. Чрезмерная добыча песка и гравия в ручье вызывает деградацию рек.
Майнинг Instream снижает дно ручья, что может привести к эрозии берегов.Истощение песков в русле ручья и вдоль побережья вызывает углубление
рек и устьев, а также расширение устьев рек и прибрежных заливов.
Это также может привести к проникновению соленой воды из близлежащего моря.
Эффект от добычи усугубляется эффектом повышения уровня моря.
Любой объем песка, вывозимый из русел рек и прибрежных районов, является потерей для системы.
Чрезмерная добыча песка в русле реки представляет угрозу для мостов, берегов рек и близлежащих сооружений. Добыча песка также влияет на
прилегающая система подземных вод и использование реки местным населением.
Добыча песка в русле реки приводит к разрушению водной и прибрежной среды обитания из-за значительных изменений в морфологии русла.
Воздействия включают деградацию русла, укрупнение русла, снижение уровня грунтовых вод возле русла реки и нестабильность русла.
Эти физические воздействия вызывают деградацию прибрежной и водной биоты и могут привести к подрыву мостов и других сооружений.
Продолжение добычи также может привести к разрушению всего русла до глубины выемки.
Добыча песка вызывает дополнительный транспортный поток, что отрицательно сказывается на окружающей среде.Там, где подъездные дороги пересекают прибрежные районы, могут пострадать местные условия.
1.1 Бюджет песка
Определение баланса песка для конкретного участка реки требует топографической, гидрологической и гидравлической информации для конкретного участка.
Эта информация используется для определения количества песка, которое можно удалить с участка, не вызывая
чрезмерная эрозия или деградация либо на участке, либо поблизости, выше или ниже по течению.
Внутриканальная или околосковая добыча песка и гравия изменяет баланс наносов и может привести к в существенных изменениях гидравлики канала.Эти меры могут иметь различное воздействие на водную среду обитания в зависимости от масштабов и частота нарушения, способы добычи, гранулометрические характеристики наносов, характеристики прибрежной растительности, а также масштабы и частота гидрологических явлений после возмущения.
Временные и пространственные характеристики аллювиальных речных систем являются функцией геоморфологических пороговых значений, обратная связь, запаздывание, передача возмущений вверх или вниз по течению и геологические / физиографические меры контроля.Минимизация негативных последствий добычи песка и гравия требует детального понимание реакции канала на нарушения горных работ.
Решения о том, где добывать, сколько и как часто требуется определение эталонного состояния,
то есть минимально приемлемое или согласованное физическое и биологическое состояние канала.
Существующего понимания аллювиальных систем, как правило, недостаточно.
чтобы дать возможность предсказывать отклики каналов количественно и с уверенностью; поэтому в ссылке говорится
сложно определить.Тем не менее, общие сведения о речных процессах могут дать рекомендации по минимизации пагубных последствий добычи полезных ископаемых.
Требуются хорошо задокументированные случаи и соответствующие полевые данные
чтобы правильно оценить физические, биологические и экономические компромиссы.
1.2 Прибрежные среды обитания, флора и фауна
Добыча в потоке может иметь и другие дорогостоящие последствия, помимо непосредственных участков добычи. Многие гектары плодородных земли у ручья теряются ежегодно, а также ценные ресурсы древесины и среды обитания диких животных в прибрежных районах.Ухудшение среды обитания в ручьях приводит к снижению продуктивности рыболовства, биоразнообразие и рекреационный потенциал. Сильно деградированные каналы могут снизить эстетические и эстетические ценности земли.
Все виды нуждаются в определенных условиях среды обитания, чтобы обеспечить долгосрочное выживание. Местные виды в ручьях уникально приспособлены к условия среды обитания, существовавшие до того, как люди начали крупномасштабные изменения. Это привело к серьезным нарушениям среды обитания, в результате которых одни виды отделились от других, и вызвали общее сокращение биологических разнообразие и продуктивность.В большинстве ручьев и рек качество среды обитания во многом зависит от устойчивости русла. кровать и банки. Нестабильные русла рек негостеприимны для большинства водных видов.
Факторы, увеличивающие или уменьшающие отложение осадка
часто дестабилизируют русло и насыпи и приводят к резким изменениям русла. Например, человеческая деятельность, ускоряющая поток
эрозия берегов, такая как расчистка прибрежных лесов или разработка месторождений в ручье, приводит к тому, что берега реки становятся чистыми источниками
осадок, который часто
имеют серьезные последствия для водных видов.Антропогенная деятельность, которая искусственно понижает высоту русла ручья, вызывает нестабильность русла, которая
привести к чистому выбросу наносов в окрестностях. Нестабильные отложения упрощают и, следовательно, ухудшают среду обитания в ручьях для многих.
водные виды. Некоторые виды получают выгоду от этих эффектов.
Наиболее важные последствия добычи песка в ручье для водных сред обитания — это деградация дна и осаждение, что может
оказывают существенное негативное воздействие на водную флору и фауну. Устойчивость песчаных и гравийных потоков зависит от деликатного
баланс между речным стоком, наносами, поступающими с водораздела, и формой русла.Изменения в доставке наносов, вызванные горнодобывающей промышленностью
и форма канала нарушает процессы развития канала и среды обитания. Кроме того, движение нестабильных субстратов приводит к
осаждение местообитаний. Дальность воздействия зависит от интенсивности добычи,
размеры частиц, потоки и морфология каналов.
Полное удаление растительности и разрушение почвенного профиля разрушает среду обитания как над, так и под землей.
как в водной экосистеме, что приводит к сокращению популяций фауны.
Расширение русла вызывает обмеление русла, создавая плетеный поток или подземный межгравийный поток в зонах перекатов, препятствуя перемещению рыб между бассейнами. Канал достигает становятся более мелкими по мере того, как глубокие бассейны заполняются гравием и другими отложениями, уменьшая сложность среды обитания, структуру речных бассейнов, и количество крупных хищных рыб.
1.3 Устойчивость конструкций
Добыча песка и гравия в руслах рек может нанести ущерб государственной и частной собственности.Разрез канала, вызванный добычей гравия, может подорвать опоры моста
и обнажить заглубленные трубопроводы и другую инфраструктуру.
Несколько исследований задокументировали деградацию пласта, вызванную двумя основными формами добычи в русле реки: (1) выемка карьера и (2) снятие бруса. Разрушение ложа, также известное как разрез канала, происходит в результате двух основных процессов: (1) срезание головы и (2) «голодная» вода. В рубке головы выемка карьера в активном русле понижает русло ручья, создавая зазубрину, которая локально делает канал крутым наклон и увеличивает энергию потока.Во время высоких потоков точка выемки становится местом эрозии пласта, которая постепенно перемещается вверх по потоку (рис. 1).
Автоматическое извлечение текстовых и структурированных данных из документов с помощью Amazon Textract
8 сентября 2021 г. : Amazon Elasticsearch Service был переименован в Amazon OpenSearch Service. Смотрите подробности.
2 декабря 2021 г .: В этот пост добавлены последние варианты использования и возможности Amazon Textract.
Документы — это основной инструмент для ведения учета, общения, сотрудничества и транзакций во многих отраслях, включая финансовую, медицинскую, юридическую и недвижимость. Миллионы заявок на ипотеку и сотни миллионов налоговых форм W2, обрабатываемых ежегодно, — лишь несколько примеров таких документов. Большая часть информации заблокирована в неструктурированных документах. Обычно требуются трудоемкие и сложные процессы для обеспечения поиска и обнаружения, автоматизации бизнес-процессов и контроля соответствия для этих документов.
В этом посте мы покажем, как можно использовать Amazon Textract для автоматического извлечения текста и данных из отсканированных документов без использования машинного обучения (ML). В то время как AWS заботится о создании, обучении и развертывании расширенных моделей машинного обучения в высокодоступной и масштабируемой среде, вы можете воспользоваться преимуществами этих моделей с помощью простых в использовании действий API. В этом посте мы рассмотрим следующие варианты использования:
- Обнаружение текста из документов
- Формы и столы для извлечения и обработки
- Выписка из документов, удостоверяющих личность
- Извлечение информации из счетов-фактур и квитанций
- Многоколоночное обнаружение и порядок считывания
- Обработка естественного языка и классификация документов
- Обработка естественного языка медицинских документов
- Перевод документов
- Поиск и открытие
- Контроль соответствия с редактированием документа
- Обработка PDF и многостраничных TIFF документов
Обзор Amazon Textract
Прежде чем мы приступим к рассмотрению вариантов использования, давайте рассмотрим и представим некоторые из основных функций.Amazon Textract выходит за рамки простого оптического распознавания символов (OCR) и позволяет также определять содержимое полей в формах, информацию, хранящуюся в таблицах, рукописный текст и флажки. Это позволяет использовать Amazon Textract для мгновенного чтения практически любого типа документа и точного извлечения текста и данных без необходимости ручного труда или специального кода.
На следующих изображениях показан пример документа с использованием Amazon Textract в Консоли управления AWS на вкладке вывода Forms .
Чтобы быстро загрузить файл .zip, содержащий выходные данные, выберите Загрузить результаты . Вы можете выбрать различные форматы, включая необработанные файлы JSON, текст и CSV для форм и таблиц.
Помимо обнаруженного контента, Amazon Textract предоставляет дополнительную информацию, такую как оценки достоверности и ограниченные поля для обнаруженных элементов. Это дает вам контроль над тем, как вы потребляете извлеченный контент, и интегрируете его в различные бизнес-приложения.
Amazon Textract предоставляет как синхронные, так и асинхронные действия API для извлечения текста документа и анализа текстовых данных документа. Синхронные API-интерфейсы могут использоваться для одностраничных документов и вариантов использования с малой задержкой, таких как захват с мобильных устройств. Асинхронные API-интерфейсы можно использовать для многостраничных документов, таких как документы PDF или TIFF с тысячами страниц. Для получения дополнительной информации см. Справочник по API Amazon Textract.
Обзор сценариев использования
Вы можете легко воспользоваться преимуществами операций Amazon Textract API с помощью AWS SDK для создания энергоэффективных приложений.Мы также используем Amazon Textract Helper, Amazon Textract Caller, Amazon Textract PrettyPrinter и Amazon Textract Response Parser для некоторых из следующих случаев использования. Эти пакеты публикуются в PyPI, чтобы еще больше ускорить разработку и интеграцию.
Обнаружение текста из документов
Начнем с простого примера того, как определять текст в документе. Мы используем следующее изображение в качестве входного документа для Amazon Textract. Образец изображения невысокого качества, но Amazon Textract по-прежнему может точно определять текст.
Самый простой способ программного извлечения информации из этого документа — установка Amazon Textract Helper:
python -m pip install amazon-textract-helper Затем мы вызываем Amazon Textract, чтобы извлечь информацию из документа и отобразить результаты, запустив инструмент командной строки:
amazon-textract --input-document "s3: // amazon-textract-public-content / blogs / amazon-textract-sample-text-amazon-dot-com.png "--pretty-print ЛИНИИ На следующем снимке экрана показан наш результат.
Инструмент командной строки использует пакеты Amazon Textract Caller, Amazon Textract PrettyPrint и Amazon Textract Overlayer для создания результатов.
Исходный ответ Amazon Textract имеет формат JSON и следующий формат:
{
«Блоки»: [
{
"Геометрия": {
"Ограничительная рамка": {
«Ширина»: 1.0,
«Верх»: 0,0,
«Влево»: 0,0,
«Высота»: 1.0
},
«Многоугольник»: [
{
«Y»: 0,0,
«X»: 0,0
},
{
«Y»: 0,0,
«X»: 1.0
},
{
«Y»: 1.0,
«X»: 1.0
},
{
«Y»: 1.0,
«X»: 0,0
}
]
},
«Отношения»: [
{
«Тип»: «РЕБЕНОК»,
«Идентификаторы»: [
"2602b0a6-20e3-4e6e-9e46-3be57fd0844b",
"82aedd57-187f-43dd-9eb1-4f312ca30042",
"52be1777-53f7-42f6-a7cf-6d09bdc15a30",
"7ca7caa6-00ef-4cda-b1aa-5571dfed1a7c"
]
}
],
"BlockType": "СТРАНИЦА",
«Id»: «8136b2dc-37c1-4300-a9da-6ed8b276ea97»
}.....
],
"DocumentMetadata": {
«Страниц»: 1
}
}
Используя Amazon Textract Response Parser, проще десериализовать ответ JSON и использовать его в вашей программе точно так же, как его используют Amazon Textract Helper и Amazon Textract PrettyPrinter. Репозиторий GitHub показывает несколько примеров.
Вытяжка и обработка форм и столов
Amazon Textract может предоставлять данные, необходимые для автоматической обработки форм и таблиц без вмешательства человека.Например, банк может написать код для чтения заявок на получение кредита в формате PDF. Информация, содержащаяся в документе, может быть использована для инициирования всех необходимых проверок предыстории и кредитоспособности для утверждения ссуды, чтобы клиенты могли получить мгновенные результаты по своей заявке, вместо того, чтобы ждать несколько дней для ручной проверки и проверки.
На следующем изображении показано заявление о приеме на работу с полями формы, флажками и таблицей.
В следующем примере кода извлекаются формы из заявления о приеме на работу и обрабатываются различные поля:
экспорт AWS_DEFAULT_REGION = us-east-2; amazon-textract --input-document "s3: // amazon-textract-public-content / blogs / employeeapp20210510.png "--печать ФОРМЫ ТАБЛИЦЫ --функции ФОРМЫ ТАБЛИЦЫ Предыдущие команды производят следующий вывод для визуализации структуры информации.
Пары ключ-значение из выходных данных FORMS отображаются в виде таблицы с заголовками Key и Value для упрощения обработки.
Например, изменение формата вывода путем включения параметра —pretty-print-table-format = csv выводит данные в формате CSV (см. amazon-textract —help для получения списка других форматов):
экспорт AWS_DEFAULT_REGION = us-east-2; amazon-textract --input-document "s3: // amazon-textract-public-content / blogs / employeeapp20210510.png "--pretty-print ФОРМЫ ТАБЛИЦЫ --features ФОРМЫ ТАБЛИЦЫ --pretty-print-table-format = csv На следующем снимке экрана показан результат.
Amazon Textract может обнаруживать таблицы и их содержимое. Компания может извлечь все суммы из отчета о расходах (как на следующем снимке экрана) и применить правила, например, любые расходы, превышающие 1000 долларов, требуют дополнительной проверки.
Следующий код использует вывод CSV из инструмента командной строки и образец отчета о расходах для печати содержимого каждой ячейки вместе с предупреждающим сообщением, если какие-либо расходы превышают 1000 долларов:
импорт CSV
import sys
из таблицы импортировать табуляцию
читатель = csv.читатель (sys.stdin)
def isFloat (ввод):
пытаться:
float (ввод)
вернуть True
кроме ValueError:
вернуть ложь
all_rows = список ()
для строки в читателе:
предупреждение = ""
если len (строка)> 4:
если строка [4] и isFloat (строка [4]):
если float (row [4])> 1000.00 и row [3], а не row [3] .strip () == 'Total':
warning = "Предупреждение - значение> 1000,00 долларов США, требуется проверка."
row.append (предупреждение)
all_rows.append (строка)
print (tabulate (all_rows, tablefmt = 'github'))
Сохраните этот код как test-csv.py или скопируйте его из Amazon Simple Storage Service (Amazon S3) по адресу s3: //amazon-textract-public-content/blogs/test-csv.py . Затем используйте следующую команду:
экспорт AWS_DEFAULT_REGION = us-east-2; amazon-textract --input-document "s3: //amazon-textract-public-content/blogs/expense-report-example.png" --features ТАБЛИЦЫ --pretty-print ТАБЛИЦЫ --pretty-print-table-format csv | Python test-csv.py Получаем следующий вывод.
Напомним, что мы начали с изображения документа, названного Amazon Textract, чтобы идентифицировать и получать структуру таблицы и информацию, применили бизнес-логику к данным и запустили бизнес-процесс на основе информации.
Извлечение информации из счетов-фактур и квитанций
Счета-фактуры и квитанции сложно обрабатывать в масштабе, поскольку они не соответствуют установленным правилам оформления, но каждый отдельный клиент сталкивается с тысячами различных типов этих документов.Действие Amazon Textract AnalyzeExpense определяет стандартные поля и сведения о позициях для этих типов документов.
Поддерживаемые стандартные поля включают «Имя поставщика», «Итого», «Адрес получателя», «Дата счета / получения», «Идентификатор счета-фактуры / квитанции», «Условия платежа», «Промежуточный итог», «Срок платежа», «Налог. »,« Идентификатор налогоплательщика по счету-фактуре »,« Название позиции »,« Цена позиции »,« Количество позиции »плюс подробные сведения о позиции. Полный список можно найти в документации по анализу счетов-фактур и квитанций.
Консоль управления AWS предлагает варианты для тестирования действия AnalyzeExpense с помощью параметров « Выбрать документ », « Квитанция » (изображение ниже) или « Счет-фактура » или « Выбрать файл ».Последний позволяет загрузить документ и затем выбрать « Analyze Expense » на вкладке вывода справа. Через « Загрузить результаты » можно получить zip-файл, включающий поля отдельных позиций и поля сводки.
API AnalyzeExpense можно вызвать с помощью интерфейса командной строки AWS (AWS CLI), как показано в следующем коде. Убедитесь, что у вас установлена версия AWS CLI> = 2.2.23 (проверьте с aws --version ).
AWS_DEFAULT_REGION = us-east-2; aws textract analysis-cost --document '{"S3Object": {"Bucket": "amazon-textract-public-content", "Name": "blogs / textract-Receiver-all-foods-bryant-park.jpg" }} ' Результатом является ответ Textract JSON.
Мы также создали библиотеку парсера ответов Amazon Textract для анализа JSON, возвращаемого API AnalyzeExpense. Библиотека анализирует JSON и предоставляет конструкции для конкретных языков программирования для работы с различными частями документа.
Сначала установите зависимости.
> python3 -m pip install amazon-textract-response-parser boto3 amazon-textract-prettyprinter --upgrade Этот код Python принимает ответ JSON и распечатывает сводку и позиции в структуре таблицы:
импорт ОС
импорт boto3
из textractprettyprinter.t_pretty_print_expense import get_string, Textract_Expense_Pretty_Print, Pretty_Print_Table_Format
textract = boto3.клиент (service_name = 'textract')
пытаться:
response = textract.analyze_expense (
Документ = {
'S3Object': {
'Bucket': "amazon-textract-public-content",
"Имя": "blogs / textract-Receiver-Whole-foods-bryant-park.jpg"
}
})
pretty_printed_string = get_string (textract_json = response, output_type = [Textract_Expense_Pretty_Print.SUMMARY, Textract_Expense_Pretty_Print.LINEITEMGROUPS], table_format = Pretty_Print_Table_Format.fancy_grid)
печать (pretty_printed_string)
кроме Exception as e_raise:
печать (e_raise)
поднять e_raise
Выход из кода
Более подробную информацию и примеры действия AnalyzeExpense можно найти в сообщении блога «Объявление о специализированной поддержке для извлечения данных из счетов-фактур и квитанций с помощью Amazon Textract».
Выписка из документов, удостоверяющих личность
Analyze ID помогает автоматически извлекать информацию из документов, удостоверяющих личность, таких как водительские права и паспорта. Используя следующий пример изображения, мы можем использовать amazon-textract-caller и amazon-textract-response-parser для быстрого извлечения информации из документа.
Сначала установите зависимости.
> python3 -m pip install amazon-textract-response-parser boto3 tabulate --upgrade таблица используется только для целей визуализации в этом примере и не требуется для автоматизации.
Этот сценарий вызывает API Analyze ID и распечатывает значения в табличном формате.
импорт boto3
импортировать trp.trp2_analyzeid как t2id
# call_textract_analyzeid - это метод-оболочка, в который могут быть переданы местоположения S3, местоположение локального файла или байты документа идентификатора.
из textractcaller импортировать call_textract_analyzeid
# корзина с образцом изображения хранится в us-east-2, поэтому наш регион должен быть us-east-2
textract_client = boto3.client ('textract', region_name = 'us-east-2')
j = call_textract_analyzeid (
document_pages = [
"s3: // amazon-textract-public-content / analysisid / driverlicense.png "],
boto3_textract_client = textract_client)
# десериализация в класс Python
документ: t2id.TAnalyzeIdDocument = t2id.TAnalyzeIdDocumentSchema (). load (j)
# получить список значений в виде массива
результат = doc.get_values_as_list ()
из таблицы импортировать табуляцию
печать (табуляция ([x [1: 3] для x в результате]))
Выходными данными в этом случае являются только пары ключ и значение. Analyze ID также возвращает оценку достоверности и нормализованные значения, если они доступны.
Определение и порядок считывания нескольких столбцов
Традиционные решения OCR читают слева направо и не распознают несколько столбцов, поэтому они могут формировать неправильный порядок чтения для документов с несколькими столбцами.Помимо обнаружения текста, Amazon Textract предоставляет дополнительную информацию о геометрии, которую можно использовать для обнаружения нескольких столбцов и печати текста в порядке чтения.
Следующее изображение представляет собой документ в две колонки. Как и в предыдущем примере, изображение невысокого качества, но Amazon Textract по-прежнему работает хорошо.
Следующий пример кода обрабатывает документ с помощью Amazon Textract и использует информацию о геометрии для печати текста в порядке чтения:
импорт boto3
# Документ
s3BucketName = "amazon-textract-public-content"
documentName = "блоги / изображение в двух столбцах.jpg "
# Клиент Amazon Textract
textract = boto3.client ('текстракт')
# Позвонить в Amazon Textract
response = textract.detect_document_text (
Документ = {
'S3Object': {
'Bucket': s3BucketName,
'Имя': documentName
}
})
#print (ответ)
# Обнаружение столбцов и строк печати
columns = []
lines = []
для элемента в ответе ["Блоки"]:
если элемент ["BlockType"] == "LINE":
column_found = Ложь
для индекса, столбец в перечислении (столбцы):
bbox_left = item ["Геометрия"] ["BoundingBox"] ["Влево"]
bbox_right = item ["Геометрия"] ["BoundingBox"] ["Left"] + item ["Geometry"] ["BoundingBox"] ["Ширина"]
bbox_centre = item ["Геометрия"] ["BoundingBox"] ["Left"] + item ["Geometry"] ["BoundingBox"] ["Ширина"] / 2
column_centre = столбец ['влево'] + столбец ['вправо'] / 2
if (bbox_centre> column ['left'] и bbox_centre bbox_left и column_centre На следующем изображении показан вывод обнаруженного текста в правильном порядке чтения.
Обработка естественного языка и классификация документов
Электронные письма клиентов, билеты в службу поддержки, обзоры продуктов, социальные сети и даже рекламные копии - все это дает представление о настроениях клиентов, которое можно использовать для вашего бизнеса. Многие из таких материалов содержат изображения или отсканированные версии документов. После извлечения текста из этих документов вы можете использовать Amazon Comprehend для определения настроений, сущностей, ключевых фраз, синтаксиса и тем.Вы также можете обучить Amazon Comprehend обнаруживать настраиваемые объекты на основе домена вашего бизнеса. Затем вы можете использовать эти идеи для классификации документов, автоматизации рабочих процессов бизнес-процессов и обеспечения соответствия требованиям.
Следующий пример кода обрабатывает первый образец изображения, который мы использовали ранее с Amazon Textract для извлечения текста, а затем использует Amazon Comprehend для обнаружения настроений и сущностей:
импорт boto3
# Документ
s3BucketName = "amazon-textract-public-content"
documentName = "блоги / простой-документ-изображение.jpg "
# Клиент Amazon Textract
textract = boto3.client ('текстракт')
# Позвонить в Amazon Textract
response = textract.detect_document_text (
Документ = {
'S3Object': {
'Bucket': s3BucketName,
'Имя': documentName
}
})
#print (ответ)
# Печатать текст
print ("\ nТекст \ n ========")
текст = ""
для элемента в ответе ["Блоки"]:
если элемент ["BlockType"] == "LINE":
print ('\ 033 [94m' + item ["Text"] + '\ 033 [0m')
текст = текст + "" + элемент ["Текст"]
# Клиент Amazon Comprehend
понять = boto3.клиент ('понять')
# Обнаружение настроения
sentiment = comprehend.detect_sentiment (LanguageCode = "en", Text = текст)
print ("\ nSentiment \ n ======== \ n {}". format (sentiment.get ('Sentiment')))
# Обнаружение сущностей
entity = comprehend.detect_entities (LanguageCode = "en", Text = text)
print ("\ nEntities \ n ========")
для сущности в сущностях ["Сущности"]:
print ("{} \ t => \ t {}". format (entity ["Type"], entity ["Text"]))
На следующем изображении показан выходной текст вместе с анализом текста из Amazon Comprehend.Он нашел это мнение нейтральным и определил «Amazon» как организацию, «Сиэтл, Вашингтон» как местоположение и «5 июля 1994 года» как дату, а также другие организации.
Обработка естественного языка медицинских документов
Важным способом улучшить уход за пациентами и ускорить клинические исследования является понимание и анализ идей и взаимосвязей, которые «уловлены» в медицинских текстах свободной формы. Это могут быть записи о госпитализации и история болезни пациента.
В этом примере мы используем следующий документ для извлечения текста с помощью Amazon Textract. Затем вы используете Amazon Comprehend Medical для извлечения медицинских данных, таких как состояние здоровья, лекарства, дозировка, сила и защищенная медицинская информация (PHI).
Следующий пример кода обнаруживает различные медицинские объекты:
импорт boto3
# Документ
s3BucketName = "amazon-textract-public-content"
documentName = "блоги / медицинские заметки.png "
# Клиент Amazon Textract
textract = boto3.client ('текстракт')
# Позвонить в Amazon Textract
response = textract.detect_document_text (
Документ = {
'S3Object': {
'Bucket': s3BucketName,
'Имя': documentName
}
})
#print (ответ)
# Печатать текст
print ("\ nТекст \ n ========")
текст = ""
для элемента в ответе ["Блоки"]:
если элемент ["BlockType"] == "LINE":
print ('\ 033 [94m' + item ["Text"] + '\ 033 [0m')
текст = текст + "" + элемент ["Текст"]
# Клиент Amazon Comprehend
понять = boto3.клиент ('понятьмедикал')
# Обнаруживать медицинские объекты
entity = comprehend.detect_entities (Текст = текст)
print ("\ nСредние объекты \ n ========")
для сущности в сущностях ["Сущности"]:
print ("- {}". format (entity ["Text"]))
print ("Тип: {}". формат (entity ["Тип"]))
print ("Категория: {}". format (entity ["Категория"]))
if (entity ["Характеристики"]):
print ("Черты характера:")
для признака в сущности ["Черты"]:
print ("- {}". format (trait ["Name"]))
печать ("\ п")
На следующем изображении и текстовом блоке показан вывод обнаруженного текста с информацией, сгруппированной по типу.Он определил возраст «40 лет» с категорией Защищенная медицинская информация . Он также обнаружил различные заболевания, в том числе проблемы со сном, сыпь, нижние носовые раковины и эритематозную сыпь. Он распознал различные лекарства и анатомическую информацию.
Медицинские учреждения
========
- 40 лет
Тип: ВОЗРАСТ
Категория: PROTECTED_HEALTH_INFORMATION
- Проблемы со сном
Тип: DX_NAME
Категория: MEDICAL_CONDITION
Черты:
- СИМПТОМ
- Клонидин
Тип: GENERIC_NAME
Категория: ЛЕКАРСТВО
- Сыпь
Тип: DX_NAME
Категория: MEDICAL_CONDITION
Черты:
- СИМПТОМ
- лицо
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
- нога
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
- Выванс
Тип: BRAND_NAME
Категория: ЛЕКАРСТВО
- Клонидин
Тип: GENERIC_NAME
Категория: ЛЕКАРСТВО
- HEENT
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
- Заболоченные нижние носовые раковины
Тип: DX_NAME
Категория: MEDICAL_CONDITION
Черты:
- ПОДПИСАТЬ
- низший
Тип: НАПРАВЛЕНИЕ
Категория: АНАТОМИЯ
- носовые раковины
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
- поражение ротоглотки
Тип: DX_NAME
Категория: MEDICAL_CONDITION
Черты:
- ПОДПИСАТЬ
- ОТРИЦАНИЕ
- легкие
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
- чистое сердце
Тип: DX_NAME
Категория: MEDICAL_CONDITION
Черты:
- ПОДПИСАТЬ
- Сердце
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
- Регулярный ритм
Тип: DX_NAME
Категория: MEDICAL_CONDITION
Черты:
- ПОДПИСАТЬ
- Кожа
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
- эритематозная сыпь
Тип: DX_NAME
Категория: MEDICAL_CONDITION
Черты:
- ПОДПИСАТЬ
- линия роста волос
Тип: SYSTEM_ORGAN_SITE
Категория: АНАТОМИЯ
Перевод документов
Многие организации локализуют контент для международных пользователей, например веб-сайты и приложения.Они должны качественно переводить большие объемы документов. Вы можете использовать Amazon Textract с Amazon Translate для извлечения текста и данных, а затем их перевода на другие языки.
В следующем примере кода показан перевод текста первого изображения на немецкий язык:
импорт boto3
# Документ
s3BucketName = "amazon-textract-public-content"
documentName = "blogs / simple-document-image.jpg"
# Клиент Amazon Textract
textract = boto3.client ('текстракт')
# Позвонить в Amazon Textract
response = textract.detect_document_text (
Документ = {
'S3Object': {
'Bucket': s3BucketName,
'Имя': documentName
}
})
#print (ответ)
# Клиент Amazon Translate
translate = boto3.client ('переводить')
Распечатать ('')
для элемента в ответе ["Блоки"]:
если элемент ["BlockType"] == "LINE":
print ('\ 033 [94m' + item ["Text"] + '\ 033 [0m')
result = translate.translate_text (Text = item ["Text"], SourceLanguageCode = "en", TargetLanguageCode = "de")
print ('\ 033 [92m' + результат.get ('TranslatedText') + '\ 033 [0m')
Распечатать ('')
На следующем изображении показан вывод обнаруженного текста, построчно переведенного на немецкий язык.
Поиск и открытие
Извлечение структурированных данных из документов и создание интеллектуального индекса с помощью Amazon OpenSearch Service позволяет быстро выполнять поиск по миллионам документов. Например, ипотечная компания может использовать Amazon Textract для обработки миллионов отсканированных кредитных заявок за считанные часы и индексации извлеченных данных в Amazon ES.Это позволит им создавать условия поиска, такие как поиск заявок на ссуду, в которых заявителем является Джон Доу, или поиск контрактов с процентной ставкой 2%.
В следующем примере кода извлекается текст из первого изображения, сохраняется в Amazon ES и выполняется поиск с помощью Kibana:
импорт boto3
из elasticsearch импорт Elasticsearch, RequestsHttpConnection
from requests_aws4auth импортировать AWS4Auth
def indexDocument (bucketName, objectName, text):
# Обновите хост с конечной точкой вашего кластера Elasticsearch
#host = "search - xxxxxxxxxxxxxx.us-east-1.es.amazonaws.com
host = "searchxxxxxxxxxxxxxxxx.us-east-1.es.amazonaws.com"
region = 'us-east-1'
если (текст):
service = 'es'
ss = boto3.Session ()
учетные данные = ss.get_credentials ()
region = ss.region_name
awsauth = AWS4Auth (credentials.access_key, credentials.secret_key, регион, служба, session_token = credentials.token)
es = Elasticsearch (
hosts = [{'хост': хост, 'порт': 443}],
http_auth = awsauth,
use_ssl = Верно,
verify_certs = True,
connection_class = RequestsHttpConnection
)
document = {
"имя": "{}".формат (имя_объекта),
"bucket": "{}". формат (bucketName),
"content": текст
}
es.index (index = "textract", doc_type = "document", id = objectName, body = document)
print ("Проиндексированный документ: {}". format (objectName))
# Документ
s3BucketName = "amazon-textract-public-content"
documentName = "blogs / simple-document-image.jpg"
# Клиент Amazon Textract
textract = boto3.client ('текстракт')
# Позвонить в Amazon Textract
response = textract.detect_document_text (
Документ = {
'S3Object': {
'Bucket': s3BucketName,
'Имя': documentName
}
})
#print (ответ)
# Распечатать обнаруженный текст
текст = ""
для элемента в ответе ["Блоки"]:
если элемент ["BlockType"] == "LINE":
print ('\ 033 [94m' + item ["Text"] + '\ 033 [0m')
текст + = элемент ["Текст"]
indexDocument (s3BucketName, documentName, текст)
# Вы можете просматривать индексные документы в Kibana Dashboard
На следующем изображении показан вывод извлеченного текста в результатах поиска Kibana.
Вы также можете создать собственный пользовательский интерфейс, воспользовавшись преимуществами API Amazon ES. Позже в этом посте вы узнаете, как извлекать формы и таблицы, а затем индексировать эти структурированные данные аналогично, чтобы включить интеллектуальный поиск.
Контроль соответствия с редактированием документов
Поскольку Amazon Textract автоматически идентифицирует типы данных и метки форм, AWS помогает защитить инфраструктуру, чтобы вы могли обеспечить соблюдение мер контроля информации.Например, страховщик может использовать Amazon Textract для подачи рабочего процесса, который автоматически редактирует личную информацию (PII) для проверки перед архивацией форм претензий. Amazon Textract распознает важные поля, требующие защиты.
В следующем примере кода извлекаются все поля формы в приложении о приеме на работу, которое использовалось ранее, и редактируются все поля адреса:
импорт boto3
из TRP импортного документа
из PIL импортировать изображение, ImageDraw
# Документ
s3BucketName = "amazon-textract-public-content"
documentName = "blogs / employeeapp20210510.png "
# Клиент Amazon Textract
textract = boto3.client ('текстракт')
# Позвонить в Amazon Textract
response = textract.analyze_document (
Документ = {
'S3Object': {
'Bucket': s3BucketName,
'Имя': documentName
}
},
FeatureTypes = ["ФОРМЫ"])
doc = Документ (ответ)
# Редактировать документ
img = Image.open (имя_документа)
ширина, высота = img.size
если (doc.pages):
page = doc.pages [0]
для поля в page.form.fields:
если (field.key и field.value и "адрес" в поле.key.text.lower ()):
#if (field.key и field.value):
print ("Редактирование => Ключ: {}, Значение: {}". формат (field.key.text, field.value.text))
x1 = field.value.geometry.boundingBox.left * ширина
y1 = field.value.geometry.boundingBox.top * height-2
x2 = x1 + (field.value.geometry.boundingBox.width * width) +5
y2 = y1 + (field.value.geometry.boundingBox.height * height) +2
draw = ImageDraw.Draw (img)
draw.rectangle ([x1, y1, x2, y2], fill = "Черный")
img.сохранить ("отредактировано - {}". формат (имя_документа))
Следующие выходные данные представляют собой отредактированную версию заявления о приеме на работу.
Обработка PDF или многостраничных документов TIFF (асинхронные операции API)
В предыдущих примерах вы использовали изображения с синхронными операциями API. Теперь посмотрим, как мы обрабатываем PDF-файлы с помощью асинхронных операций API. Одностраничные или многостраничные документы TIFF также поддерживаются в асинхронных операциях API.
С помощью инструмента командной строки amazon-textract вы можете передать PDF-файл (расположение PDF-файла должно быть на Amazon S3), а базовая реализация вызывает асинхронный API для StartDocumentTextDetection или StartDocumentAnalysis для запуска задания Amazon Textract:
amazon-textract --input-document "s3: //amazon-textract-public-content/blogs/Amazon-Textract-Pdf.pdf" --pretty-print LINES На следующем снимке экрана показан наш результат.
Когда вы используете асинхронный API из программы Python или интерпретатора Python, он выглядит следующим образом:
из textractcaller.t_call импорт call_textract
из textractprettyprinter.t_pretty_print import get_lines_string
response = call_textract (input_document = "s3: //amazon-textract-public-content/blogs/Amazon-Textract-Pdf.pdf")
печать (get_lines_string (ответ))
Получаем следующий вывод.
Сначала вызывается StartDocumentTextDetection или StartDocumentAnalysis для запуска задания Amazon Textract. Amazon Textract публикует результаты запроса Amazon Textract, включая статус выполнения, в Amazon Simple Notification Service (Amazon SNS). Затем вы можете использовать GetDocumentTextDetection или GetDocumentAnalysis, чтобы получить результаты из Amazon Textract.
Заключение
В этом посте мы показали вам, как использовать Amazon Textract для автоматического извлечения текста и данных из отсканированных документов без какого-либо опыта машинного обучения.Мы рассмотрели варианты использования в таких областях, как финансы, здравоохранение и HR, но есть много других возможностей, в которых может быть полезна возможность разблокировать текст и данные из неструктурированных документов.
Вы можете начать использовать Amazon Textract в регионах Восток США (Огайо), Восток США (Северная Вирджиния), Запад США (Северная Калифорния), Запад США (Орегон), Азиатско-Тихоокеанский регион (Мумбаи), Азиатско-Тихоокеанский регион (Сеул), Азия. Тихоокеанский регион (Сингапур), Азиатско-Тихоокеанский регион (Сидней), Канада (Центральный), ЕС (Франкфурт), ЕС (Ирландия), ЕС (Лондон), ЕС (Париж), AWS GovCloud (Восток США) и AWS GovCloud (США- Запад).
Чтобы узнать больше об Amazon Textract, прочтите об обработке одностраничных и многостраничных документов, работе с блочными объектами и примерах кода.
Об авторах
Кашиф Имран - архитектор решений в Amazon Web Services. Он работает с одними из крупнейших стратегических заказчиков AWS, предоставляя технические рекомендации и советы по проектированию. Его опыт охватывает архитектуру приложений, бессерверные приложения, контейнеры, NoSQL и машинное обучение.
Мартин Шаде - старший SA по продуктам машинного обучения в команде Amazon Textract. Он имеет более чем 20-летний опыт работы с интернет-технологиями, инженерными и архитектурными решениями и присоединился к AWS в 2014 году, сначала направив некоторых из крупнейших клиентов AWS по наиболее эффективному и масштабируемому использованию сервисов AWS, а затем сосредоточившись на AI / ML с упором на на компьютерном зрении и в настоящий момент одержим извлечением информации из документов.
«Мы наблюдаем кризис ценностей» - эксклюзивный отрывок из книги Марка Карни | Марк Карни
Несколько лет назад, когда ряд политиков, бизнесменов, ученых, профсоюзов и благотворителей собрались в Ватикане, чтобы обсудить будущее рыночной системы, Папа Франциск удивил нас, присоединившись к обеду и поделившись притчей.Он заметил, что:
Наша еда будет сопровождаться вином. Вино - это многое. Его букет, цвет и насыщенность вкуса дополняют блюдо. В нем есть алкоголь, способный оживить ум. Вино обогащает все наши чувства.
В конце застолья у нас будет граппа. Граппа - это одно: алкоголь. Граппа винно-дистиллированная.
Он продолжил:
Человечество многогранно - страстное, любопытное, рациональное, альтруистическое, творческое, корыстное. Но рынок - это одно: корысть. Рынок очищен от человечества.
И затем он бросил нам вызов:
Ваша задача - превратить граппу обратно в вино, чтобы рынок снова стал человечным. Это не теология. Это реальность. Это правда.
По моему опыту, потрясения, которые пережил мир, показывают, что жизненно важно сбалансировать существенный динамизм капитализма с нашими более широкими социальными целями.Это не отвлеченный вопрос или наивное стремление.
Более 12 лет мне выпала честь быть губернатором G7, сначала в Канаде, а затем в Великобритании. За это время я видел взлеты и падения царства золота. Я руководил глобальными реформами, чтобы исправить ошибки, вызвавшие финансовый кризис, работал над исцелением злокачественной культуры, лежащей в основе финансового капитализма, и начал решать как фундаментальные проблемы четвертой промышленной революции, так и риски для существования, связанные с изменением климата.Я почувствовал крах общественного доверия к элитам, глобализации и технологиям. И я убедился, что эти вызовы отражают общий кризис ценностей и что необходимы радикальные изменения, чтобы построить экономику, которая работает для всех.
Всякий раз, когда я мог отойти от того, что казалось ежедневным кризисным менеджментом, возникали те же более глубокие проблемы. Может ли сам акт оценки сформировать наши ценности и ограничить наш выбор? Как оценка рынков влияет на ценности нашего общества?
Марк Карни: «Мы живем в соответствии с афоризмом Оскара Уайльда - зная цену всему, но ничего не ценим - за счет неисчислимых затрат для нашего общества.Фотография: Тоби МэдденПо мере того, как мы переходим от рыночной экономики к рыночному обществу, меняются как ценности, так и ценности. Все чаще ценность чего-либо, какого-либо действия или кого-либо приравнивается к их денежной стоимости, денежной стоимости, которая определяется рынком. Логика покупки и продажи больше не применима только к материальным благам, но все больше управляет всей жизнью, от распределения здравоохранения до образования, общественной безопасности и защиты окружающей среды.
Коммодификация, выставление товара на продажу, может подорвать стоимость того, что оценивается.Как утверждает политический философ Майкл Сэндел: «Когда мы решаем, что определенные товары и услуги можно покупать и продавать, мы решаем, по крайней мере косвенно, что уместно рассматривать их как товары, как инструменты получения прибыли и использования».
Установление цены на любую человеческую деятельность подрывает определенные моральные и гражданские блага. Это моральный вопрос, как далеко мы должны зайти на взаимовыгодные обмены для повышения эффективности. Следует ли выставлять секс на продажу? Должен ли быть рынок права иметь детей? Почему бы не продать на аукционе право отказаться от военной службы?
Имеются обширные свидетельства того, что, когда рынки расширяются до человеческих отношений и гражданской практики (от воспитания детей до обучения), пребывание на рынке может изменить характер товаров и социальные практики, которыми они управляют.
Один из самых известных примеров был задокументирован Ричардом Титмусом в его сравнительном исследовании систем донорства крови в США и Великобритании, The Gift Relationship. Титмусс продемонстрировал, что в экономическом и практическом плане система добровольных пожертвований в Великобритании превосходит американскую систему оплаты пожертвований. Он добавил этический аргумент о том, что превращение крови в товар ослабило дух альтруизма и подорвало чувство долга людей сдавать кровь для поддержки других членов своего сообщества.
Эти наблюдения известны из гражданского ответа на Covid. Ни одной из добровольных групп, которые сформировались спонтанно, не заплатили за самодельные СИЗ и защитные маски, которые они создали и передали в дар. Призыв к добровольцам помочь сотрудникам NHS был встречен более чем миллионом человек в считанные дни. Ни один гражданин не получал государственных выплат, чтобы помочь пожилым соседям или бездомным в их общинах.
Это подчеркивает моральную ошибку многих традиционных экономистов, которые относятся к гражданским и социальным добродетелям как к дефицитным товарам, несмотря на наличие обширных свидетельств того, что общественный дух возрастает с их практикой.
Мой опыт работы в частном и государственном секторах согласуется с притчей Папы Франциска. Стоимость на рынке все больше определяет ценности общества. Мы живем в соответствии с афоризмом Оскара Уайльда - зная цену всему, но не ценим ничего - ценой неисчислимых затрат для нашего общества, будущих поколений и нашей планеты.
Как только мы осознаем эту динамику, мы сможем снова превратить граппу в вино и снова направить ценность рынка на службу ценностям человечества.