
инвалидация — Викисловарь
Содержание
- 1 Русский
- 1.1 Морфологические и синтаксические свойства
- 1.2 Произношение
- 1.3 Семантические свойства
- 1.3.1 Значение
- 1.3.2 Синонимы
- 1.3.3 Антонимы
- 1.3.4 Гиперонимы
- 1.3.5 Гипонимы
- 1.4 Родственные слова
- 1.5 Этимология
- 1.6 Фразеологизмы и устойчивые сочетания
- 1.7 Перевод
- 1.8 Библиография
| В Викиданных есть лексема инвалидация (L112785). |
Морфологические и синтаксические свойства[править]
| падеж | ед. ч. | мн. ч. |
|---|---|---|
| Им. | инвалида́ция | инвалида́ции |
| Р. | инвалида́ции | инвалида́ций |
| Д. | инвалида́ции | инвалида́циям |
| В. | инвалида́цию | инвалида́ции |
| Тв. | инвалида́цией инвалида́циею | инвалида́циями |
| Пр. | инвалида́ции | инвалида́циях |
ин-ва-ли-да́-ци·я
Существительное, неодушевлённое, женский род, 1-е склонение (тип склонения 7a по классификации А. А. Зализняка).
Корень: —.
Произношение[править]
Семантические свойства[править]
Значение[править]
- лишение законной силы, аннулирование ◆ Допускается и инвалидация арбитражного соглашения, заключенного в ненадлежащей форме. п.р. О.Ю. Скворцова, «Третейское разбирательство в Российской Федерации», 2010 г.
Синонимы[править]
Антонимы[править]
- валидация
Гиперонимы[править]
Гипонимы[править]
Родственные слова[править]
| Ближайшее родство | |
Этимология[править]
От ??
Фразеологизмы и устойчивые сочетания[править]
Перевод[править]
| Список переводов | |
Библиография[править]
 | Для улучшения этой статьи желательно:
|
К вопросу об инвалидации кеша / Habr
Инвалидация кеша, возможно, одна из самых запутанных вещей в программировании. Тонкость вопроса состоит в компромиссе между полнотой, избыточностью и сложностью этой процедуры. Так о чём же эта статья? Хотелось бы не привязываясь к какой-либо платформе, языку или фреймворку, подумать о том как следует реализовывать систему инвалидации. Ну а чтобы не писать обо всём и ни о чём, сконцентрируемся на кешировании результатов SQL-запросов построенных с помощью ORM, которые в наше время встречаются нередко.Полнота и избыточность
Начнём всё же с общих соображений не специфичных ни для SQL-запросов, ни для ORM. Упомянутые полноту и избыточность я определяю следующим образом. Полнота инвалидации — это её характеристика, определяющая насколько часто и в каких случаях может/будет возникать ситуация когда в кеше будут содержаться грязные данные и как долго они там будут оставаться. Избыточностью, в свою очередь, назовём то как часто кеш будет инвалидироваться без необходимости.
Рассмотрим для примера распространённый способ инвалидации по времени. С одной стороны, он практически гарантирует, что сразу после изменения данных кеш грязен. С другой стороны, время которое кеш остаётся грязным, мы можем легко ограничить уменьшив время жизни (что в свою очередь сократит процент попаданий). Т.е. при сокращении времени жизни кеша полнота инвалидации улучшается, а избыточность ухудшается. В итоге, чтобы достигнуть идеальной полноты инвалидации (никаких грязных данных) мы должны выставить таймаут в 0, или, другими словами, отключить кеш. Во многих случаях временное устаревание данных в кеше допустимо. Например, как правило, не так уж и страшно если новость в блоке последних новостей появится там на несколько минут позже или общее количество пользователей вашей социальной сети будет указано с ошибкой в пару-тройку тысяч.
Инвалидация по событию
Способ с инвалидацией по времени хорош своей простотой, однако, не всегда применим. Что ж, можно сбрасывать кеш при изменении данных. Одной из проблем при таком подходе является то, что при добавлении нового запроса, который мы кешируем приходиться добавлять код для его инвалидации в при изменении данных. Если мы используем ORM, то данные изменяются (в хорошем случае) в одном месте — при сохранении модели. Наличие одного центрального кода изменения данных облегчает задачу, однако, при большом количестве разнообразных запросов приходиться всё время дописывать туда всё новые и новые строки сброса различных кусочков кеша. Таким образом, мы получаем на свою голову избыточную связность кода. Пора её ослабить.
Автоматическая инвалидация ORM-запросов
Вспомним, что у нас есть ORM, а для него каждый запрос представляет не просто текст, а определённую структуру — модели, дерево условий и прочее. Так что, по идее, ORM может и кешировать и вешать инвалидационные обработчики прямо при кешировании по мере надобности. Чертовски привлекательное решение для ленивых ребят, вроде меня. Небольшой пример. Допустим мы выполняем запрос:
select * from post where category_id=2 and published
category_id=2 and published=true. Через некоторое время для каждой модели образуются списки инвалидаторов, каждый из которых хранит список запросов, которые должен сбрасывать:post:
category_id=2 and published=true:
select * from post where category_id=2 and published
select count(*) from post where category_id=2 and published
select * from post where category_id=2 and published limit 20
category_id=3 and published=true:
select * from post where category_id=3 and published limit 20 offset 20
category_id=3 and published=false:
select count(*) from post where category_id=3 and not published
foo:
a=1 or b=10:
or_sql
a in (2,3) and b=10:
in_sql
a>1 and b=10:
gt_sql
В реальности в инвалидаторах удобнее хранить списки ключей кеша, а не тексты запросов, тексты здесь для наглядности.
Посмотрим, что будет происходить при добавлении объекта. Мы должны пройти по всему списку инвалидаторов и стереть ключи кеша для условий, выполняющихся для добавленного объекта. Но инвалидаторов может быть много, и храниться они должны там же где сам кеш, т.е. скорее всего не в памяти процесса и загружать их все каждый раз не хотелось бы, да и последовательная проверка всех условий больно долга.
Очевидно, нужно как-то группировать и отсеивать инвалидаторы без их полной проверки. Заметим, что картина когда условия различаются только значениями. Например, инвалидаторы в модели post все имеют вид category_id=? and published=?.. Сгруппируем инвалидаторы из примера по схемам:
post:
category_id=? and published=?:
2, true:
select * from post where category_id=2 and published
select count(*) from post where category_id=2 and published
select * from post where category_id=2 and published limit 20
3, true:
select * from post where category_id=3 and published limit 20 offset 20
3, false:
select count(*) from post where category_id=3 and not published
foo:
a=? or b=?:
1, 10:
or_sql
a in ? and b=?:
(2,3), 10:
in_sql
a > ? and b=?:
1, 10:
gt_sql
Обратим внимание на условие category_id=? and published=?, зная значения полей добавляемого поста, мы можем однозначно заполнить метки «?». Если объект:
{id: 42, title: "…", content: "…", category_id: 2, published: true}
Однако, что делать с более сложными условиями? В отдельных случаях кое-что можно сделать: or разложить на два инвалидатора, in развернуть в or. В остальных случаях либо придётся всё усложнить, либо сделать инвалидацию избыточной, отбросив такие условия. Приведём то, какими будут инвалидаторы для foo после таких преобразований:
foo:
a = ?:
1: or_sql
b = ?:
10: or_sql, gt_sql
a = ? and b = ?:
2, 10: in_sql
3, 10: in_sql
Таким образом, нам нужно для каждой модели только хранить схемы (просто списки полей), по которым при надобности мы строим инвалидаторы и запрашиваем списки ключей, которые следует стереть.
Приведу пример процедуры инвалидации для foo. Пусть мы запросили из базы объект {id: 42, a: 1, b: 10} сменили значение a на 2 и записали обратно. При обновлении процедуру инвалидации следует прогонять и для старого, и для нового состояния объекта. Итак, инвалидаторы для старого состояния: a=1, b=10, a=1 and b=10, соответствующие ключи or_sql и gt_sql (последний инвалидатор отсутсвует, можно считать пустым). Для нового состояния получаем инвалидаторы a=2, b=10, a=2 and b=10, что добавляет ключ in_sql. В итоге стираются все 3 запроса.
Реализация
Я старался по-возможности абстрагироваться от языка и платформы, однако, рабочая и работающая в довольно нагруженном проекте система тоже существует. Подробнее о ней и о хитростях реализации вообще в следующей статье.
- Добавление в имена файлов информации о версии содержащихся в них данных (обычно — в виде хэша данных, находящихся в файлах).
- Установка HTTP-заголовков
Cache-Control: max-ageиExpires, управляющих временем кэширования материалов (что позволяет исключить повторную валидацию соответствующих материалов для посетителей, возвращающихся на ресурс).
Все известные мне средства для сборки проектов поддерживают добавление к именам файлов хэша их содержимого. Делается это с помощью простого конфигурационного правила (наподобие того, что показано ниже):
filename: '[name]-[contenthash].js'Столь широкая поддержка этой технологии привела к тому, что подобная практика стала чрезвычайно распространённой.
Эксперты в сфере производительности веб-проектов, кроме того, рекомендуют пользоваться методиками разделения кода. Эти методики позволяют разбивать JavaScript-код на отдельные бандлы. Такие бандлы могут быть загружены браузером параллельно, или даже лишь тогда, когда в них возникнет необходимость, по запросу браузера.
Одним из многих преимуществ разделения кода, в частности, имеющих отношение к передовым методикам кэширования, называют то, что изменения, внесённые в отдельный файл с исходным кодом, не приводят к инвалидации кэша всего бандла. Другими словами, если для npm-пакета, созданного разработчиком «X», вышло обновление безопасности, и при этом содержимое node_modules разбито на фрагменты по разработчикам, то изменить придётся только фрагмент, содержащий пакеты, созданные «X».
Проблема тут заключается в том, что если всё это скомбинировать, то подобное редко приводит к повышению эффективности долговременного кэширования данных.
На практике изменения одного из файлов исходного кода почти всегда приводят к инвалидации более чем одного выходного файла системы сборки пакетов. И это происходит именно из-за того, что к именам файлов были добавлены хэши, отражающие версии содержимого этих файлов.
Проблема, касающаяся версионирования имён файлов
Представьте, что вы создали и развернули веб-сайт. Вы воспользовались разделением кода, в результате большая часть JavaScript-кода вашего сайта загружается по запросу.
На следующей диаграмме зависимостей можно видеть точку входа кодовой базы — корневой фрагмент main, а также — три фрагмента-зависимости, загружаемых асинхронно — dep1, dep2 и dep3. Есть здесь и фрагмент vendor, содержащий все зависимости сайта из node_modules. Все имена файлов, в соответствии с рекомендациями по кэшированию, включают в себя хэши содержимого этих файлов.
Типичное дерево зависимостей JavaScript-модуля
Так как фрагменты dep2 и dep3 импортируют модули из фрагмента vendor, то в верхней части их кода, сгенерированного сборщиком проекта, мы, скорее всего, обнаружим команды импорта, выглядящие примерно так:
import {...} from '/vendor-5e6f.mjs';Теперь подумаем о том, что произойдёт, если изменится содержимое фрагмента
vendor.Если это произойдёт, то хэш в имени соответствующего файла тоже изменится. А так как ссылка на имя этого файла имеется в командах импорта фрагментов dep2 и dep3, тогда нужно будет, чтобы изменились и эти команды импорта:
-import {...} from '/vendor-5e6f.mjs';
+import {...} from '/vendor-d4a1.mjs';Однако так как эти команды импорта являются частью содержимого фрагментов
dep2 и dep3, то их изменение означает, что изменится и хэш содержимого файлов dep2 и dep3. А значит — и имена этих файлов тоже изменятся.Но на этом всё не заканчивается. Так как фрагмент main импортирует фрагменты dep2 и dep3, а имена их файлов изменились, команды импорта в main тоже поменяются:
-import {...} from '/dep2-3c4d.mjs';
+import {...} from '/dep2-2be5.mjs';
-import {...} from '/dep3-d4e5.mjs';
+import {...} from '/dep3-3c6f.mjs';И наконец, так как содержимое файла
main изменилось, имя этого файла тоже должно будет измениться.Вот как теперь будет выглядеть диаграмма зависимостей.
Модули в дереве зависимостей, на которые повлияло единственное изменение в коде одного из листовых узлов дерева
Из этого примера видно, как небольшое изменение кода, сделанное всего лишь в одном файле, привело к инвалидации кэша 80% фрагментов бандла.
Хотя и правда то, что не все изменения приводят к столь печальным последствиям (например, инвалидация кэша листового узла приводит к инвалидации кэша всех узлов вплоть до корневого, но инвалидация кэша корневого узла не вызывает каскадной инвалидации, доходящей до листовых улов), в идеальном мире нам не приходилось бы сталкиваться с любыми ненужными инвалидациями кэша.
Это приводит нас к следующему вопросу: «Можно ли получить преимущества, даваемые иммутабельными ресурсами и долговременным кэшированием, и при этом не страдать от каскадных инвалидаций кэша?».
Подходы к решению проблемы
Проблема, касающаяся хэшей содержимого файлов, находящихся в именах файлов, с технической точки зрения, заключается не в том, что хэши находятся в именах. Она заключается в том, что эти хэши появляются и внутри других файлов. В результате кэш этих файлов инвалидируется при изменении хэшей в именах файлов, от которых они зависят.
Решение этой проблемы заключается в том, чтобы, говоря языком вышеприведённого примера, сделать возможным импорт фрагмента vendor фрагментами dep2 и dep3 без указания информации о версии файла фрагмента vendor. При этом нужно гарантировать, чтобы загруженная версия vendor была бы правильной, принимая во внимание текущие версии dep2 и dep3.
Как оказалось, существует несколько способов достижения этой цели:
- Карты импорта.
- Сервис-воркеры.
- Собственные скрипты для загрузки ресурсов.
Рассмотрим эти механизмы.
Подход №1: карты импорта
Карты импорта — это простейшее решение проблемы каскадной инвалидации кэшей. Кроме того, этот механизм легче всего реализовать. Но он, к сожалению, поддерживается лишь в Chrome (эту возможность, к тому же, нужно явным образом включать).
Несмотря на это я хочу начать именно с рассказа о картах импорта, так как уверен в том, что это решение станет в будущем наиболее распространённым. Кроме того, описание работы с картами импорта поможет объяснить и особенности других подходов к решению нашей проблемы.
Использование карт импорта для предотвращения каскадной инвалидации кэша состоит из трёх шагов.
▍Шаг 1
Нужно настроить бандлер так, чтобы он, при сборке проекта, не включал бы хэши содержимого файлов в их имена.
Если собрать проект, модули которого показаны на диаграмме из предыдущего примера, не включая в имена файлов хэши их содержимого, то файлы в выходной директории проекта будут выглядеть так:
dep1.mjs
dep2.mjs
dep3.mjs
main.mjs
vendor.mjsКоманды импорта в соответствующих модулях тоже не будут включать в себя хэши:
import {...} from '/vendor.mjs';▍Шаг 2
Нужно воспользоваться инструментом, наподобие rev-hash, и сгенерировать с его помощью копию каждого файла, к имени которого добавлен хэш, указывающий на версию его содержимого.
После того, как эта часть работы выполнена, содержимое выходной директории должно будет выглядеть примерно так, как показано ниже (обратите внимание на то, что там теперь присутствует по два варианта каждого файла):
dep1-b2c3.mjs",
dep1.mjs
dep2-3c4d.mjs",
dep2.mjs
dep3-d4e5.mjs",
dep3.mjs
main-1a2b.mjs",
main.mjs
vendor-5e6f.mjs",
vendor.mjs▍Шаг 3
Нужно создать JSON-объект, хранящий сведения о соответствии каждого файла, в имени которого нет хэша, каждому файлу, в имени которого хэш есть. Этот объект нужно добавить в HTML-шаблоны.
Этот JSON-объект и является картой импорта. Вот как он может выглядеть:
<script type="importmap">
{
"imports": {
"/main.mjs": "/main-1a2b.mjs",
"/dep1.mjs": "/dep1-b2c3.mjs",
"/dep2.mjs": "/dep2-3c4d.mjs",
"/dep3.mjs": "/dep3-d4e5.mjs",
"/vendor.mjs": "/vendor-5e6f.mjs",
}
}
</script>После этого всякий раз, когда браузер увидит команду импорта файла, находящегося по адресу, соответствующему одному из ключей карты импорта, браузер импортирует тот файл, который соответствует значению ключа.
Если воспользоваться этой картой импорта как примером, то можно выяснить, что команда импорта, ссылающаяся на файл /vendor.mjs, на самом деле выполнит запрос и загрузку файла /vendor-5e6f.mjs:
// Команда ссылается на `/vendor.mjs`, но загружает`/vendor-5e6f.mjs`.
import {...} from '/vendor.mjs';Это означает, что исходный код модулей может совершенно спокойно ссылаться на имена файлов модулей, не содержащих хэшей, а браузер всегда будет загружать файлы, имена которых содержат сведения о версиях их содержимого. А, так как хэшей нет в исходном коде модулей (они присутствуют лишь в карте импорта), то изменения этих хэшей не приведут к инвалидации модулей, отличных от тех, содержимое которых действительно изменилось.
Возможно, вы сейчас задаётесь вопросом о том, почему я создал копию каждого файла вместо того, чтобы просто файлы переименовать. Это нужно для поддержки браузеров, которые не могут работать с картами импорта. В предыдущем примере подобные браузеры увидят лишь файл /vendor.mjs и просто загрузят этот файл, поступив так, как обычно поступают, встречая подобные конструкции. В результате и оказывается, что на сервере должны существовать оба файла.
Если вы хотите увидеть карты импорта в действии, то вот — набор примеров, демонстрирующих все способы решения проблемы каскадной инвалидации кэша, показанные в этом материале. Кроме того, взгляните на конфигурацию сборки проекта, на тот случай, если вам интересно узнать о том, как я генерировал карту импорта и хэши версий для каждого файла.
Продолжение следует…
Уважаемые читатели! Знакома ли вам проблема каскадной инвалидации кэша?
О моем опыте решения проблем инвалидации кэша, и о принципах работы библиотеки cache-dependencies.
При редактировании данных, необходимо удалить также и все кэши, содержащие данные этой модели. Например, при редактировании продукта, который присутствует на закэшированной главной странице компании, требуется инвалидировать и ее кэш тоже. Другой случай, — обновляя данные пользователя (например, фамилию), мы должны также удалить все кэши страниц его постов, на которых присутствуют обновленные данные.
Обычно за инвалидацию кэша отвечает паттерн Observer, или его разновидность — паттерн Multicast. Но даже в этом случае механизмы инвалидации получаются слишком сложными, достигаемая точность слишком низкая, a код обрастает лишним сопряжением и зачастую жертвует своей инкапсуляцией.
И тут на выручку приходит тегирование кэша, т.е. прошивание кэша метками.
Например, кэш главной страницы может быть прошит тегом product.id:635.
А все посты пользователя могут быть прошиты меткой user.id:10.
Коллекции можно кэшировать составным тегом, состоящим из критериев выборки, например type.id:1;category.id:15;region.id:239.
Теперь достаточно инвалидировать метку, чтобы все зависимые кэши автоматически инвалидировались. Эта технология не нова, и активно используется в других языках программирования. Одно время ее даже пытались внедрить в memcached, см. memcached-tag.
Также смотрите:
Возникает вопрос реализации инвалидации зависимых от метки кэшей. Возможны два варианта:
1. При инвалидации метки физически уничтожать все зависимые кэши. Для реализации такого подхода потребуются накладные расходы при создании кэша, чтобы добавить информацию о нем в список (точнее, множество) зависимостей каждой метки (например, используя SADD). Недостаток заключается в том, что инвалидация большого количества зависимых кэшей требует определенного времени.
2. При инвалидации метки просто изменять версию этой метки. Для реализации потребуется добавлять в кэш информацию о версиях меток. При чтении кэша потребуются накладные расходы для сверки версии каждой его метки, и, если версия устарела, то кэш считается недействительным. Достоинство этого подхода заключается в мгновенной инвалидации метки и всех ее зависимых кэшей. Можно не бояться вытеснения из хранилища закэшированной информации о версии метки по LRU принципу, так как метки запрашиваются намного чаще самого кэша.
Я выбрал второй вариант.
Поскольку метки сверяются в момент чтения кэша, давайте представим, что произойдет, если один кэш поглощается другим кэшем. Многоуровневый кэш — не редкость. В таком случае, метки вложенного, дочернего кэша никогда не пройдут сверку, и родительский кэш останется с неактуальными данными. Необходимо явно передать метки родительскому кэшу в момент его создания, что может нарушать принцип инкапсуляции.
Поэтому система кэширования должна автоматически отслеживать связи между вложенными кэшами, и передавать метки от дочернего кэша к родительскому.
При инвалидации кэша параллельный поток может успеть воссоздать кэш с устаревшими данными, прочитанными из slave в перид времени после инвалидации кэша, но до момента обновления slave.
Лучшим решением было бы блокирование создания кэша до момента обновления slave. Но, во-первых, это сопряжено с определенными накладными расходами, а во-вторых, все потоки (в том числе и текущий) продолжают считывать устаревшие данные из slave (если не указано явное чтение из мастера). Поэтому, компромиссным решением может быть просто повторная инвалидация кэша через период времени гарантированного обновления slave.
В своей практике мне приходилось встречать такой подход как регенерация кэша вместо его удаления/инвалидации. Такой подход влечет за собой не совсем эффективное использование памяти кэша (работающего по LRU принципу). К тому же, он не решает проблему сложности инвалидации, и, в данном вопросе, мало чем отличается от обычного удаления кэша по его ключу, возлагая всю сложность на само приложение. Также он таит множество потенциальных баг. Например, он чувствителен к качеству ORM, и если ORM не приводит все атрибуты инстанции модели к нужному типу при сохранении, то в кэш записываются неверные типы данных. Мне приходилось видеть случай, когда атрибут даты записывался к кэш в формате строки, в таком же виде, в каком он пришел от клиента. Хотя он и записывался в БД корректно, но модель не делала приведение типов без дополнительных манипуляций при сохранении (семантическое сопряжение).
Updated on Nov 10, 2016
Добавлено описание реализации блокировки меток.
Предыдущие части:
Многие из нас скорее всего сталкивались с ситуацией, когда диспетчер использует старую версию кода (CSS, HTML, JS). В этой статье я расскажу о правильной конфигурации инвалидации страниц на диспетчере чтобы таких проблем не возникало.
Инвалидация — это механизм для указания устаревших кэшированных ресурсов. Существуют несколько инструментов для автоматической инвалидации и инвалидации вручную. Но сперва давайте установим начальные настройки в секции инвалидации конфигурационного файла диспетчера, затем изучим, как инвалидация происходит на низком уровне, а уже после этого наконец-то вернемся к изучению инструментов для инвалидации.
Начальные настройки секции инвалидации
Внутри секции /cache находится блок /invalidate, который устанавливает кэшированные файлы, доступные для автоматической инвалидации при обновлении контента. Например, следующие настройки устанавливают инвалидацию всех HTML страниц:
/cache
{
/invalidate
{
/0000 { /glob "*" /type "deny" }
/0001 { /glob "*.html" /type "allow" }
}
}
При автоматической инвалидации диспетчер не удаляет кэшированные файлы сразу после обновления контента, а проверяет их валидность при ближайшем запросе. Кэшированные документы, которые не инвалидируются автоматически, останутся в кэше до тех пор, пока в процессе обновления контента не будут удалены явно. В демонстрационных целях давайте позволим автоматическую инвалидацию для всего кэша:
/cache
{
/invalidate
{
/0000 { /glob "*" /type "allow" }
}
}
Перезапустите httpd-сервер после обновления секции /invalidate для применения новых изменений.
Инвалидация в подробностях
На низком уровне диспетчер использует специальные пустые стат-файлы с именем по умолчанию «.stat». По умолчанию установлен параметр /statfileslevel «0», что подразумевает использование только одного стат-файла, располагающегося в корне папки htdocs. Если время изменения стат-файла более позднее, чем время изменения ресурса, тогда диспетчер расценивает такой ресурс устаревшим или невалидным.
Например, пусть у нас есть следующие кэшированные ресурсы после запроса страницы http://localhost/content/geometrixx/en/products.html :

Давайте инвалидируем их, применяя низкоуровневый механизм стат-файлов. Создайте пустой файл с именем «.stat» в корне вашей папки htdocs:
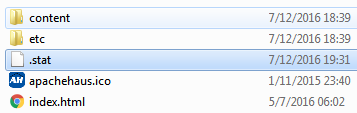
Обратите внимание, что время изменения стат-файла более позднее, чем кэшированных ресурсов. Для диспетчера это означает, что все ресурсы устаревшие. Это и есть низкоуровневый механизм инвалидации. Если мы после создания такого стат-файла снова посетим страницу http://localhost/content/geometrixx/en/products.html, то запрашиваемые кэшированные ресурсы будут обновлены:

Этот пример иллюстрирует схему инвалидации с параметром по умолчанию /statfileslevel «0». Давайте разберёмся, как мы можем настроить инвалидацию более тонко и детально при помощи параметра /statfileslevel.
Настройка параметра /statfileslevel
Вы можете пользоваться свойством /statfileslevel в конфигурационном файле диспетчера для выборочной инвалидации кэшированных файлов соответственно их путям. У механизма работы свойства /statfileslevel есть несколько правил:
- Диспетчер создаёт .stat файлы в каждой папке начиная от docroot и до уровня, который вы указываете. Уровень папки docroot равен 0.
- При обновлении файла диспетчер по пути файла находит папку, лежащую на уровне statfileslevel и инвалидирует все файлы этой папки и все файлы, лежащие ниже внутри этой папки.
- Если уровень обновлённого файла меньше уровня statfileslevel, тогда инвалидируются только файлы папки, содержащей обновлённый файл, но файлы, лежащие ниже внутри этой папки остаются валидными.
- При обновления файла все файлы соответствующей папки и выше вплоть до корневого уровня включительно станут невалидными.
Для лучшего понимания правил свойства /statfileslevel давайте рассмотрим парочку примеров. Наш демонстрационный случай по умолчанию, в котором /statfileslevel «0», выглядит следующим образом:
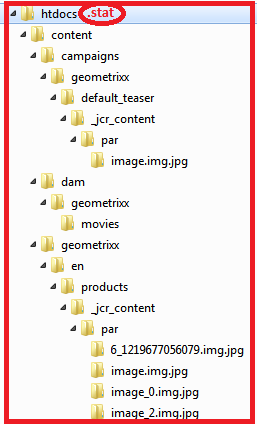
Есть только один стат-файл в корневой папке docroot. А область ответственности или зона охвата этого стат-файла будет целиком всё файловое дерево нашего docroot. Если у какого-то файла дерева дата изменения старше даты изменения стат-файла, тогда диспетчер расценивает такой файл невалидным.
Если мы установим /statfileslevel «4», тогда инвалидация работает уже вот так:
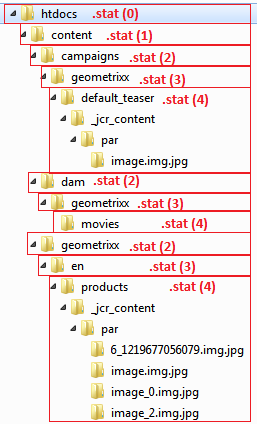
Стат-файлы есть на всех уровнях начиная от 0 (корень) до 4 включительно.
Стат-файл на уровне меньше 4 обладает областью ответственности или зоной охвата только содержащей его папки. Это означает, что если стат-файл внутри папки content/geometrixx/en новее, чем какой-то файл из этой папки, то такой файл является невалидным, но валидация всех файлов из остальных папок определяется другими стат-файлами.
Только стат-файлы, лежащие на уровне со значением statfileslevel (в нашем случае уровень равен 4), обладают областью ответственности или зоной охвата всего нижележащего дерева, начинающего от папки, содержащей такой стат-файл и простирающегося вниз до более низких уровней файлового дерева. Это означает, что если у стат-файла внутри папки content/geometrixx/en/products время изменения новее, чем у какого-то файла из нижележащего файлового дерева, включающего папку products, тогда диспетчер считает такой файл невалидным. Валидация всех файлов, которые не находятся в этом дереве, определяется другими стат-файлами.
Автоматическая инвалидация и flush-агенты
В целях автоматизации инвалидации вы можете включить авторские или публичные flush-агенты. Рекомендуется пользоваться публичным flush-агентом для более надёжной автоматической инвалидации, потому что использование авторского flush-агента может вызывать следующие проблемы:
- Диспетчер должен быть доступен для авторского AEM-сервера. Если ваша сеть (например, из-за файрвола) настроена так, что доступ между обоими закрыт, тогда автоматическая инвалидация работать не будет.
- Публикация и инвалидация кэша происходит одновременно. Пользователь может запросить страницу сразу после того, как она была удалена из кэша, но ещё до того, как страница была опубликована. В такой ситуации AEM возвращает старую страницу, а диспетчер эту старую страницу кэширует снова и считает её теперь валидной. Эта проблема больше касается крупных сайтов.
Публичный flush-агент находится по адресу http://localhost:4503/etc/replication/agents.publish/flush.html
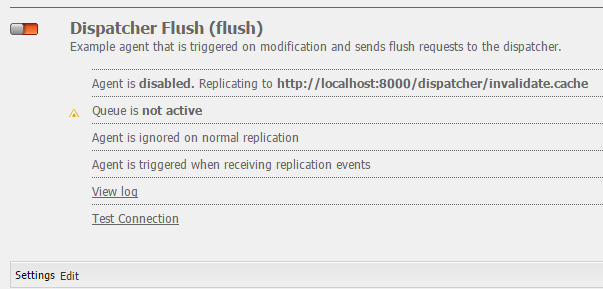
Для включения публичного flush-агента нажмите кнопку «Edit» и установите галочку в чекбоксе «Enabled»:
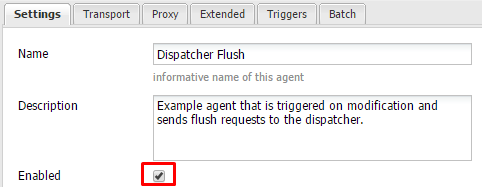
Также обновите URI порт на вкладке Transport и установите его значение равным 80:

Сохраните ваши изменения, и вы увидите, что публичный flush-агент активировался:

Запросы для инвалидации вручную
Вы можете отправлять следующие запросы для того, чтобы вручную инвалидировать ваши кэшированные ресурсы:
- для удаления кэшированных файлов
POST /dispatcher/invalidate.cache HTTP/1.1 CQ-Action: Activate CQ-Handle: path-pattern Content-Length: 0 - для удаления и перекэширования файлов
POST /dispatcher/invalidate.cache HTTP/1.1 CQ-Action: Activate Content-Type: text/plain CQ-Handle: path-pattern Content-Length: numchars in bodypage_path0 Page_path2 … Page_pathn
Резюме
В итоге мы узнали, как работают механизм инвалидации на низком уровне, flush-агенты для автоматической инвалидации после публикации страниц и запросы для инвалидации вручную.
Подробная и полезная документация доступна на следующих страницах:
Автор: Виталий Киселев, AEM Разработчик
Культура стыда и инвалидация
В прошлом году, на первом в моей жизни обучающем курсе по психотерапии с ведущими-иностранцами, я обратила внимание на манеру преподавания, которая существенно отличалась от той, с которой мы здесь все регулярно встречаемся.
Первое, что казалось диким и неправильным — это то, что ведущие говорили участникам семинара о том, что у нас получается. Отмечали успехи. Говорили — «Слушай, вот это было круто». «Вот тут у тебя здорово получилось». «Мне очень понравилось, как ты это сделал». Такой способ вызвал у участников много тревоги. Под конец один не выдержал, и таки выдал ведущему текст примерно следующего содержания: «Почему ты все время говоришь, что у нас получилось хорошо? Я тебе не верю! Скажи, что мы делаем плохо, это будет по-честному».
По правде сказать, я тому моменты тоже начала напрягаться, — не может же быть все хорошо. Ну не может!
Ведущий же, в свою очередь, по-настоящему растерялся, ушел думать, и вернулся после перерыва с объяснениями, почему он так работает, что работать иначе он не умеет, что он так не только преподает, но и воспитывает своих детей. Но было видно, что он очень удивлен.
Второе, что бросалось в глаза, хоть и не так резко, это манера ведущих говорить о трудностях, сопровождающих процесс обучения. Говорить «Это нормально, если вам кажется, что у вас не получается». «Мне тоже было трудно в самом начале». «Это действительно непростой навык».
Все эти нетипичные способы разговаривать со студентами мне пришлось долго “переваривать”.
Спустя год, после начала второго обучающего курса, я стала догадываться о некой культурной разнице между нами, которая, кроме всего прочего, заключается в глубоко укорененном способе обучать/воспитывать через стыжение. И речь не только об обучении в образовательных заведениях, речь о более глубоком процессе, который начинается внутри семьи и не прекращается, похоже, никогда. По-крайне мере, если не уделять этому внимание сознательно.
В диалектической поведенческой терапии есть понятие invalidation — это способ воспитания, при котором реальные чувства и потребности ребенка игнорируются, называются стыдными, лишними, ненужными. Когда ребенок хронически получает послание «ты не имеешь права этого хотеть», «ты не можешь злиться», «то, что ты сейчас испытываешь — неправильно и не должно происходить». Иногда кажется, что этим пропитан воздух, если быть внимательным к процессам, оказывается, мы продолжаем жить в инвалидирующем окружении. Уставшая, отчаявшаяся и обозленная на все мама младенца слышит «Ну что, ты, он же маленький, на него нельзя злиться». Ребенок, приходящий в поликлинику на осмотр к стоматологу, слышит «Это совсем не больно, не выдумывай». Взрослый, испытывающий трудности в отношениях партнером, и пытающийся поделиться этим с кем-то близким, легко может услышать «Да, ну встань на его место. Его можно понять».
В чем проблема инвалидации? В том, что человек, со своей растерянностью, злостью, непониманием, страхом игнорируется. Сообщение, которое он получает, продолжает оставаться все тем же — «Это совершенно неважно, что ты чувствуешь. Чувствовать это стыдно. Прекрати немедленно». Не знаю, есть ли что-то более запутывающего понимание себя и других людей, чем инвалидация. И что-то, настолько мешающее жить. При неблагоприятном раскладе хроническая инвалидация приводит к очень сильной внутренней спутанности, и формированию пограничного расстройства личности. При благоприятном (если это можно так назвать) — человек просто живет, мучаясь вопросами про свою «нормальность», «адекватность», «правильность». Особенно, когда он делает или чувствует что-то, что не принимается, или не принималось раньше, его окружением.
И да, валидация, в моем понимании, является основной питающей силой в психотерапии и близких отношениях. В ситуации хронического дефицита, нет ничего более ценного, чем быть услышанным и услышать в ответ что-то вроде
«Твои переживания нормальны».
«Я могу тебя понять».
«Конечно, тебе страшно».
«Могу только представить себе, как это неприятно».
Иногда и этого оказывается достаточно.
ОЛЬГА СУШКО
invalidation — это… Что такое invalidation?
invalidation — [ ɛ̃validasjɔ̃ ] n. f. • 1636; de invalider ♦ Dr. Action d invalider. Invalidation d un acte, d un contrat. Spécialt, cour. Invalidation d une élection. ⇒ annulation. Par ext. Invalidation d un député. ⊗ CONTR. Validation. ● invalidation nom… … Encyclopédie Universelle
Invalidation — In*val i*da tion, n. The act of inavlidating, or the state of being invalidated. [1913 Webster] So many invalidations of their right. Burke. [1913 Webster] … The Collaborative International Dictionary of English
invalidation — index abatement (extinguishment), abolition, ademption, annulment, avoidance (cancellation), cancellation … Law dictionary
invalidation — (n.) 1771, noun of action from INVALIDATE (Cf. invalidate) (v.) … Etymology dictionary
invalidation — invalidate in‧val‧i‧date [ɪnˈvældeɪt] verb [transitive] LAW to make a contract, agreement, document etc invalid: • Failure to follow the instructions correctly could invalidate the guarantee. • The Judge s ruling invalidated the company s patent … Financial and business terms
INVALIDATION — n. f. Action d’invalider. L’invalidation d’un acte, d’une élection … Dictionnaire de l’Academie Francaise, 8eme edition (1935)
Invalidation — In|va|li|da|ti|on, die; , en [frz. invalidation] (veraltet): Ungültigmachung … Universal-Lexikon
invalidation — (in va li da sion) s. f. Action d invalider. HISTORIQUE XVIe s. • Invalidation, OUDIN Dict.. ÉTYMOLOGIE Invalider ; ital. invalidazione … Dictionnaire de la Langue Française d’Émile Littré
Invalidation — In|va|li|da|ti|on die; , en <aus gleichbed. fr. invalidation zu invalide, vgl. ↑invalid> (veraltet) Ungültigmachung … Das große Fremdwörterbuch
invalidation — atšaukimas statusas T sritis radioelektronika atitikmenys: angl. cancellation; cancelling vok. Abwischen, n; Anulierung, f; Aufheben, n rus. аннулирование, n; отмена, f pranc. invalidation, f … Radioelektronikos terminų žodynas
invalidation — Ⅰ. invalid [1] ► NOUN ▪ a person made weak or disabled by illness or injury. ► VERB (invalided, invaliding) (usu. be invalided) ▪ remove from active service in the armed forces because of injury or illness. DERIVATIVES … English terms dictionary
Согласно Всемирной организации здравоохранения, инвалидность имеет три измерения: 1
- Насстройство в строении тела человека или функция или психическое функционирование; Примеры нарушений включают потерю конечности, потерю зрения или потерю памяти.
- Ограничение деятельности, например, проблемы со зрением, слухом, ходьбой или решение проблем.
- Ограничения на участие в обычной повседневной деятельности, такой как работа, участие в социальных и развлекательных мероприятиях и получение медицинских и профилактических услуг.
Отключение может быть:
- Относится к состояниям, которые присутствуют при рождении и могут влиять на функции в более позднем возрасте, включая познание (память, обучение и понимание), мобильность (передвижение в окружающей среде), зрение, слух, поведение и другие области. Эти условия могут быть
- Связывается с условиями развития, которые проявляются в детстве (например, расстройства аутистического спектра и синдром дефицита внимания / гиперактивности или СДВГ)
- Относится к травме (например, черепно-мозговая травма или травма спинного мозга, внешняя иконка).2 Например, проблемы со структурой мозга могут привести к проблемам с умственными функциями, или проблемы со структурой глаз или ушей могут привести к проблемам с функциями зрения или слуха.
- Структурные нарушения представляют собой значительные проблемы с внутренним или внешним компонентом тела. Примеры этого включают тип повреждения нерва, которое может привести к множественному склерозисексуальному значку или полной потере компонента тела, например, когда ампутирована конечность.
- Функциональные нарушения включают полную или частичную потерю функции части тела. Примеры этого включают боль, которая не проходит, или суставы, которые больше не двигаются легко.
В чем разница между ограничением активности и ограничением участия?
В 2001 году Всемирная организация здравоохранения (ВОЗ) опубликовала Международную классификацию функционирования, инвалидности и здоровья (МКФ). МКФ обеспечивает стандартный язык для классификации функций и структуры тела, активности, уровней участия и условий в окружающем нас мире, которые влияют на здоровье.Это описание помогает оценить состояние здоровья, функционирование, деятельность и факторы окружающей среды, которые либо помогают, либо создают препятствия для полноценного участия людей в жизни общества.
Согласно ICF:
- Activity — это выполнение задачи или действия отдельным лицом.
- Participation — это вовлеченность человека в жизненную ситуацию.
ICF признает, что различие между этими двумя категориями несколько неясно, и объединяет их, хотя в основном действия происходят на личном уровне, а участие включает участие в жизненных ролях, таких как занятость, образование или отношения.Ограничения активности и ограничения участия связаны с трудностями, с которыми сталкивается человек при выполнении задач и выполнении социальных ролей. Деятельность и участие могут быть облегчены или усложнены в результате таких факторов окружающей среды, как технологии, поддержка и отношения, услуги, политика или убеждения других лиц.
ФК включает в категории следующие виды деятельности и участия:
- Изучение и применение знаний
- Управление задачами и требованиями
- Мобильность (перемещение и поддержание положения тела, перемещение и перемещение объектов, перемещение в окружающей среде, перемещение с использованием транспорта)
- Управление задачами самообслуживания
- Управление семейной жизнью
- Создание и управление межличностными отношениями и взаимодействиями
- Участие в основных сферах жизни (образование, занятость, управление деньгами или финансами)
- Участие в общественной, социальной и гражданской жизни
Это очень важно для улучшения условий в общинах путем предоставления условий, которые уменьшают или устраняют ограничения активности и ограничения участия для людей с ограниченными возможностями, чтобы они могли участвовать в ролях и действиях повседневной жизни.